 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptFlow: Adaptive Workflow Optimization via Meta-Learning
Aug 11, 2025Recent advances in large language models (LLMs) have sparked growing interest in agentic workflows, which are structured sequences of LLM invocations intended to solve complex tasks. However, existing approaches often rely on static templates or manually designed workflows, which limit adaptability to diverse tasks and hinder scalability. We propose AdaptFlow, a natural language-based meta-learning framework inspired by model-agnostic meta-learning (MAML). AdaptFlow learns a generalizable workflow initialization that enables rapid subtask-level adaptation. It employs a bi-level optimization scheme: the inner loop refines the workflow for a specific subtask using LLM-generated feedback, while the outer loop updates the shared initialization to perform well across tasks. This setup allows AdaptFlow to generalize effectively to unseen tasks by adapting the initialized workflow through language-guided modifications. Evaluated across question answering, code generation, and mathematical reasoning benchmarks, AdaptFlow consistently outperforms both manually crafted and automatically searched baselines, achieving state-of-the-art results with strong generalization across tasks and models. The source code and data are available at https://github.com/microsoft/DKI_LLM/tree/AdaptFlow/AdaptFlow.
EL4NER: Ensemble Learning for Named Entity Recognition via Multiple Small-Parameter Large Language Models
May 29, 2025In-Context Learning (ICL) technique based on Large Language Models (LLMs) has gained prominence in Named Entity Recognition (NER) tasks for its lower computing resource consumption, less manual labeling overhead, and stronger generalizability. Nevertheless, most ICL-based NER methods depend on large-parameter LLMs: the open-source models demand substantial computational resources for deployment and inference, while the closed-source ones incur high API costs, raise data-privacy concerns, and hinder community collaboration. To address this question, we propose an Ensemble Learning Method for Named Entity Recognition (EL4NER), which aims at aggregating the ICL outputs of multiple open-source, small-parameter LLMs to enhance overall performance in NER tasks at less deployment and inference cost. Specifically, our method comprises three key components. First, we design a task decomposition-based pipeline that facilitates deep, multi-stage ensemble learning. Second, we introduce a novel span-level sentence similarity algorithm to establish an ICL demonstration retrieval mechanism better suited for NER tasks. Third, we incorporate a self-validation mechanism to mitigate the noise introduced during the ensemble process. We evaluated EL4NER on multiple widely adopted NER datasets from diverse domains. Our experimental results indicate that EL4NER surpasses most closed-source, large-parameter LLM-based methods at a lower parameter cost and even attains state-of-the-art (SOTA) performance among ICL-based methods on certain datasets. These results show the parameter efficiency of EL4NER and underscore the feasibility of employing open-source, small-parameter LLMs within the ICL paradigm for NER tasks.
Evaluating Large Language Model with Knowledge Oriented Language Specific Simple Question Answering
May 22, 2025



We introduce KoLasSimpleQA, the first benchmark evaluating the multilingual factual ability of Large Language Models (LLMs). Inspired by existing research, we created the question set with features such as single knowledge point coverage, absolute objectivity, unique answers, and temporal stability. These questions enable efficient evaluation using the LLM-as-judge paradigm, testing both the LLMs' factual memory and self-awareness ("know what they don't know"). KoLasSimpleQA expands existing research in two key dimensions: (1) Breadth (Multilingual Coverage): It includes 9 languages, supporting global applicability evaluation. (2) Depth (Dual Domain Design): It covers both the general domain (global facts) and the language-specific domain (such as history, culture, and regional traditions) for a comprehensive assessment of multilingual capabilities. We evaluated mainstream LLMs, including traditional LLM and emerging Large Reasoning Models. Results show significant performance differences between the two domains, particularly in performance metrics, ranking, calibration, and robustness. This highlights the need for targeted evaluation and optimization in multilingual contexts. We hope KoLasSimpleQA will help the research community better identify LLM capability boundaries in multilingual contexts and provide guidance for model optimization. We will release KoLasSimpleQA at https://github.com/opendatalab/KoLasSimpleQA .
