 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Prosocial Ranking Challenge: Reducing Polarization on Social Media without Sacrificing Engagement
Mar 20, 2026We report the first direct comparisons of multiple alternative social media algorithms on multiple platforms on outcomes of societal interest. We used a browser extension to modify which posts were shown to desktop social media users, randomly assigning 9,386 users to a control group or one of five alternative ranking algorithms which simultaneously altered content across three platforms for six months during the US 2024 presidential election. This reduced our preregistered index of affective polarization by an average of 0.03 standard deviations (p < 0.05), including a 1.5 degree decrease in differences between the 100 point inparty and outparty feeling thermometers. We saw reductions in active use time for Facebook (-0.37 min/day) and Reddit (-0.2 min/day), but an increase of 0.32 min/day (p < 0.01) for X/Twitter. We saw an increase in reports of negative social media experiences but found no effects on well-being, news knowledge, outgroup empathy, perceptions of and support for partisan violence. This implies that bridging content can improve some societal outcomes without necessarily conflicting with the engagement-driven business model of social media.
Learning to Play Multi-Follower Bayesian Stackelberg Games
Oct 01, 2025In a multi-follower Bayesian Stackelberg game, a leader plays a mixed strategy over $L$ actions to which $n\ge 1$ followers, each having one of $K$ possible private types, best respond. The leader's optimal strategy depends on the distribution of the followers' private types. We study an online learning version of this problem: a leader interacts for $T$ rounds with $n$ followers with types sampled from an unknown distribution every round. The leader's goal is to minimize regret, defined as the difference between the cumulative utility of the optimal strategy and that of the actually chosen strategies. We design learning algorithms for the leader under different feedback settings. Under type feedback, where the leader observes the followers' types after each round, we design algorithms that achieve $\mathcal O\big(\sqrt{\min\{L\log(nKA T), nK \} \cdot T} \big)$ regret for independent type distributions and $\mathcal O\big(\sqrt{\min\{L\log(nKA T), K^n \} \cdot T} \big)$ regret for general type distributions. Interestingly, those bounds do not grow with $n$ at a polynomial rate. Under action feedback, where the leader only observes the followers' actions, we design algorithms with $\mathcal O( \min\{\sqrt{ n^L K^L A^{2L} L T \log T}, K^n\sqrt{ T } \log T \} )$ regret. We also provide a lower bound of $\Omega(\sqrt{\min\{L, nK\}T})$, almost matching the type-feedback upper bounds.
Strategic Classification With Externalities
Oct 10, 2024We propose a new variant of the strategic classification problem: a principal reveals a classifier, and $n$ agents report their (possibly manipulated) features to be classified. Motivated by real-world applications, our model crucially allows the manipulation of one agent to affect another; that is, it explicitly captures inter-agent externalities. The principal-agent interactions are formally modeled as a Stackelberg game, with the resulting agent manipulation dynamics captured as a simultaneous game. We show that under certain assumptions, the pure Nash Equilibrium of this agent manipulation game is unique and can be efficiently computed. Leveraging this result, PAC learning guarantees are established for the learner: informally, we show that it is possible to learn classifiers that minimize loss on the distribution, even when a random number of agents are manipulating their way to a pure Nash Equilibrium. We also comment on the optimization of such classifiers through gradient-based approaches. This work sets the theoretical foundations for a more realistic analysis of classifiers that are robust against multiple strategic actors interacting in a common environment.
JacNet: Learning Functions with Structured Jacobians
Aug 23, 2024


Neural networks are trained to learn an approximate mapping from an input domain to a target domain. Incorporating prior knowledge about true mappings is critical to learning a useful approximation. With current architectures, it is challenging to enforce structure on the derivatives of the input-output mapping. We propose to use a neural network to directly learn the Jacobian of the input-output function, which allows easy control of the derivative. We focus on structuring the derivative to allow invertibility and also demonstrate that other useful priors, such as $k$-Lipschitz, can be enforced. Using this approach, we can learn approximations to simple functions that are guaranteed to be invertible and easily compute the inverse. We also show similar results for 1-Lipschitz functions.
