 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTo Nuke or Not to Nuke: LLMs' (Missing) Ethical Reasoning and Actions in a High-Stakes Decision-Making Simulation
Jun 06, 2026Large language models (LLMs) are increasingly deployed as long-horizon agents with decision-making capacities. While LLMs can show ethical competence on dilemmas such as trolley problems, this competence may not translate to complex, agentic scenarios. We study this gap in Civilization V, a multiplayer game with a complex decision-making landscape including economy, diplomacy, technology, and military strategy. Starting from 130 high-tension LLM self-play episodes, in which an LLM player spontaneously escalated nuclear authorization, we replay them across 13 models with three prompt interventions: an ethical prompt naming nuclear harm, removal of the previous model's decision-making rationale, and high-stakes framing emphasizing real-world impacts. No interventions nor their combinations reliably eliminate emergent escalation. We identify three failure pathways: ethical reasoning that fails to surface without prompting, fails to appear even when prompted, or surfaces but fails to take effect when strategic counter-factors dominate. Evaluations of agentic models, therefore, must test whether ethical reasoning is spontaneously invoked and behaviorally effective in complex decision-making contexts, beyond whether it can be elicited in isolation.
CivBench: Progress-Based Evaluation for LLMs' Strategic Decision-Making in Civilization V
Apr 09, 2026Evaluating strategic decision-making in LLM-based agents requires generative, competitive, and longitudinal environments, yet few benchmarks provide all three, and fewer still offer evaluation signals rich enough for long-horizon, multi-agent play. We introduce CivBench, a benchmark for LLM strategists (i.e., agentic setups) in multiplayer Civilization V. Because terminal win/loss is too sparse a signal in games spanning hundreds of turns and multiple opponents, CivBench trains models on turn-level game state to estimate victory probabilities throughout play, validated through predictive, construct, and convergent validity. Across 307 games with 7 LLMs and multiple CivBench agent conditions, we demonstrate CivBench's potential to estimate strategic capabilities as an unsaturated benchmark, reveal model-specific effects of agentic setup, and outline distinct strategic profiles not visible through outcome-only evaluation.
Vox Deorum: A Hybrid LLM Architecture for 4X / Grand Strategy Game AI -- Lessons from Civilization V
Dec 21, 2025Large Language Models' capacity to reason in natural language makes them uniquely promising for 4X and grand strategy games, enabling more natural human-AI gameplay interactions such as collaboration and negotiation. However, these games present unique challenges due to their complexity and long-horizon nature, while latency and cost factors may hinder LLMs' real-world deployment. Working on a classic 4X strategy game, Sid Meier's Civilization V with the Vox Populi mod, we introduce Vox Deorum, a hybrid LLM+X architecture. Our layered technical design empowers LLMs to handle macro-strategic reasoning, delegating tactical execution to subsystems (e.g., algorithmic AI or reinforcement learning AI in the future). We validate our approach through 2,327 complete games, comparing two open-source LLMs with a simple prompt against Vox Populi's enhanced AI. Results show that LLMs achieve competitive end-to-end gameplay while exhibiting play styles that diverge substantially from algorithmic AI and from each other. Our work establishes a viable architecture for integrating LLMs in commercial 4X games, opening new opportunities for game design and agentic AI research.
A Computational Method for Measuring "Open Codes" in Qualitative Analysis
Nov 19, 2024



Qualitative analysis is critical to understanding human datasets in many social science disciplines. Open coding is an inductive qualitative process that identifies and interprets "open codes" from datasets. Yet, meeting methodological expectations (such as "as exhaustive as possible") can be challenging. While many machine learning (ML)/generative AI (GAI) studies have attempted to support open coding, few have systematically measured or evaluated GAI outcomes, increasing potential bias risks. Building on Grounded Theory and Thematic Analysis theories, we present a computational method to measure and identify potential biases from "open codes" systematically. Instead of operationalizing human expert results as the "ground truth," our method is built upon a team-based approach between human and machine coders. We experiment with two HCI datasets to establish this method's reliability by 1) comparing it with human analysis, and 2) analyzing its output stability. We present evidence-based suggestions and example workflows for ML/GAI to support open coding.
Prompts Matter: Comparing ML/GAI Approaches for Generating Inductive Qualitative Coding Results
Nov 10, 2024

Inductive qualitative methods have been a mainstay of education research for decades, yet it takes much time and effort to conduct rigorously. Recent advances in artificial intelligence, particularly with generative AI (GAI), have led to initial success in generating inductive coding results. Like human coders, GAI tools rely on instructions to work, and how to instruct it may matter. To understand how ML/GAI approaches could contribute to qualitative coding processes, this study applied two known and two theory-informed novel approaches to an online community dataset and evaluated the resulting coding results. Our findings show significant discrepancies between ML/GAI approaches and demonstrate the advantage of our approaches, which introduce human coding processes into GAI prompts.
