 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from the Right Rollouts: Data Attribution for PPO-based LLM Post-Training
Apr 02, 2026Traditional RL algorithms like Proximal Policy Optimization (PPO) typically train on the entire rollout buffer, operating under the assumption that all generated episodes provide a beneficial optimization signal. However, these episodes frequently contain noisy or unfaithful reasoning, which can degrade model performance and slow down training. In this paper, we propose \textbf{Influence-Guided PPO (I-PPO)}, a novel framework that integrates data attribution into the RL post-training loop. By calculating an influence score for each episode using a gradient-based approximation, I-PPO identifies and eliminates episodes that are anti-aligned with a validation gradient. Our experiments demonstrate that I-PPO consistently outperforms SFT and PPO baselines. We show that our filtering process acts as an intrinsic early stopping mechanism, accelerating training efficiency while effectively reducing unfaithful CoT reasoning.
ComplLLM: Fine-tuning LLMs to Discover Complementary Signals for Decision-making
Feb 23, 2026Multi-agent decision pipelines can outperform single agent workflows when complementarity holds, i.e., different agents bring unique information to the table to inform a final decision. We propose ComplLLM, a post-training framework based on decision theory that fine-tunes a decision-assistant LLM using complementary information as reward to output signals that complement existing agent decisions. We validate ComplLLM on synthetic and real-world tasks involving domain experts, demonstrating how the approach recovers known complementary information and produces plausible explanations of complementary signals to support downstream decision-makers.
This human study did not involve human subjects: Validating LLM simulations as behavioral evidence
Feb 17, 2026A growing literature uses large language models (LLMs) as synthetic participants to generate cost-effective and nearly instantaneous responses in social science experiments. However, there is limited guidance on when such simulations support valid inference about human behavior. We contrast two strategies for obtaining valid estimates of causal effects and clarify the assumptions under which each is suitable for exploratory versus confirmatory research. Heuristic approaches seek to establish that simulated and observed human behavior are interchangeable through prompt engineering, model fine-tuning, and other repair strategies designed to reduce LLM-induced inaccuracies. While useful for many exploratory tasks, heuristic approaches lack the formal statistical guarantees typically required for confirmatory research. In contrast, statistical calibration combines auxiliary human data with statistical adjustments to account for discrepancies between observed and simulated responses. Under explicit assumptions, statistical calibration preserves validity and provides more precise estimates of causal effects at lower cost than experiments that rely solely on human participants. Yet the potential of both approaches depends on how well LLMs approximate the relevant populations. We consider what opportunities are overlooked when researchers focus myopically on substituting LLMs for human participants in a study.
Characterizing Photorealism and Artifacts in Diffusion Model-Generated Images
Feb 17, 2025



Diffusion model-generated images can appear indistinguishable from authentic photographs, but these images often contain artifacts and implausibilities that reveal their AI-generated provenance. Given the challenge to public trust in media posed by photorealistic AI-generated images, we conducted a large-scale experiment measuring human detection accuracy on 450 diffusion-model generated images and 149 real images. Based on collecting 749,828 observations and 34,675 comments from 50,444 participants, we find that scene complexity of an image, artifact types within an image, display time of an image, and human curation of AI-generated images all play significant roles in how accurately people distinguish real from AI-generated images. Additionally, we propose a taxonomy characterizing artifacts often appearing in images generated by diffusion models. Our empirical observations and taxonomy offer nuanced insights into the capabilities and limitations of diffusion models to generate photorealistic images in 2024.
The Value of Information in Human-AI Decision-making
Feb 10, 2025



Humans and AIs are often paired on decision tasks with the expectation of achieving complementary performance, where the combination of human and AI outperforms either one alone. However, how to improve performance of a human-AI team is often not clear without knowing more about what particular information and strategies each agent employs. We provide a decision-theoretic framework for characterizing the value of information -- and consequently, opportunities for agents to better exploit available information--in AI-assisted decision workflow. We demonstrate the use of the framework for model selection, empirical evaluation of human-AI performance, and explanation design. We propose a novel information-based instance-level explanation technique that adapts a conventional saliency-based explanation to explain information value in decision making.
A Computational Method for Measuring "Open Codes" in Qualitative Analysis
Nov 19, 2024



Qualitative analysis is critical to understanding human datasets in many social science disciplines. Open coding is an inductive qualitative process that identifies and interprets "open codes" from datasets. Yet, meeting methodological expectations (such as "as exhaustive as possible") can be challenging. While many machine learning (ML)/generative AI (GAI) studies have attempted to support open coding, few have systematically measured or evaluated GAI outcomes, increasing potential bias risks. Building on Grounded Theory and Thematic Analysis theories, we present a computational method to measure and identify potential biases from "open codes" systematically. Instead of operationalizing human expert results as the "ground truth," our method is built upon a team-based approach between human and machine coders. We experiment with two HCI datasets to establish this method's reliability by 1) comparing it with human analysis, and 2) analyzing its output stability. We present evidence-based suggestions and example workflows for ML/GAI to support open coding.
Measuring Free-Form Decision-Making Inconsistency of Language Models in Military Crisis Simulations
Oct 17, 2024



