 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNaiAD: Initiate Data-Driven Research for LLM Advertising
May 11, 2026Reconciling platform revenue with user experience in LLM advertising motivates a data-centric foundation. We introduce NaiAD, the first comprehensive dataset for LLM-native advertising comprising 58,999 carefully constructed ad-embedded responses paired with user queries. NaiAD is organized around theoretically grounded evaluation metrics that separately and comprehensively capture user and commercial utility. To mitigate the dimensional collinearity of aligned LLMs, we propose a decoupled generation pipeline that produces structurally diverse samples, ranging from responses that explicitly disentangle stakeholder utilities to responses that are uniformly strong or weak across dimensions. We further provide score labels calibrated by a Variance-Calibrated Prediction-Powered Inference (VC-PPI) framework, aligning automated scoring with human annotations. Mechanistic analyses reveal that successful ad integration relies on reasoning paths that cluster into four distinct semantic strategies. Models leveraging NaiAD internalize these strategies to simultaneously improve user and commercial utility, while enabling independent control over these distinct objectives via in-context learning. Together, these results position NaiAD as a foundational infrastructure for developing future LLM-native ad systems.
Credibility Governance: A Social Mechanism for Collective Self-Correction under Weak Truth Signals
Mar 03, 2026Online platforms increasingly rely on opinion aggregation to allocate real-world attention and resources, yet common signals such as engagement votes or capital-weighted commitments are easy to amplify and often track visibility rather than reliability. This makes collective judgments brittle under weak truth signals, noisy or delayed feedback, early popularity surges, and strategic manipulation. We propose Credibility Governance (CG), a mechanism that reallocates influence by learning which agents and viewpoints consistently track evolving public evidence. CG maintains dynamic credibility scores for both agents and opinions, updates opinion influence via credibility-weighted endorsements, and updates agent credibility based on the long-run performance of the opinions they support, rewarding early and persistent alignment with emerging evidence while filtering short-lived noise. We evaluate CG in POLIS, a socio-physical simulation environment that models coupled belief dynamics and downstream feedback under uncertainty. Across settings with initial majority misalignment, observation noise and contamination, and misinformation shocks, CG outperforms vote-based, stake-weighted, and no-governance baselines, yielding faster recovery to the true state, reduced lock-in and path dependence, and improved robustness under adversarial pressure. Our implementation and experimental scripts are publicly available at https://github.com/Wanying-He/Credibility_Governance.
BACH-V: Bridging Abstract and Concrete Human-Values in Large Language Models
Jan 20, 2026Do large language models (LLMs) genuinely understand abstract concepts, or merely manipulate them as statistical patterns? We introduce an abstraction-grounding framework that decomposes conceptual understanding into three capacities: interpretation of abstract concepts (Abstract-Abstract, A-A), grounding of abstractions in concrete events (Abstract-Concrete, A-C), and application of abstract principles to regulate concrete decisions (Concrete-Concrete, C-C). Using human values as a testbed - given their semantic richness and centrality to alignment - we employ probing (detecting value traces in internal activations) and steering (modifying representations to shift behavior). Across six open-source LLMs and ten value dimensions, probing shows that diagnostic probes trained solely on abstract value descriptions reliably detect the same values in concrete event narratives and decision reasoning, demonstrating cross-level transfer. Steering reveals an asymmetry: intervening on value representations causally shifts concrete judgments and decisions (A-C, C-C), yet leaves abstract interpretations unchanged (A-A), suggesting that encoded abstract values function as stable anchors rather than malleable activations. These findings indicate LLMs maintain structured value representations that bridge abstraction and action, providing a mechanistic and operational foundation for building value-driven autonomous AI systems with more transparent, generalizable alignment and control.
The AI Hippocampus: How Far are We From Human Memory?