A Network Simulation of OTC Markets with Multiple Agents
May 03, 2024



We present a novel agent-based approach to simulating an over-the-counter (OTC) financial market in which trades are intermediated solely by market makers and agent visibility is constrained to a network topology. Dynamics, such as changes in price, result from agent-level interactions that ubiquitously occur via market maker agents acting as liquidity providers. Two additional agents are considered: trend investors use a deep convolutional neural network paired with a deep Q-learning framework to inform trading decisions by analysing price history; and value investors use a static price-target to determine their trade directions and sizes. We demonstrate that our novel inclusion of a network topology with market makers facilitates explorations into various market structures. First, we present the model and an overview of its mechanics. Second, we validate our findings via comparison to the real-world: we demonstrate a fat-tailed distribution of price changes, auto-correlated volatility, a skew negatively correlated to market maker positioning, predictable price-history patterns and more. Finally, we demonstrate that our network-based model can lend insights into the effect of market-structure on price-action. For example, we show that markets with sparsely connected intermediaries can have a critical point of fragmentation, beyond which the market forms distinct clusters and arbitrage becomes rapidly possible between the prices of different market makers. A discussion is provided on future work that would be beneficial.
Fast FixMatch: Faster Semi-Supervised Learning with Curriculum Batch Size
Sep 07, 2023Advances in Semi-Supervised Learning (SSL) have almost entirely closed the gap between SSL and Supervised Learning at a fraction of the number of labels. However, recent performance improvements have often come \textit{at the cost of significantly increased training computation}. To address this, we propose Curriculum Batch Size (CBS), \textit{an unlabeled batch size curriculum which exploits the natural training dynamics of deep neural networks.} A small unlabeled batch size is used in the beginning of training and is gradually increased to the end of training. A fixed curriculum is used regardless of dataset, model or number of epochs, and reduced training computations is demonstrated on all settings. We apply CBS, strong labeled augmentation, Curriculum Pseudo Labeling (CPL) \citep{FlexMatch} to FixMatch \citep{FixMatch} and term the new SSL algorithm Fast FixMatch. We perform an ablation study to show that strong labeled augmentation and/or CPL do not significantly reduce training computations, but, in synergy with CBS, they achieve optimal performance. Fast FixMatch also achieves substantially higher data utilization compared to previous state-of-the-art. Fast FixMatch achieves between $2.1\times$ - $3.4\times$ reduced training computations on CIFAR-10 with all but 40, 250 and 4000 labels removed, compared to vanilla FixMatch, while attaining the same cited state-of-the-art error rate \citep{FixMatch}. Similar results are achieved for CIFAR-100, SVHN and STL-10. Finally, Fast MixMatch achieves between $2.6\times$ - $3.3\times$ reduced training computations in federated SSL tasks and online/streaming learning SSL tasks, which further demonstrate the generializbility of Fast MixMatch to different scenarios and tasks.
ChatLogo: A Large Language Model-Driven Hybrid Natural-Programming Language Interface for Agent-based Modeling and Programming
Aug 16, 2023Building on Papert (1980)'s idea of children talking to computers, we propose ChatLogo, a hybrid natural-programming language interface for agent-based modeling and programming. We build upon previous efforts to scaffold ABM & P learning and recent development in leveraging large language models (LLMs) to support the learning of computational programming. ChatLogo aims to support conversations with computers in a mix of natural and programming languages, provide a more user-friendly interface for novice learners, and keep the technical system from over-reliance on any single LLM. We introduced the main elements of our design: an intelligent command center, and a conversational interface to support creative expression. We discussed the presentation format and future work. Responding to the challenges of supporting open-ended constructionist learning of ABM & P and leveraging LLMs for educational purposes, we contribute to the field by proposing the first constructionist LLM-driven interface to support computational and complex systems thinking.
