 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAstra: Toward General-Purpose Mobile Robots via Hierarchical Multimodal Learning
Jun 06, 2025Modern robot navigation systems encounter difficulties in diverse and complex indoor environments. Traditional approaches rely on multiple modules with small models or rule-based systems and thus lack adaptability to new environments. To address this, we developed Astra, a comprehensive dual-model architecture, Astra-Global and Astra-Local, for mobile robot navigation. Astra-Global, a multimodal LLM, processes vision and language inputs to perform self and goal localization using a hybrid topological-semantic graph as the global map, and outperforms traditional visual place recognition methods. Astra-Local, a multitask network, handles local path planning and odometry estimation. Its 4D spatial-temporal encoder, trained through self-supervised learning, generates robust 4D features for downstream tasks. The planning head utilizes flow matching and a novel masked ESDF loss to minimize collision risks for generating local trajectories, and the odometry head integrates multi-sensor inputs via a transformer encoder to predict the relative pose of the robot. Deployed on real in-house mobile robots, Astra achieves high end-to-end mission success rate across diverse indoor environments.
3DS: Decomposed Difficulty Data Selection's Case Study on LLM Medical Domain Adaptation
Oct 13, 2024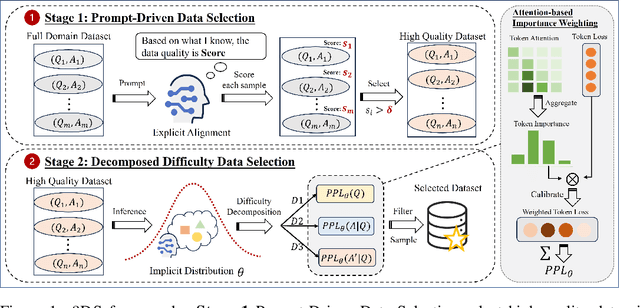
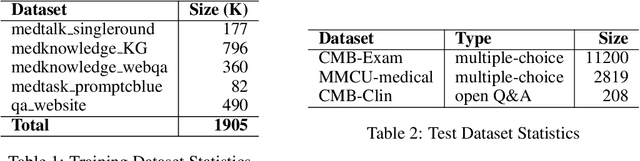
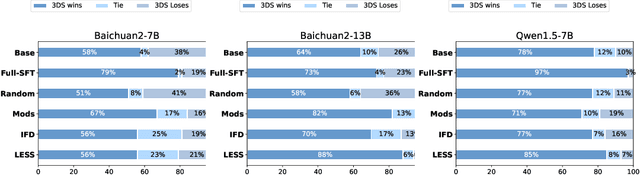
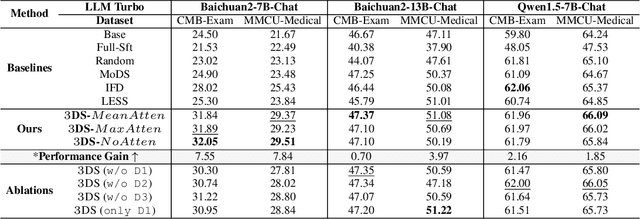
Large Language Models(LLMs) excel in general tasks but struggle in specialized domains like healthcare due to limited domain-specific knowledge.Supervised Fine-Tuning(SFT) data construction for domain adaptation often relies on heuristic methods, such as GPT-4 annotation or manual data selection, with a data-centric focus on presumed diverse, high-quality datasets. However, these methods overlook the model's inherent knowledge distribution, introducing noise, redundancy, and irrelevant data, leading to a mismatch between the selected data and the model's learning task, resulting in suboptimal performance. To address this, we propose a two-stage model-centric data selection framework, Decomposed Difficulty Data Selection (3DS), which aligns data with the model's knowledge distribution for optimized adaptation. In Stage1, we apply Prompt-Driven Data Selection via Explicit Alignment, where the the model filters irrelevant or redundant data based on its internal knowledge. In Stage2, we perform Decomposed Difficulty Data Selection, where data selection is guided by our defined difficulty decomposition, using three metrics: Instruction Understanding, Response Confidence, and Response Correctness. Additionally, an attention-based importance weighting mechanism captures token importance for more accurate difficulty calibration. This two-stage approach ensures the selected data is not only aligned with the model's knowledge and preferences but also appropriately challenging for the model to learn, leading to more effective and targeted domain adaptation. In the case study of the medical domain, our extensive experiments on real-world healthcare datasets demonstrate the superiority of 3DS over exisiting methods in accuracy by over 5.29%. Our dataset and code will be open-sourced at https://anonymous.4open.science/r/3DS-E67F.
