 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Text Specific and Blackbox Fairness Algorithms in Multimodal Clinical NLP
Nov 19, 2020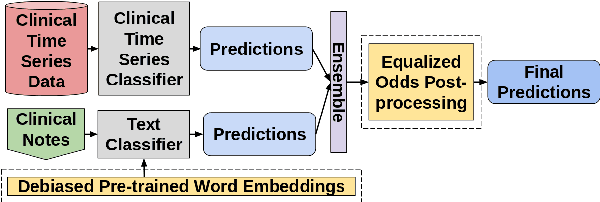
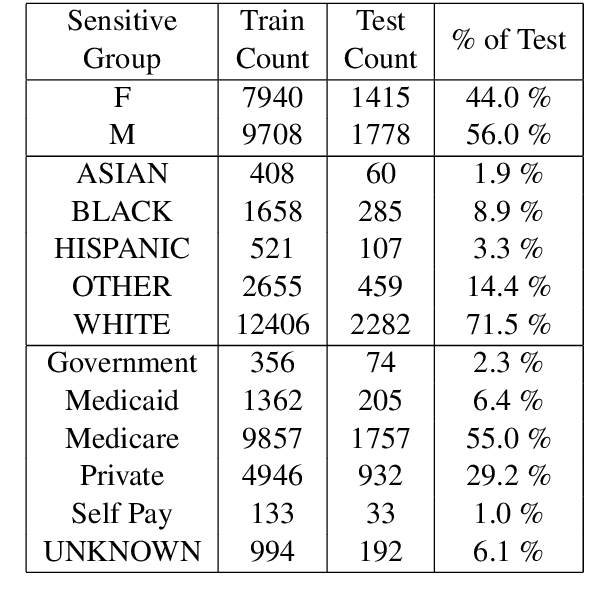
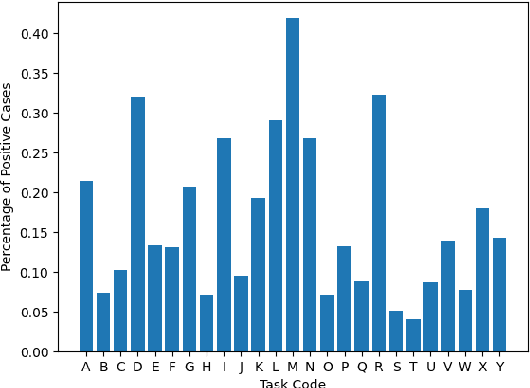
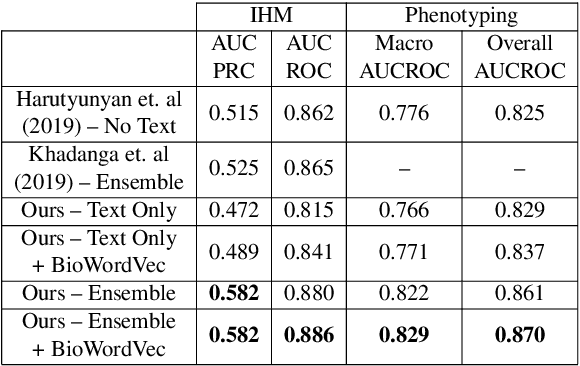
Clinical machine learning is increasingly multimodal, collected in both structured tabular formats and unstructured forms such as freetext. We propose a novel task of exploring fairness on a multimodal clinical dataset, adopting equalized odds for the downstream medical prediction tasks. To this end, we investigate a modality-agnostic fairness algorithm - equalized odds post processing - and compare it to a text-specific fairness algorithm: debiased clinical word embeddings. Despite the fact that debiased word embeddings do not explicitly address equalized odds of protected groups, we show that a text-specific approach to fairness may simultaneously achieve a good balance of performance and classical notions of fairness. We hope that our paper inspires future contributions at the critical intersection of clinical NLP and fairness. The full source code is available here: https://github.com/johntiger1/multimodal_fairness
* Best paper award at 3rd Clinical Natural Language Processing Workshop at EMNLP 2020