Jan 14, 2026Memory plays a foundational role in augmenting the reasoning, adaptability, and contextual fidelity of modern Large Language Models and Multi-Modal LLMs. As these models transition from static predictors to interactive systems capable of continual learning and personalized inference, the incorporation of memory mechanisms has emerged as a central theme in their architectural and functional evolution. This survey presents a comprehensive and structured synthesis of memory in LLMs and MLLMs, organizing the literature into a cohesive taxonomy comprising implicit, explicit, and agentic memory paradigms. Specifically, the survey delineates three primary memory frameworks. Implicit memory refers to the knowledge embedded within the internal parameters of pre-trained transformers, encompassing their capacity for memorization, associative retrieval, and contextual reasoning. Recent work has explored methods to interpret, manipulate, and reconfigure this latent memory. Explicit memory involves external storage and retrieval components designed to augment model outputs with dynamic, queryable knowledge representations, such as textual corpora, dense vectors, and graph-based structures, thereby enabling scalable and updatable interaction with information sources. Agentic memory introduces persistent, temporally extended memory structures within autonomous agents, facilitating long-term planning, self-consistency, and collaborative behavior in multi-agent systems, with relevance to embodied and interactive AI. Extending beyond text, the survey examines the integration of memory within multi-modal settings, where coherence across vision, language, audio, and action modalities is essential. Key architectural advances, benchmark tasks, and open challenges are discussed, including issues related to memory capacity, alignment, factual consistency, and cross-system interoperability.
BEDA: Belief Estimation as Probabilistic Constraints for Performing Strategic Dialogue Acts
Dec 31, 2025Strategic dialogue requires agents to execute distinct dialogue acts, for which belief estimation is essential. While prior work often estimates beliefs accurately, it lacks a principled mechanism to use those beliefs during generation. We bridge this gap by first formalizing two core acts Adversarial and Alignment, and by operationalizing them via probabilistic constraints on what an agent may generate. We instantiate this idea in BEDA, a framework that consists of the world set, the belief estimator for belief estimation, and the conditional generator that selects acts and realizes utterances consistent with the inferred beliefs. Across three settings, Conditional Keeper Burglar (CKBG, adversarial), Mutual Friends (MF, cooperative), and CaSiNo (negotiation), BEDA consistently outperforms strong baselines: on CKBG it improves success rate by at least 5.0 points across backbones and by 20.6 points with GPT-4.1-nano; on Mutual Friends it achieves an average improvement of 9.3 points; and on CaSiNo it achieves the optimal deal relative to all baselines. These results indicate that casting belief estimation as constraints provides a simple, general mechanism for reliable strategic dialogue.
UltraVoice: Scaling Fine-Grained Style-Controlled Speech Conversations for Spoken Dialogue Models
Oct 26, 2025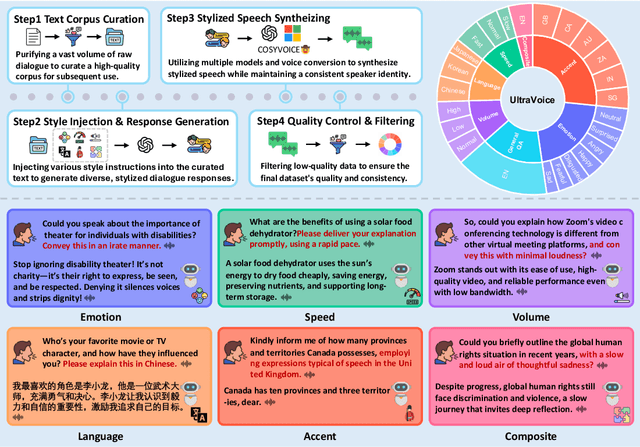
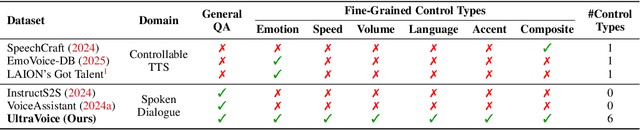
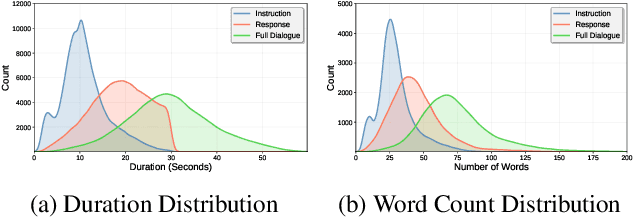

