 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM3DHMR: Monocular 3D Hand Mesh Recovery
May 26, 2025Monocular 3D hand mesh recovery is challenging due to high degrees of freedom of hands, 2D-to-3D ambiguity and self-occlusion. Most existing methods are either inefficient or less straightforward for predicting the position of 3D mesh vertices. Thus, we propose a new pipeline called Monocular 3D Hand Mesh Recovery (M3DHMR) to directly estimate the positions of hand mesh vertices. M3DHMR provides 2D cues for 3D tasks from a single image and uses a new spiral decoder consist of several Dynamic Spiral Convolution (DSC) Layers and a Region of Interest (ROI) Layer. On the one hand, DSC Layers adaptively adjust the weights based on the vertex positions and extract the vertex features in both spatial and channel dimensions. On the other hand, ROI Layer utilizes the physical information and refines mesh vertices in each predefined hand region separately. Extensive experiments on popular dataset FreiHAND demonstrate that M3DHMR significantly outperforms state-of-the-art real-time methods.
LSMS: Language-guided Scale-aware MedSegmentor for Medical Image Referring Segmentation
Sep 02, 2024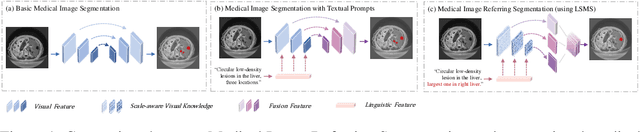
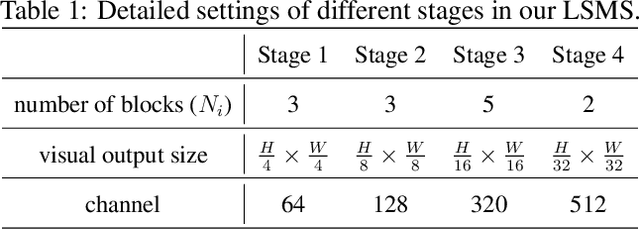
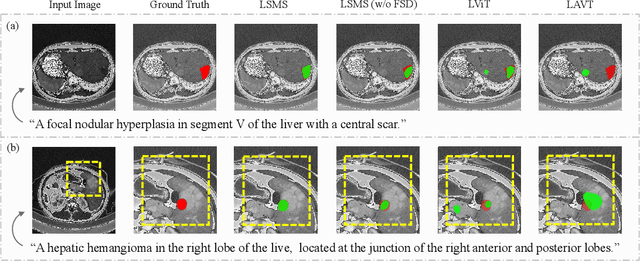
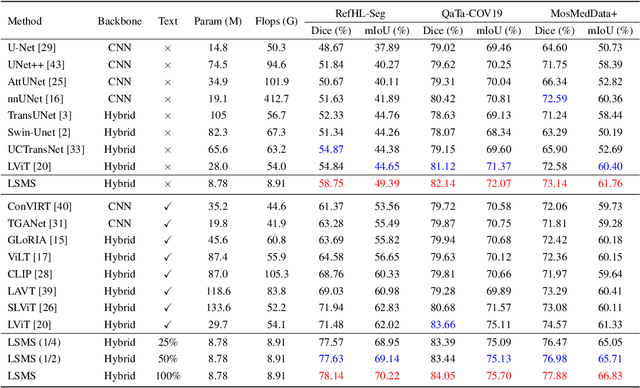
Conventional medical image segmentation methods have been found inadequate in facilitating physicians with the identification of specific lesions for diagnosis and treatment. Given the utility of text as an instructional format, we introduce a novel task termed Medical Image Referring Segmentation (MIRS), which requires segmenting specified lesions in images based on the given language expressions. Due to the varying object scales in medical images, MIRS demands robust vision-language modeling and comprehensive multi-scale interaction for precise localization and segmentation under linguistic guidance. However, existing medical image segmentation methods fall short in meeting these demands, resulting in insufficient segmentation accuracy. In response, we propose an approach named Language-guided Scale-aware MedSegmentor (LSMS), incorporating two appealing designs: (1)~a Scale-aware Vision-Language Attention module that leverages diverse convolutional kernels to acquire rich visual knowledge and interact closely with linguistic features, thereby enhancing lesion localization capability; (2)~a Full-Scale Decoder that globally models multi-modal features across various scales, capturing complementary information between scales to accurately outline lesion boundaries. Addressing the lack of suitable datasets for MIRS, we constructed a vision-language medical dataset called Reference Hepatic Lesion Segmentation (RefHL-Seg). This dataset comprises 2,283 abdominal CT slices from 231 cases, with corresponding textual annotations and segmentation masks for various liver lesions in images. We validated the performance of LSMS for MIRS and conventional medical image segmentation tasks across various datasets. Our LSMS consistently outperforms on all datasets with lower computational costs. The code and datasets will be released.
Explorers at #SMM4H 2023: Enhancing BERT for Health Applications through Knowledge and Model Fusion
Dec 17, 2023An increasing number of individuals are willing to post states and opinions in social media, which has become a valuable data resource for studying human health. Furthermore, social media has been a crucial research point for healthcare now. This paper outlines the methods in our participation in the #SMM4H 2023 Shared Tasks, including data preprocessing, continual pre-training and fine-tuned optimization strategies. Especially for the Named Entity Recognition (NER) task, we utilize the model architecture named W2NER that effectively enhances the model generalization ability. Our method achieved first place in the Task 3. This paper has been peer-reviewed and accepted for presentation at the #SMM4H 2023 Workshop.