LSMS: Language-guided Scale-aware MedSegmentor for Medical Image Referring Segmentation
Sep 02, 2024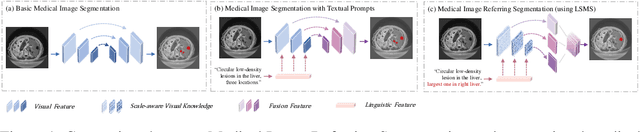
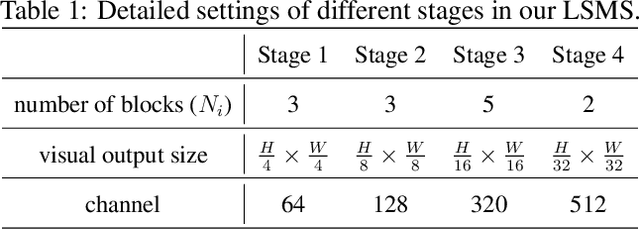
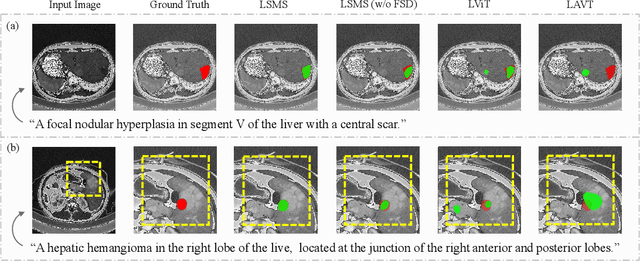
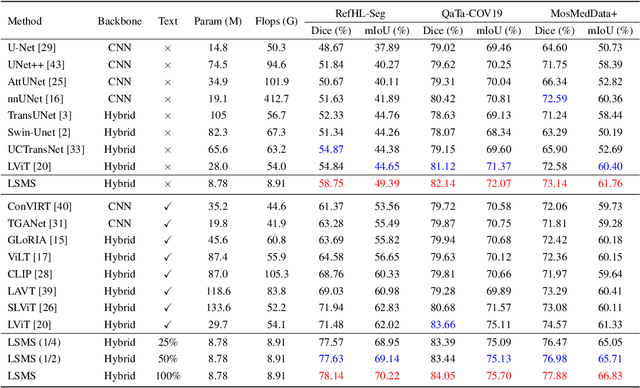
Conventional medical image segmentation methods have been found inadequate in facilitating physicians with the identification of specific lesions for diagnosis and treatment. Given the utility of text as an instructional format, we introduce a novel task termed Medical Image Referring Segmentation (MIRS), which requires segmenting specified lesions in images based on the given language expressions. Due to the varying object scales in medical images, MIRS demands robust vision-language modeling and comprehensive multi-scale interaction for precise localization and segmentation under linguistic guidance. However, existing medical image segmentation methods fall short in meeting these demands, resulting in insufficient segmentation accuracy. In response, we propose an approach named Language-guided Scale-aware MedSegmentor (LSMS), incorporating two appealing designs: (1)~a Scale-aware Vision-Language Attention module that leverages diverse convolutional kernels to acquire rich visual knowledge and interact closely with linguistic features, thereby enhancing lesion localization capability; (2)~a Full-Scale Decoder that globally models multi-modal features across various scales, capturing complementary information between scales to accurately outline lesion boundaries. Addressing the lack of suitable datasets for MIRS, we constructed a vision-language medical dataset called Reference Hepatic Lesion Segmentation (RefHL-Seg). This dataset comprises 2,283 abdominal CT slices from 231 cases, with corresponding textual annotations and segmentation masks for various liver lesions in images. We validated the performance of LSMS for MIRS and conventional medical image segmentation tasks across various datasets. Our LSMS consistently outperforms on all datasets with lower computational costs. The code and datasets will be released.