REX: Revisiting Budgeted Training with an Improved Schedule
Jul 09, 2021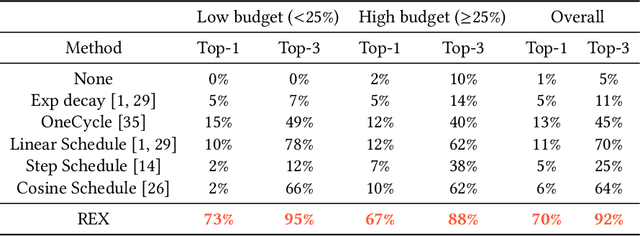

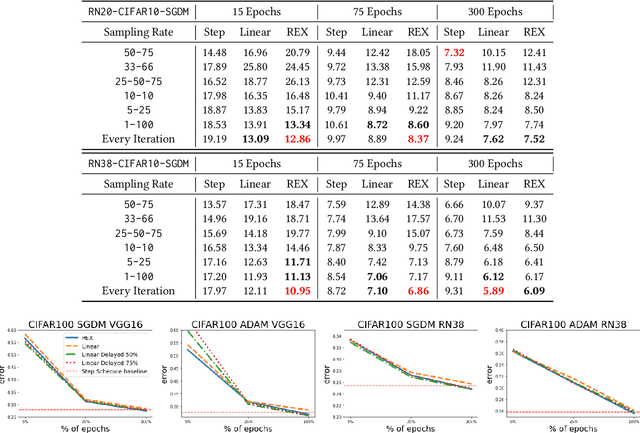
Deep learning practitioners often operate on a computational and monetary budget. Thus, it is critical to design optimization algorithms that perform well under any budget. The linear learning rate schedule is considered the best budget-aware schedule, as it outperforms most other schedules in the low budget regime. On the other hand, learning rate schedules -- such as the \texttt{30-60-90} step schedule -- are known to achieve high performance when the model can be trained for many epochs. Yet, it is often not known a priori whether one's budget will be large or small; thus, the optimal choice of learning rate schedule is made on a case-by-case basis. In this paper, we frame the learning rate schedule selection problem as a combination of $i)$ selecting a profile (i.e., the continuous function that models the learning rate schedule), and $ii)$ choosing a sampling rate (i.e., how frequently the learning rate is updated/sampled from this profile). We propose a novel profile and sampling rate combination called the Reflected Exponential (REX) schedule, which we evaluate across seven different experimental settings with both SGD and Adam optimizers. REX outperforms the linear schedule in the low budget regime, while matching or exceeding the performance of several state-of-the-art learning rate schedules (linear, step, exponential, cosine, step decay on plateau, and OneCycle) in both high and low budget regimes. Furthermore, REX requires no added computation, storage, or hyperparameters.
Mitigating deep double descent by concatenating inputs
Jul 02, 2021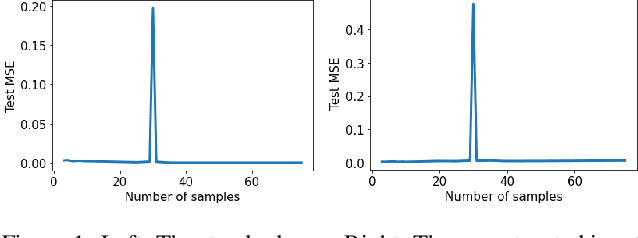
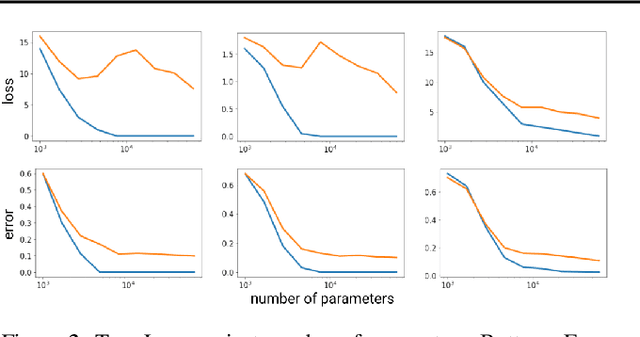
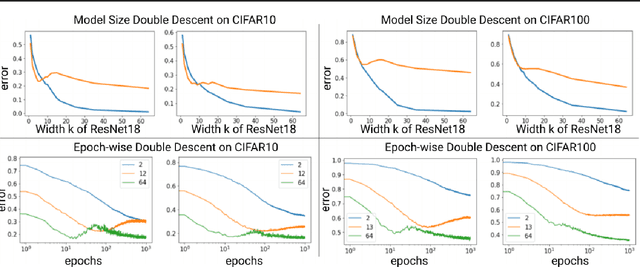
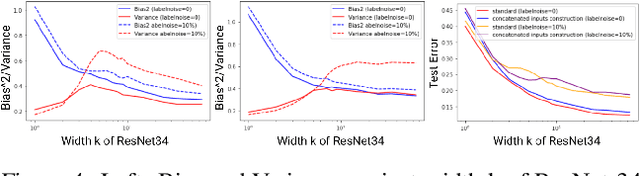
The double descent curve is one of the most intriguing properties of deep neural networks. It contrasts the classical bias-variance curve with the behavior of modern neural networks, occurring where the number of samples nears the number of parameters. In this work, we explore the connection between the double descent phenomena and the number of samples in the deep neural network setting. In particular, we propose a construction which augments the existing dataset by artificially increasing the number of samples. This construction empirically mitigates the double descent curve in this setting. We reproduce existing work on deep double descent, and observe a smooth descent into the overparameterized region for our construction. This occurs both with respect to the model size, and with respect to the number epochs.