 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComposite Flow Matching for Reinforcement Learning with Shifted-Dynamics Data
May 29, 2025Incorporating pre-collected offline data from a source environment can significantly improve the sample efficiency of reinforcement learning (RL), but this benefit is often challenged by discrepancies between the transition dynamics of the source and target environments. Existing methods typically address this issue by penalizing or filtering out source transitions in high dynamics-gap regions. However, their estimation of the dynamics gap often relies on KL divergence or mutual information, which can be ill-defined when the source and target dynamics have disjoint support. To overcome these limitations, we propose CompFlow, a method grounded in the theoretical connection between flow matching and optimal transport. Specifically, we model the target dynamics as a conditional flow built upon the output distribution of the source-domain flow, rather than learning it directly from a Gaussian prior. This composite structure offers two key advantages: (1) improved generalization for learning target dynamics, and (2) a principled estimation of the dynamics gap via the Wasserstein distance between source and target transitions. Leveraging our principled estimation of the dynamics gap, we further introduce an optimistic active data collection strategy that prioritizes exploration in regions of high dynamics gap, and theoretically prove that it reduces the performance disparity with the optimal policy. Empirically, CompFlow outperforms strong baselines across several RL benchmarks with shifted dynamics.
Adaptive Frontier Exploration on Graphs with Applications to Network-Based Disease Testing
May 27, 2025We study a sequential decision-making problem on a $n$-node graph $G$ where each node has an unknown label from a finite set $\mathbf{\Sigma}$, drawn from a joint distribution $P$ that is Markov with respect to $G$. At each step, selecting a node reveals its label and yields a label-dependent reward. The goal is to adaptively choose nodes to maximize expected accumulated discounted rewards. We impose a frontier exploration constraint, where actions are limited to neighbors of previously selected nodes, reflecting practical constraints in settings such as contact tracing and robotic exploration. We design a Gittins index-based policy that applies to general graphs and is provably optimal when $G$ is a forest. Our implementation runs in $O(n^2 \cdot |\mathbf{\Sigma}|^2)$ time while using $O(n \cdot |\mathbf{\Sigma}|^2)$ oracle calls to $P$ and $O(n^2 \cdot |\mathbf{\Sigma}|)$ space. Experiments on synthetic and real-world graphs show that our method consistently outperforms natural baselines, including in non-tree, budget-limited, and undiscounted settings. For example, in HIV testing simulations on real-world sexual interaction networks, our policy detects nearly all positive cases with only half the population tested, substantially outperforming other baselines.
Policy-to-Language: Train LLMs to Explain Decisions with Flow-Matching Generated Rewards
Feb 18, 2025As humans increasingly share environments with diverse agents powered by RL, LLMs, and beyond, the ability to explain their policies in natural language will be vital for reliable coexistence. In this paper, we build a model-agnostic explanation generator based on an LLM. The technical novelty is that the rewards for training this LLM are generated by a generative flow matching model. This model has a specially designed structure with a hidden layer merged with an LLM to harness the linguistic cues of explanations into generating appropriate rewards. Experiments on both RL and LLM tasks demonstrate that our method can generate dense and effective rewards while saving on expensive human feedback; it thus enables effective explanations and even improves the accuracy of the decisions in original tasks.
On Diffusion Models for Multi-Agent Partial Observability: Shared Attractors, Error Bounds, and Composite Flow
Oct 17, 2024



Multiagent systems grapple with partial observability (PO), and the decentralized POMDP (Dec-POMDP) model highlights the fundamental nature of this challenge. Whereas recent approaches to address PO have appealed to deep learning models, providing a rigorous understanding of how these models and their approximation errors affect agents' handling of PO and their interactions remain a challenge. In addressing this challenge, we investigate reconstructing global states from local action-observation histories in Dec-POMDPs using diffusion models. We first find that diffusion models conditioned on local history represent possible states as stable fixed points. In collectively observable (CO) Dec-POMDPs, individual diffusion models conditioned on agents' local histories share a unique fixed point corresponding to the global state, while in non-CO settings, the shared fixed points yield a distribution of possible states given joint history. We further find that, with deep learning approximation errors, fixed points can deviate from true states and the deviation is negatively correlated to the Jacobian rank. Inspired by this low-rank property, we bound the deviation by constructing a surrogate linear regression model that approximates the local behavior of diffusion models. With this bound, we propose a composite diffusion process iterating over agents with theoretical convergence guarantees to the true state.