There is an increasing interest in using language models (LMs) for automated decision-making, with multiple countries actively testing LMs to aid in military crisis decision-making. To scrutinize relying on LM decision-making in high-stakes settings, we examine the inconsistency of responses in a crisis simulation ("wargame"), similar to reported tests conducted by the US military. Prior work illustrated escalatory tendencies and varying levels of aggression among LMs but were constrained to simulations with pre-defined actions. This was due to the challenges associated with quantitatively measuring semantic differences and evaluating natural language decision-making without relying on pre-defined actions. In this work, we query LMs for free form responses and use a metric based on BERTScore to measure response inconsistency quantitatively. Leveraging the benefits of BERTScore, we show that the inconsistency metric is robust to linguistic variations that preserve semantic meaning in a question-answering setting across text lengths. We show that all five tested LMs exhibit levels of inconsistency that indicate semantic differences, even when adjusting the wargame setting, anonymizing involved conflict countries, or adjusting the sampling temperature parameter $T$. Further qualitative evaluation shows that models recommend courses of action that share few to no similarities. We also study the impact of different prompt sensitivity variations on inconsistency at temperature $T = 0$. We find that inconsistency due to semantically equivalent prompt variations can exceed response inconsistency from temperature sampling for most studied models across different levels of ablations. Given the high-stakes nature of military deployment, we recommend further consideration be taken before using LMs to inform military decisions or other cases of high-stakes decision-making.
A Conceptual Framework for Ethical Evaluation of Machine Learning Systems
Aug 05, 2024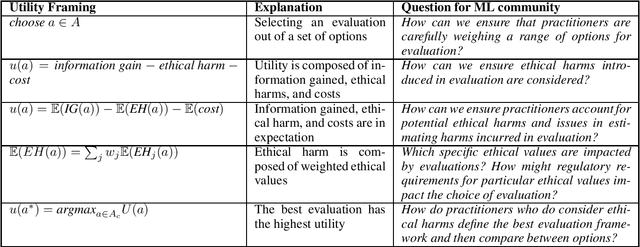
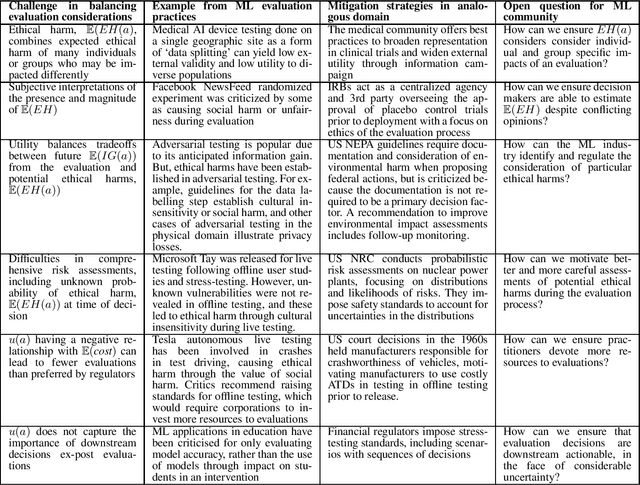
Research in Responsible AI has developed a range of principles and practices to ensure that machine learning systems are used in a manner that is ethical and aligned with human values. However, a critical yet often neglected aspect of ethical ML is the ethical implications that appear when designing evaluations of ML systems. For instance, teams may have to balance a trade-off between highly informative tests to ensure downstream product safety, with potential fairness harms inherent to the implemented testing procedures. We conceptualize ethics-related concerns in standard ML evaluation techniques. Specifically, we present a utility framework, characterizing the key trade-off in ethical evaluation as balancing information gain against potential ethical harms. The framework is then a tool for characterizing challenges teams face, and systematically disentangling competing considerations that teams seek to balance. Differentiating between different types of issues encountered in evaluation allows us to highlight best practices from analogous domains, such as clinical trials and automotive crash testing, which navigate these issues in ways that can offer inspiration to improve evaluation processes in ML. Our analysis underscores the critical need for development teams to deliberately assess and manage ethical complexities that arise during the evaluation of ML systems, and for the industry to move towards designing institutional policies to support ethical evaluations.
How to Distinguish AI-Generated Images from Authentic Photographs
Jun 12, 2024The high level of photorealism in state-of-the-art diffusion models like Midjourney, Stable Diffusion, and Firefly makes it difficult for untrained humans to distinguish between real photographs and AI-generated images. To address this problem, we designed a guide to help readers develop a more critical eye toward identifying artifacts, inconsistencies, and implausibilities that often appear in AI-generated images. The guide is organized into five categories of artifacts and implausibilities: anatomical, stylistic, functional, violations of physics, and sociocultural. For this guide, we generated 138 images with diffusion models, curated 9 images from social media, and curated 42 real photographs. These images showcase the kinds of cues that prompt suspicion towards the possibility an image is AI-generated and why it is often difficult to draw conclusions about an image's provenance without any context beyond the pixels in an image. Human-perceptible artifacts are not always present in AI-generated images, but this guide reveals artifacts and implausibilities that often emerge. By drawing attention to these kinds of artifacts and implausibilities, we aim to better equip people to distinguish AI-generated images from real photographs in the future.
Evaluating the Utility of Conformal Prediction Sets for AI-Advised Image Labeling
Jan 30, 2024



As deep neural networks are more commonly deployed in high-stakes domains, their lack of interpretability makes uncertainty quantification challenging. We investigate the effects of presenting conformal prediction sets$\unicode{x2013}$a method for generating valid confidence sets in distribution-free uncertainty quantification$\unicode{x2013}$to express uncertainty in AI-advised decision-making. Through a large online experiment, we compare the utility of conformal prediction sets to displays of Top-$1$ and Top-$k$ predictions for AI-advised image labeling. We find that the utility of prediction sets for accuracy varies with the difficulty of the task: while they result in accuracy on par with or less than Top-$1$ and Top-$k$ displays for easy images, prediction sets excel at assisting humans in labeling out-of-distribution (OOD) images especially when the set size is small. Our results empirically pinpoint the practical challenges of conformal prediction sets and provide implications on how to incorporate them for real-world decision-making.