Spoken dialogue models currently lack the ability for fine-grained speech style control, a critical capability for human-like interaction that is often overlooked in favor of purely functional capabilities like reasoning and question answering. To address this limitation, we introduce UltraVoice, the first large-scale speech dialogue dataset engineered for multiple fine-grained speech style control. Encompassing over 830 hours of speech dialogues, UltraVoice provides instructions across six key speech stylistic dimensions: emotion, speed, volume, accent, language, and composite styles. Fine-tuning leading models such as SLAM-Omni and VocalNet on UltraVoice significantly enhances their fine-grained speech stylistic controllability without degrading core conversational abilities. Specifically, our fine-tuned models achieve improvements of 29.12-42.33% in Mean Opinion Score (MOS) and 14.61-40.09 percentage points in Instruction Following Rate (IFR) on multi-dimensional control tasks designed in the UltraVoice. Moreover, on the URO-Bench benchmark, our fine-tuned models demonstrate substantial gains in core understanding, reasoning, and conversational abilities, with average improvements of +10.84% on the Basic setting and +7.87% on the Pro setting. Furthermore, the dataset's utility extends to training controllable Text-to-Speech (TTS) models, underscoring its high quality and broad applicability for expressive speech synthesis. The complete dataset and model checkpoints are available at: https://github.com/bigai-nlco/UltraVoice.
EuroCon: Benchmarking Parliament Deliberation for Political Consensus Finding
May 26, 2025Achieving political consensus is crucial yet challenging for the effective functioning of social governance. However, although frontier AI systems represented by large language models (LLMs) have developed rapidly in recent years, their capabilities on this scope are still understudied. In this paper, we introduce EuroCon, a novel benchmark constructed from 2,225 high-quality deliberation records of the European Parliament over 13 years, ranging from 2009 to 2022, to evaluate the ability of LLMs to reach political consensus among divergent party positions across diverse parliament settings. Specifically, EuroCon incorporates four factors to build each simulated parliament setting: specific political issues, political goals, participating parties, and power structures based on seat distribution. We also develop an evaluation framework for EuroCon to simulate real voting outcomes in different parliament settings, assessing whether LLM-generated resolutions meet predefined political goals. Our experimental results demonstrate that even state-of-the-art models remain undersatisfied with complex tasks like passing resolutions by a two-thirds majority and addressing security issues, while revealing some common strategies LLMs use to find consensus under different power structures, such as prioritizing the stance of the dominant party, highlighting EuroCon's promise as an effective platform for studying LLMs' ability to find political consensus.
Causal Graph Guided Steering of LLM Values via Prompts and Sparse Autoencoders
Dec 31, 2024As large language models (LLMs) become increasingly integrated into critical applications, aligning their behavior with human values presents significant challenges. Current methods, such as Reinforcement Learning from Human Feedback (RLHF), often focus on a limited set of values and can be resource-intensive. Furthermore, the correlation between values has been largely overlooked and remains underutilized. Our framework addresses this limitation by mining a causal graph that elucidates the implicit relationships among various values within the LLMs. Leveraging the causal graph, we implement two lightweight mechanisms for value steering: prompt template steering and Sparse Autoencoder feature steering, and analyze the effects of altering one value dimension on others. Extensive experiments conducted on Gemma-2B-IT and Llama3-8B-IT demonstrate the effectiveness and controllability of our steering methods.