The Bandit Whisperer: Communication Learning for Restless Bandits
Aug 11, 2024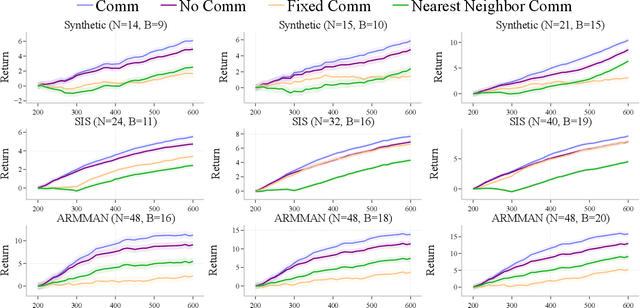
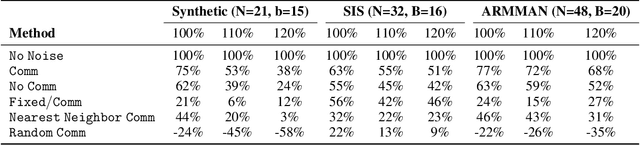
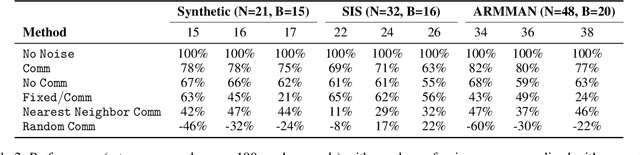
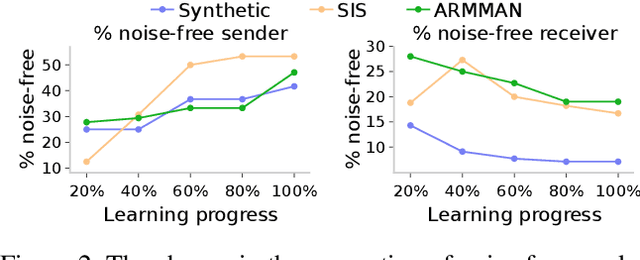
Applying Reinforcement Learning (RL) to Restless Multi-Arm Bandits (RMABs) offers a promising avenue for addressing allocation problems with resource constraints and temporal dynamics. However, classic RMAB models largely overlook the challenges of (systematic) data errors - a common occurrence in real-world scenarios due to factors like varying data collection protocols and intentional noise for differential privacy. We demonstrate that conventional RL algorithms used to train RMABs can struggle to perform well in such settings. To solve this problem, we propose the first communication learning approach in RMABs, where we study which arms, when involved in communication, are most effective in mitigating the influence of such systematic data errors. In our setup, the arms receive Q-function parameters from similar arms as messages to guide behavioral policies, steering Q-function updates. We learn communication strategies by considering the joint utility of messages across all pairs of arms and using a Q-network architecture that decomposes the joint utility. Both theoretical and empirical evidence validate the effectiveness of our method in significantly improving RMAB performance across diverse problems.
Principal-Agent Reinforcement Learning
Jul 25, 2024



Contracts are the economic framework which allows a principal to delegate a task to an agent -- despite misaligned interests, and even without directly observing the agent's actions. In many modern reinforcement learning settings, self-interested agents learn to perform a multi-stage task delegated to them by a principal. We explore the significant potential of utilizing contracts to incentivize the agents. We model the delegated task as an MDP, and study a stochastic game between the principal and agent where the principal learns what contracts to use, and the agent learns an MDP policy in response. We present a learning-based algorithm for optimizing the principal's contracts, which provably converges to the subgame-perfect equilibrium of the principal-agent game. A deep RL implementation allows us to apply our method to very large MDPs with unknown transition dynamics. We extend our approach to multiple agents, and demonstrate its relevance to resolving a canonical sequential social dilemma with minimal intervention to agent rewards.