Social Environment Design
Feb 21, 2024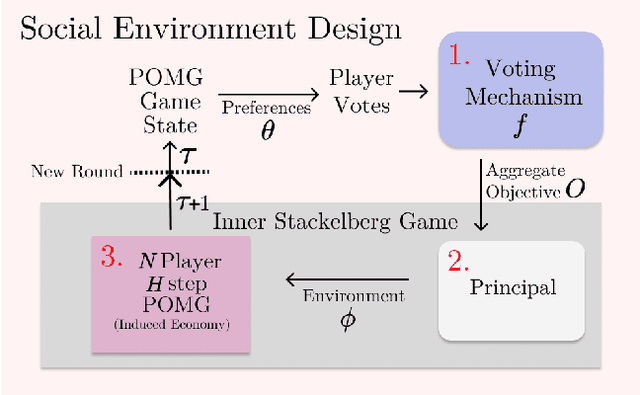
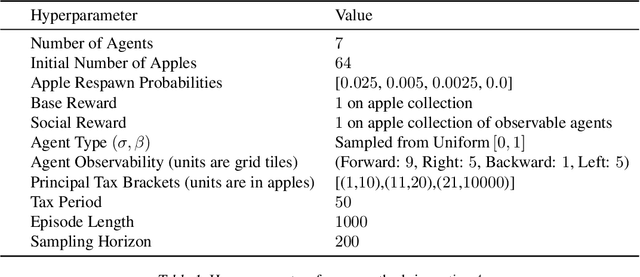
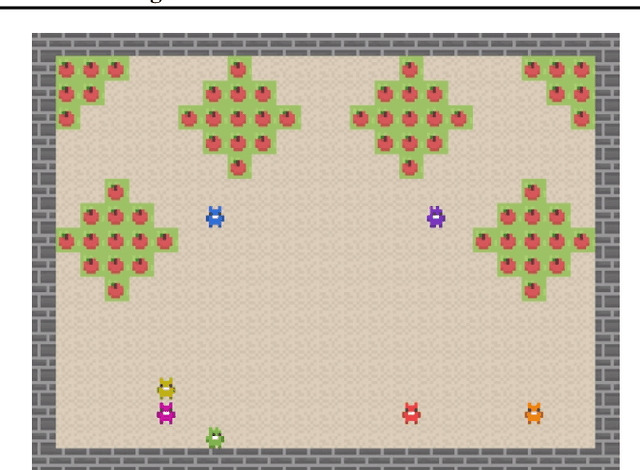
Artificial Intelligence (AI) holds promise as a technology that can be used to improve government and economic policy-making. This paper proposes a new research agenda towards this end by introducing Social Environment Design, a general framework for the use of AI for automated policy-making that connects with the Reinforcement Learning, EconCS, and Computational Social Choice communities. The framework seeks to capture general economic environments, includes voting on policy objectives, and gives a direction for the systematic analysis of government and economic policy through AI simulation. We highlight key open problems for future research in AI-based policy-making. By solving these challenges, we hope to achieve various social welfare objectives, thereby promoting more ethical and responsible decision making.
Computing Voting Rules with Elicited Incomplete Votes
Feb 16, 2024Motivated by the difficulty of specifying complete ordinal preferences over a large set of $m$ candidates, we study voting rules that are computable by querying voters about $t < m$ candidates. Generalizing prior works that focused on specific instances of this problem, our paper fully characterizes the set of positional scoring rules that can be computed for any $1 \leq t < m$, which notably does not include plurality. We then extend this to show a similar impossibility result for single transferable vote (elimination voting). These negative results are information-theoretic and agnostic to the number of queries. Finally, for scoring rules that are computable with limited-sized queries, we give parameterized upper and lower bounds on the number of such queries a deterministic or randomized algorithm must make to determine the score-maximizing candidate. While there is no gap between our bounds for deterministic algorithms, identifying the exact query complexity for randomized algorithms is a challenging open problem, of which we solve one special case.
Multi-Sender Persuasion -- A Computational Perspective
Feb 08, 2024



We consider multiple senders with informational advantage signaling to convince a single self-interested actor towards certain actions. Generalizing the seminal Bayesian Persuasion framework, such settings are ubiquitous in computational economics, multi-agent learning, and machine learning with multiple objectives. The core solution concept here is the Nash equilibrium of senders' signaling policies. Theoretically, we prove that finding an equilibrium in general is PPAD-Hard; in fact, even computing a sender's best response is NP-Hard. Given these intrinsic difficulties, we turn to finding local Nash equilibria. We propose a novel differentiable neural network to approximate this game's non-linear and discontinuous utilities. Complementing this with the extra-gradient algorithm, we discover local equilibria that Pareto dominates full-revelation equilibria and those found by existing neural networks. Broadly, our theoretical and empirical contributions are of interest to a large class of economic problems.
Equilibrium and Learning in Fixed-Price Data Markets with Externality
Feb 16, 2023
We propose modeling real-world data markets, where sellers post fixed prices and buyers are free to purchase from any set of sellers they please, as a simultaneous-move game between the buyers. A key component of this model is the negative externality buyers induce on one another due to purchasing similar data, a phenomenon exacerbated by its easy replicability. In the complete-information setting, where all buyers know their valuations, we characterize both the existence and the quality (with respect to optimal social welfare) of the pure-strategy Nash equilibrium under various models of buyer externality. While this picture is bleak without any market intervention, reinforcing the inadequacy of modern data markets, we prove that for a broad class of externality functions, market intervention in the form of a revenue-neutral transaction cost can lead to a pure-strategy equilibrium with strong welfare guarantees. We further show that this intervention is amenable to the more realistic setting where buyers start with unknown valuations and learn them over time through repeated market interactions. For such a setting, we provide an online learning algorithm for each buyer that achieves low regret guarantees with respect to both individual buyers' strategy and social welfare optimal. Our work paves the way for considering simple intervention strategies for existing fixed-price data markets to address their shortcoming and the unique challenges put forth by data products.