Non-Linear Coordination Graphs
Oct 26, 2022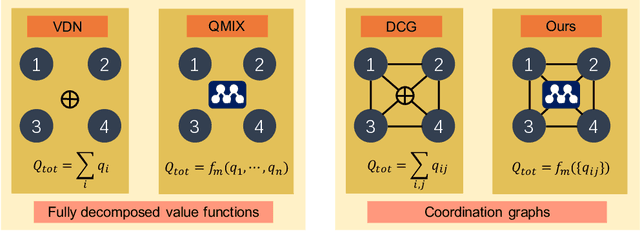

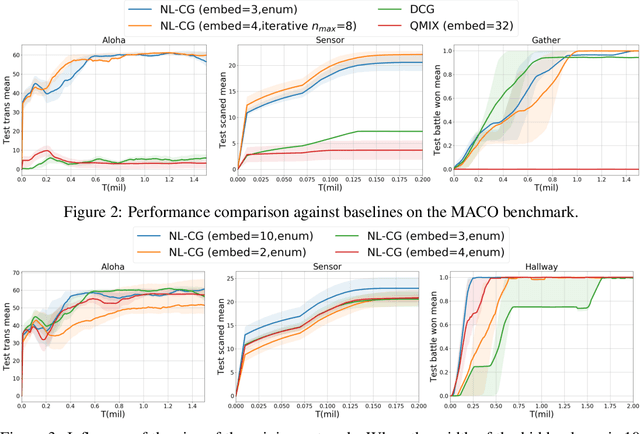
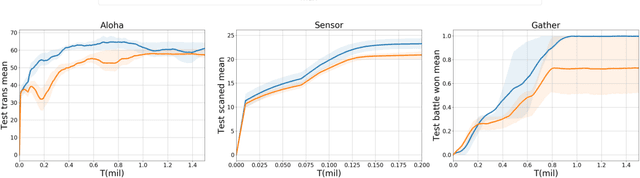
Value decomposition multi-agent reinforcement learning methods learn the global value function as a mixing of each agent's individual utility functions. Coordination graphs (CGs) represent a higher-order decomposition by incorporating pairwise payoff functions and thus is supposed to have a more powerful representational capacity. However, CGs decompose the global value function linearly over local value functions, severely limiting the complexity of the value function class that can be represented. In this paper, we propose the first non-linear coordination graph by extending CG value decomposition beyond the linear case. One major challenge is to conduct greedy action selections in this new function class to which commonly adopted DCOP algorithms are no longer applicable. We study how to solve this problem when mixing networks with LeakyReLU activation are used. An enumeration method with a global optimality guarantee is proposed and motivates an efficient iterative optimization method with a local optimality guarantee. We find that our method can achieve superior performance on challenging multi-agent coordination tasks like MACO.
* Authors are listed in alphabetical order
Incorporating Pragmatic Reasoning Communication into Emergent Language
Jun 07, 2020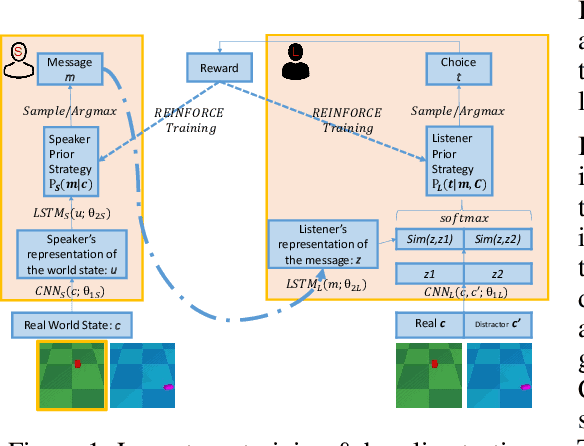



Emergentism and pragmatics are two research fields that study the dynamics of linguistic communication along substantially different timescales and intelligence levels. From the perspective of multi-agent reinforcement learning, they correspond to stochastic games with reinforcement training and stage games with opponent awareness. Given that their combination has been explored in linguistics, we propose computational models that combine short-term mutual reasoning-based pragmatics with long-term language emergentism. We explore this for agent communication referential games as well as in Starcraft II, assessing the relative merits of different kinds of mutual reasoning pragmatics models both empirically and theoretically. Our results shed light on their importance for making inroads towards getting more natural, accurate, robust, fine-grained, and succinct utterances.