GemNet: Menu-Based, Strategy-Proof Multi-Bidder Auctions Through Deep Learning
Jun 11, 2024



Differentiable economics uses deep learning for automated mechanism design. Despite strong progress, it has remained an open problem to learn multi-bidder, general, and fully strategy-proof (SP) auctions. We introduce GEneral Menu-based NETwork (GemNet), which significantly extends the menu-based approach of RochetNet [D\"utting et al., 2023] to the multi-bidder setting. The challenge in achieving SP is to learn bidder-independent menus that are feasible, so that the optimal menu choices for each bidder do not over-allocate items when taken together (we call this menu compatibility). GemNet penalizes the failure of menu compatibility during training, and transforms learned menus after training through price changes, by considering a set of discretized bidder values and reasoning about Lipschitz smoothness to guarantee menu compatibility on the entire value space. This approach is general, leaving undisturbed trained menus that already satisfy menu compatibility and reducing to RochetNet for a single bidder. Mixed-integer linear programs are used for menu transforms and through a number of optimizations, including adaptive grids and methods to skip menu elements, we scale to large auction design problems. GemNet learns auctions with better revenue than affine maximization methods, achieves exact SP whereas previous general multi-bidder methods are approximately SP, and offers greatly enhanced interpretability.
Social Environment Design
Feb 21, 2024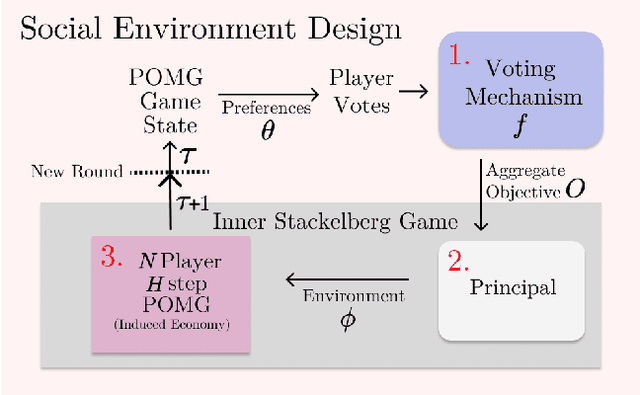
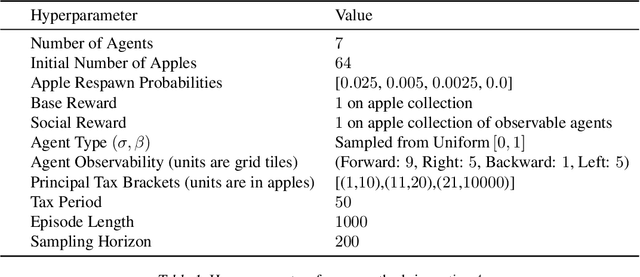
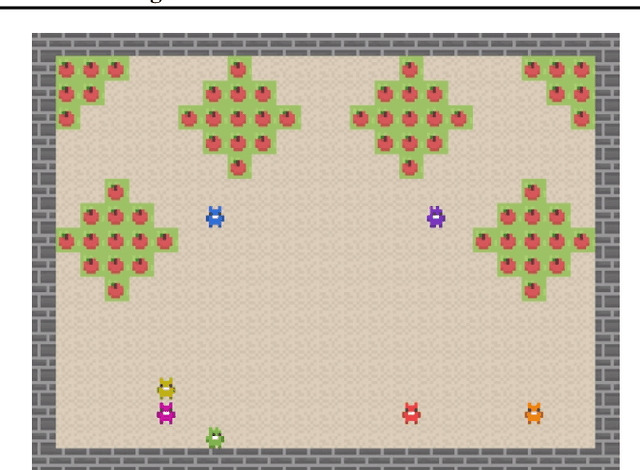
Artificial Intelligence (AI) holds promise as a technology that can be used to improve government and economic policy-making. This paper proposes a new research agenda towards this end by introducing Social Environment Design, a general framework for the use of AI for automated policy-making that connects with the Reinforcement Learning, EconCS, and Computational Social Choice communities. The framework seeks to capture general economic environments, includes voting on policy objectives, and gives a direction for the systematic analysis of government and economic policy through AI simulation. We highlight key open problems for future research in AI-based policy-making. By solving these challenges, we hope to achieve various social welfare objectives, thereby promoting more ethical and responsible decision making.