Retrieval Dexterity: Efficient Object Retrieval in Clutters with Dexterous Hand
Feb 26, 2025Retrieving objects buried beneath multiple objects is not only challenging but also time-consuming. Performing manipulation in such environments presents significant difficulty due to complex contact relationships. Existing methods typically address this task by sequentially grasping and removing each occluding object, resulting in lengthy execution times and requiring impractical grasping capabilities for every occluding object. In this paper, we present a dexterous arm-hand system for efficient object retrieval in multi-object stacked environments. Our approach leverages large-scale parallel reinforcement learning within diverse and carefully designed cluttered environments to train policies. These policies demonstrate emergent manipulation skills (e.g., pushing, stirring, and poking) that efficiently clear occluding objects to expose sufficient surface area of the target object. We conduct extensive evaluations across a set of over 10 household objects in diverse clutter configurations, demonstrating superior retrieval performance and efficiency for both trained and unseen objects. Furthermore, we successfully transfer the learned policies to a real-world dexterous multi-fingered robot system, validating their practical applicability in real-world scenarios. Videos can be found on our project website https://ChangWinde.github.io/RetrDex.
GRAIT: Gradient-Driven Refusal-Aware Instruction Tuning for Effective Hallucination Mitigation
Feb 09, 2025Refusal-Aware Instruction Tuning (RAIT) aims to enhance Large Language Models (LLMs) by improving their ability to refuse responses to questions beyond their knowledge, thereby reducing hallucinations and improving reliability. Effective RAIT must address two key challenges: firstly, effectively reject unknown questions to minimize hallucinations; secondly, avoid over-refusal to ensure questions that can be correctly answered are not rejected, thereby maintain the helpfulness of LLM outputs. In this paper, we address the two challenges by deriving insightful observations from the gradient-based perspective, and proposing the Gradient-driven Refusal Aware Instruction Tuning Framework GRAIT: (1) employs gradient-driven sample selection to effectively minimize hallucinations and (2) introduces an adaptive weighting mechanism during fine-tuning to reduce the risk of over-refusal, achieving the balance between accurate refusals and maintaining useful responses. Experimental evaluations on open-ended and multiple-choice question answering tasks demonstrate that GRAIT significantly outperforms existing RAIT methods in the overall performance. The source code and data will be available at https://github.com/opendatalab/GRAIT .
Parenting: Optimizing Knowledge Selection of Retrieval-Augmented Language Models with Parameter Decoupling and Tailored Tuning
Oct 14, 2024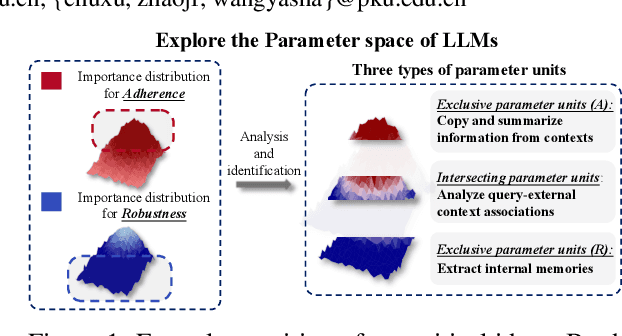
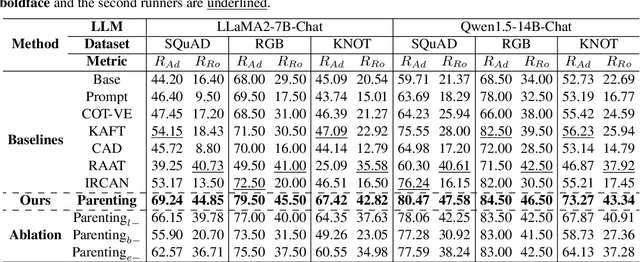
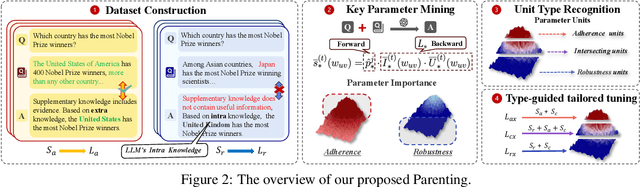
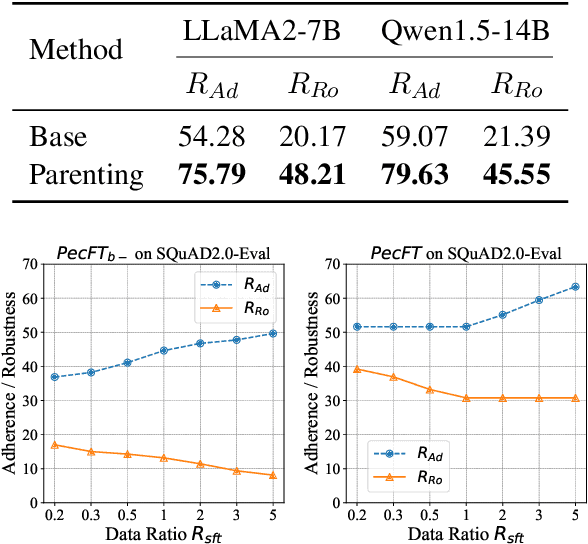
Retrieval-Augmented Generation (RAG) offers an effective solution to the issues faced by Large Language Models (LLMs) in hallucination generation and knowledge obsolescence by incorporating externally retrieved knowledge. However, due to potential conflicts between internal and external knowledge, as well as retrieval noise, LLMs often struggle to effectively integrate external evidence, leading to a decline in performance. Although existing methods attempt to tackle these challenges, they often struggle to strike a balance between model adherence and robustness, resulting in significant learning variance. Inspired by human cognitive processes, we propose Parenting, a novel framework that decouples adherence and robustness within the parameter space of LLMs. Specifically, Parenting utilizes a key parameter mining method based on forward activation gain to identify and isolate the crucial parameter units that are strongly linked to adherence and robustness. Then, Parenting employs a type-guided tailored tuning strategy, applying specific and appropriate fine-tuning methods to parameter units representing different capabilities, aiming to achieve a balanced enhancement of adherence and robustness. Extensive experiments on various datasets and models validate the effectiveness and generalizability of our methods.