Exploring Text Specific and Blackbox Fairness Algorithms in Multimodal Clinical NLP
Nov 19, 2020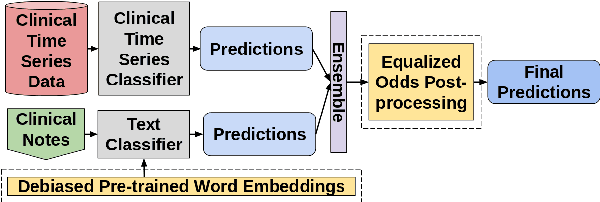
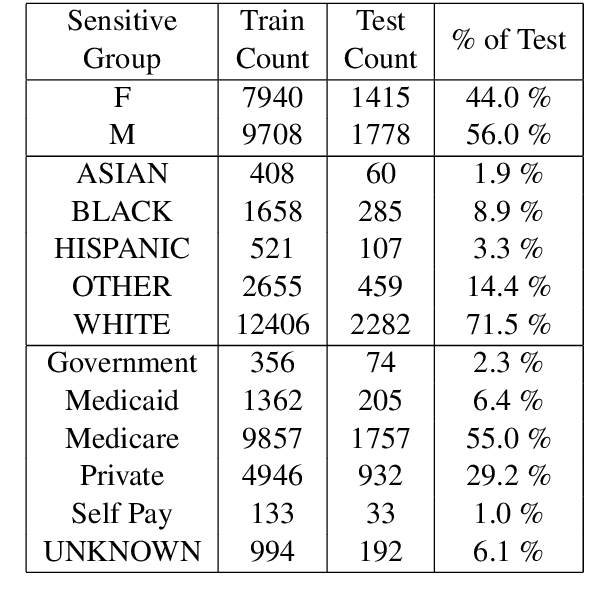
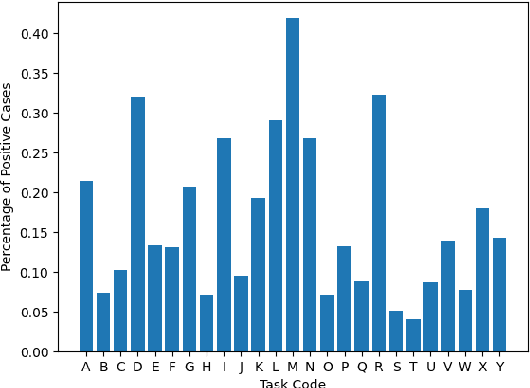
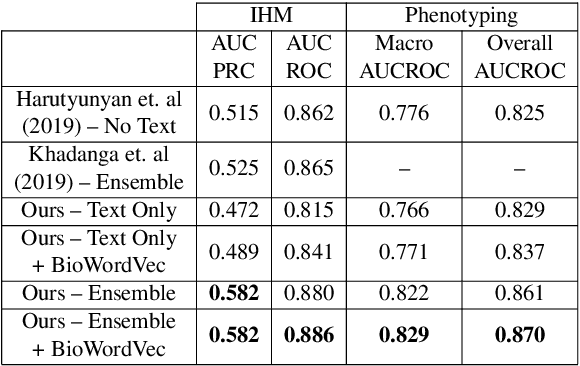
Clinical machine learning is increasingly multimodal, collected in both structured tabular formats and unstructured forms such as freetext. We propose a novel task of exploring fairness on a multimodal clinical dataset, adopting equalized odds for the downstream medical prediction tasks. To this end, we investigate a modality-agnostic fairness algorithm - equalized odds post processing - and compare it to a text-specific fairness algorithm: debiased clinical word embeddings. Despite the fact that debiased word embeddings do not explicitly address equalized odds of protected groups, we show that a text-specific approach to fairness may simultaneously achieve a good balance of performance and classical notions of fairness. We hope that our paper inspires future contributions at the critical intersection of clinical NLP and fairness. The full source code is available here: https://github.com/johntiger1/multimodal_fairness
* Best paper award at 3rd Clinical Natural Language Processing Workshop at EMNLP 2020
Fair Algorithms for Multi-Agent Multi-Armed Bandits
Jul 13, 2020We propose a multi-agent variant of the classical multi-armed bandit problem, in which there are N agents and K arms, and pulling an arm generates a (possibly different) stochastic reward to each agent. Unlike the classical multi-armed bandit problem, the goal is not to learn the "best arm", as each agent may perceive a different arm as best for her. Instead, we seek to learn a fair distribution over arms. Drawing on a long line of research in economics and computer science, we use the Nash social welfare as our notion of fairness. We design multi-agent variants of three classic multi-armed bandit algorithms, and show that they achieve sublinear regret, now measured in terms of the Nash social welfare.