Multi-Sender Persuasion -- A Computational Perspective
Feb 08, 2024



We consider multiple senders with informational advantage signaling to convince a single self-interested actor towards certain actions. Generalizing the seminal Bayesian Persuasion framework, such settings are ubiquitous in computational economics, multi-agent learning, and machine learning with multiple objectives. The core solution concept here is the Nash equilibrium of senders' signaling policies. Theoretically, we prove that finding an equilibrium in general is PPAD-Hard; in fact, even computing a sender's best response is NP-Hard. Given these intrinsic difficulties, we turn to finding local Nash equilibria. We propose a novel differentiable neural network to approximate this game's non-linear and discontinuous utilities. Complementing this with the extra-gradient algorithm, we discover local equilibria that Pareto dominates full-revelation equilibria and those found by existing neural networks. Broadly, our theoretical and empirical contributions are of interest to a large class of economic problems.
Never Explore Repeatedly in Multi-Agent Reinforcement Learning
Aug 19, 2023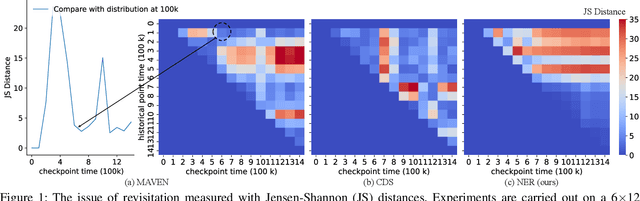
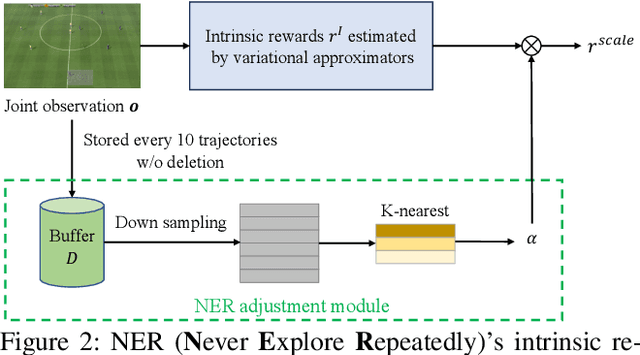
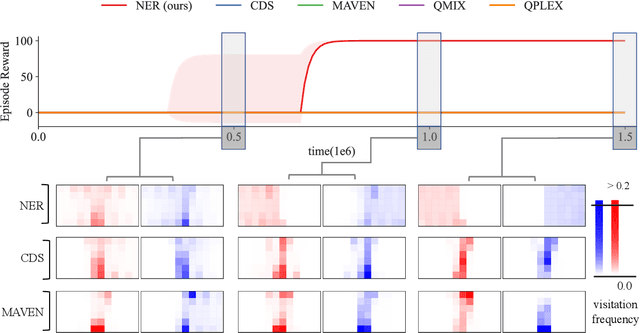
In the realm of multi-agent reinforcement learning, intrinsic motivations have emerged as a pivotal tool for exploration. While the computation of many intrinsic rewards relies on estimating variational posteriors using neural network approximators, a notable challenge has surfaced due to the limited expressive capability of these neural statistics approximators. We pinpoint this challenge as the "revisitation" issue, where agents recurrently explore confined areas of the task space. To combat this, we propose a dynamic reward scaling approach. This method is crafted to stabilize the significant fluctuations in intrinsic rewards in previously explored areas and promote broader exploration, effectively curbing the revisitation phenomenon. Our experimental findings underscore the efficacy of our approach, showcasing enhanced performance in demanding environments like Google Research Football and StarCraft II micromanagement tasks, especially in sparse reward settings.