 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCustomized Nonlinear Bandits for Online Response Selection in Neural Conversation Models
Paper and Code
Nov 22, 2017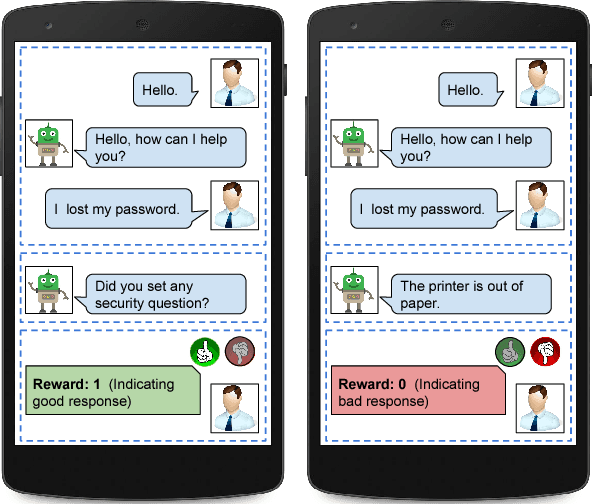

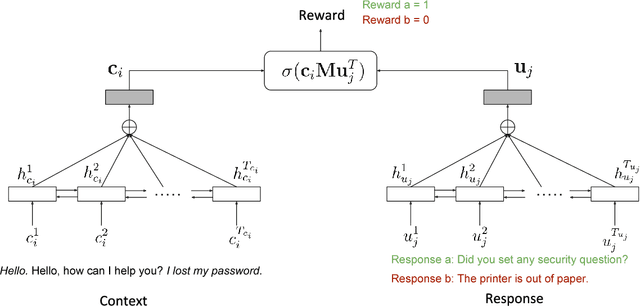

Dialog response selection is an important step towards natural response generation in conversational agents. Existing work on neural conversational models mainly focuses on offline supervised learning using a large set of context-response pairs. In this paper, we focus on online learning of response selection in retrieval-based dialog systems. We propose a contextual multi-armed bandit model with a nonlinear reward function that uses distributed representation of text for online response selection. A bidirectional LSTM is used to produce the distributed representations of dialog context and responses, which serve as the input to a contextual bandit. In learning the bandit, we propose a customized Thompson sampling method that is applied to a polynomial feature space in approximating the reward. Experimental results on the Ubuntu Dialogue Corpus demonstrate significant performance gains of the proposed method over conventional linear contextual bandits. Moreover, we report encouraging response selection performance of the proposed neural bandit model using the Recall@k metric for a small set of online training samples.