3DS: Decomposed Difficulty Data Selection's Case Study on LLM Medical Domain Adaptation
Oct 13, 2024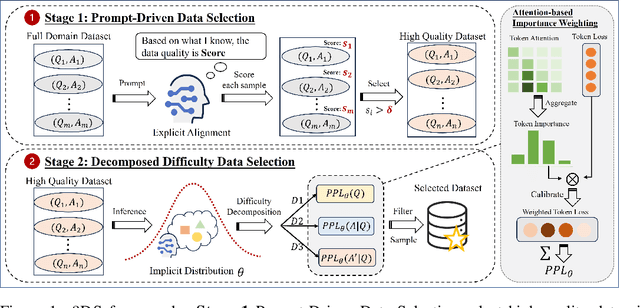
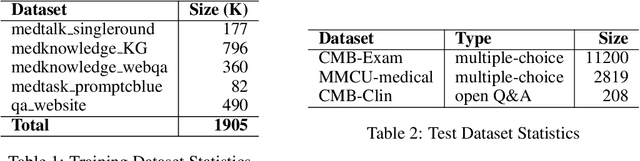
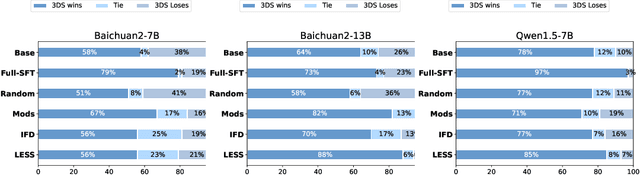
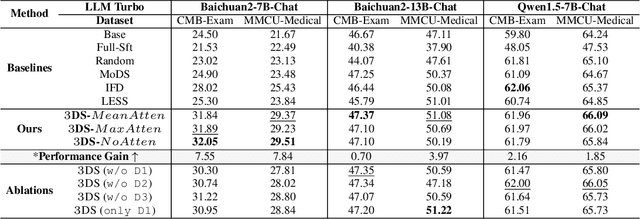
Large Language Models(LLMs) excel in general tasks but struggle in specialized domains like healthcare due to limited domain-specific knowledge.Supervised Fine-Tuning(SFT) data construction for domain adaptation often relies on heuristic methods, such as GPT-4 annotation or manual data selection, with a data-centric focus on presumed diverse, high-quality datasets. However, these methods overlook the model's inherent knowledge distribution, introducing noise, redundancy, and irrelevant data, leading to a mismatch between the selected data and the model's learning task, resulting in suboptimal performance. To address this, we propose a two-stage model-centric data selection framework, Decomposed Difficulty Data Selection (3DS), which aligns data with the model's knowledge distribution for optimized adaptation. In Stage1, we apply Prompt-Driven Data Selection via Explicit Alignment, where the the model filters irrelevant or redundant data based on its internal knowledge. In Stage2, we perform Decomposed Difficulty Data Selection, where data selection is guided by our defined difficulty decomposition, using three metrics: Instruction Understanding, Response Confidence, and Response Correctness. Additionally, an attention-based importance weighting mechanism captures token importance for more accurate difficulty calibration. This two-stage approach ensures the selected data is not only aligned with the model's knowledge and preferences but also appropriately challenging for the model to learn, leading to more effective and targeted domain adaptation. In the case study of the medical domain, our extensive experiments on real-world healthcare datasets demonstrate the superiority of 3DS over exisiting methods in accuracy by over 5.29%. Our dataset and code will be open-sourced at https://anonymous.4open.science/r/3DS-E67F.
