 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3DS: Decomposed Difficulty Data Selection's Case Study on LLM Medical Domain Adaptation
Paper and Code
Oct 13, 2024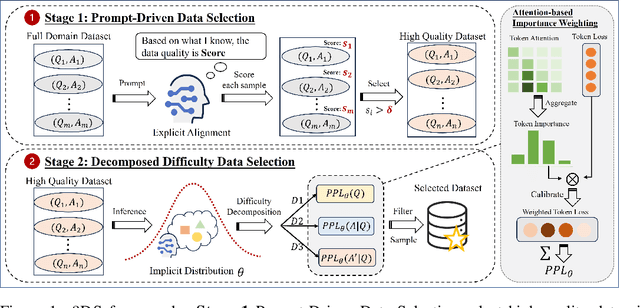
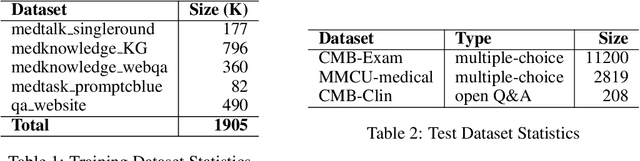
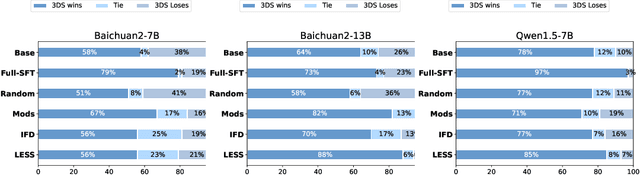
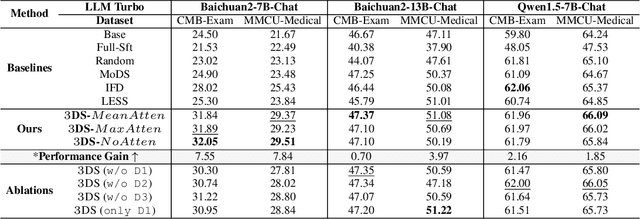
Large Language Models(LLMs) excel in general tasks but struggle in specialized domains like healthcare due to limited domain-specific knowledge.Supervised Fine-Tuning(SFT) data construction for domain adaptation often relies on heuristic methods, such as GPT-4 annotation or manual data selection, with a data-centric focus on presumed diverse, high-quality datasets. However, these methods overlook the model's inherent knowledge distribution, introducing noise, redundancy, and irrelevant data, leading to a mismatch between the selected data and the model's learning task, resulting in suboptimal performance. To address this, we propose a two-stage model-centric data selection framework, Decomposed Difficulty Data Selection (3DS), which aligns data with the model's knowledge distribution for optimized adaptation. In Stage1, we apply Prompt-Driven Data Selection via Explicit Alignment, where the the model filters irrelevant or redundant data based on its internal knowledge. In Stage2, we perform Decomposed Difficulty Data Selection, where data selection is guided by our defined difficulty decomposition, using three metrics: Instruction Understanding, Response Confidence, and Response Correctness. Additionally, an attention-based importance weighting mechanism captures token importance for more accurate difficulty calibration. This two-stage approach ensures the selected data is not only aligned with the model's knowledge and preferences but also appropriately challenging for the model to learn, leading to more effective and targeted domain adaptation. In the case study of the medical domain, our extensive experiments on real-world healthcare datasets demonstrate the superiority of 3DS over exisiting methods in accuracy by over 5.29%. Our dataset and code will be open-sourced at https://anonymous.4open.science/r/3DS-E67F.