Utilize the Flow before Stepping into the Same River Twice: Certainty Represented Knowledge Flow for Refusal-Aware Instruction Tuning
Oct 09, 2024



Refusal-Aware Instruction Tuning (RAIT) enables Large Language Models (LLMs) to refuse to answer unknown questions. By modifying responses of unknown questions in the training data to refusal responses such as "I don't know", RAIT enhances the reliability of LLMs and reduces their hallucination. Generally, RAIT modifies training samples based on the correctness of the initial LLM's response. However, this crude approach can cause LLMs to excessively refuse answering questions they could have correctly answered, the problem we call over-refusal. In this paper, we explore two primary causes of over-refusal: Static conflict emerges when the RAIT data is constructed solely on correctness criteria, causing similar samples in the LLM's feature space to be assigned different labels (original vs. modified "I don't know"). Dynamic conflict occurs due to the changes of LLM's knowledge state during fine-tuning, which transforms previous unknown questions into knowns, while the training data, which is constructed based on the initial LLM, remains unchanged. These conflicts cause the trained LLM to misclassify known questions as unknown, resulting in over-refusal. To address this issue, we introduce Certainty Represented Knowledge Flow for Refusal-Aware Instructions Construction (CRaFT). CRaFT centers on two main contributions: First, we additionally incorporate response certainty to selectively filter and modify data, reducing static conflicts. Second, we implement preliminary rehearsal training to characterize changes in the LLM's knowledge state, which helps mitigate dynamic conflicts during the fine-tuning process. We conducted extensive experiments on open-ended question answering and multiple-choice question task. Experiment results show that CRaFT can improve LLM's overall performance during the RAIT process. Source code and training data will be released at Github.
KnowPO: Knowledge-aware Preference Optimization for Controllable Knowledge Selection in Retrieval-Augmented Language Models
Aug 19, 2024

By integrating external knowledge, Retrieval-Augmented Generation (RAG) has become an effective strategy for mitigating the hallucination problems that large language models (LLMs) encounter when dealing with knowledge-intensive tasks. However, in the process of integrating external non-parametric supporting evidence with internal parametric knowledge, inevitable knowledge conflicts may arise, leading to confusion in the model's responses. To enhance the knowledge selection of LLMs in various contexts, some research has focused on refining their behavior patterns through instruction-tuning. Nonetheless, due to the absence of explicit negative signals and comparative objectives, models fine-tuned in this manner may still exhibit undesirable behaviors such as contextual ignorance and contextual overinclusion. To this end, we propose a Knowledge-aware Preference Optimization strategy, dubbed KnowPO, aimed at achieving adaptive knowledge selection based on contextual relevance in real retrieval scenarios. Concretely, we proposed a general paradigm for constructing knowledge conflict datasets, which comprehensively cover various error types and learn how to avoid these negative signals through preference optimization methods. Simultaneously, we proposed a rewriting strategy and data ratio optimization strategy to address preference imbalances. Experimental results show that KnowPO outperforms previous methods for handling knowledge conflicts by over 37\%, while also exhibiting robust generalization across various out-of-distribution datasets.
KaPO: Knowledge-aware Preference Optimization for Controllable Knowledge Selection in Retrieval-Augmented Language Models
Aug 06, 2024By integrating external knowledge, Retrieval-Augmented Generation (RAG) has become an effective strategy for mitigating the hallucination problems that large language models (LLMs) encounter when dealing with knowledge-intensive tasks. However, in the process of integrating external non-parametric supporting evidence with internal parametric knowledge, inevitable knowledge conflicts may arise, leading to confusion in the model's responses. To enhance the knowledge selection of LLMs in various contexts, some research has focused on refining their behavior patterns through instruction-tuning. Nonetheless, due to the absence of explicit negative signals and comparative objectives, models fine-tuned in this manner may still exhibit undesirable behaviors in the intricate and realistic retrieval scenarios. To this end, we propose a Knowledge-aware Preference Optimization, dubbed KaPO, aimed at achieving controllable knowledge selection in real retrieval scenarios. Concretely, we explore and simulate error types across diverse context combinations and learn how to avoid these negative signals through preference optimization methods. Simultaneously, by adjusting the balance between response length and the proportion of preference data representing different behavior patterns, we enhance the adherence capabilities and noise robustness of LLMs in a balanced manner. Experimental results show that KaPO outperforms previous methods for handling knowledge conflicts by over 37%, while also exhibiting robust generalization across various out-of-distribution datasets.