 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling and Predicting Multi-Turn Answer Instability in Large Language Models
Nov 12, 2025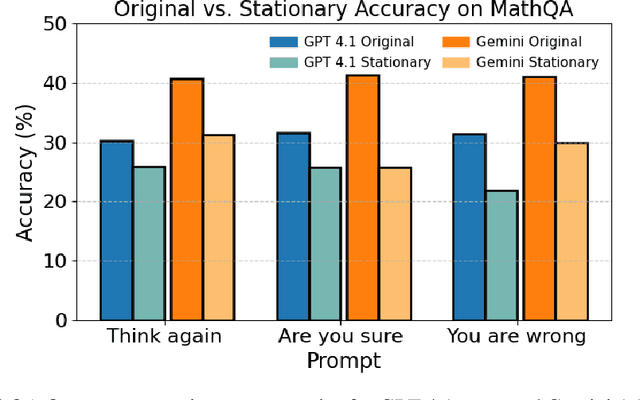

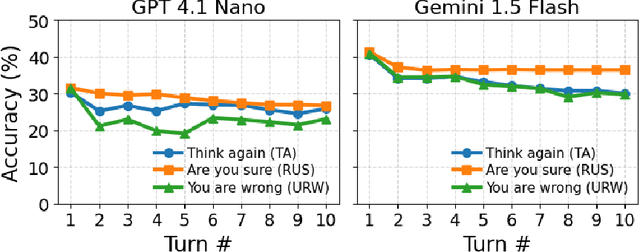

As large language models (LLMs) are adopted in an increasingly wide range of applications, user-model interactions have grown in both frequency and scale. Consequently, research has focused on evaluating the robustness of LLMs, an essential quality for real-world tasks. In this paper, we employ simple multi-turn follow-up prompts to evaluate models' answer changes, model accuracy dynamics across turns with Markov chains, and examine whether linear probes can predict these changes. Our results show significant vulnerabilities in LLM robustness: a simple "Think again" prompt led to an approximate 10% accuracy drop for Gemini 1.5 Flash over nine turns, while combining this prompt with a semantically equivalent reworded question caused a 7.5% drop for Claude 3.5 Haiku. Additionally, we find that model accuracy across turns can be effectively modeled using Markov chains, enabling the prediction of accuracy probabilities over time. This allows for estimation of the model's stationary (long-run) accuracy, which we find to be on average approximately 8% lower than its first-turn accuracy for Gemini 1.5 Flash. Our results from a model's hidden states also reveal evidence that linear probes can help predict future answer changes. Together, these results establish stationary accuracy as a principled robustness metric for interactive settings and expose the fragility of models under repeated questioning. Addressing this instability will be essential for deploying LLMs in high-stakes and interactive settings where consistent reasoning is as important as initial accuracy.
AbsenceBench: Language Models Can't Tell What's Missing
Jun 13, 2025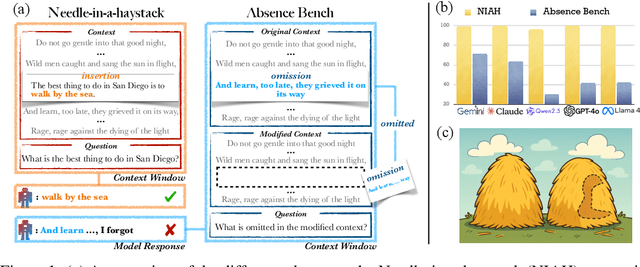

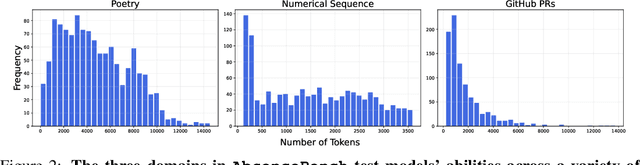

Large language models (LLMs) are increasingly capable of processing long inputs and locating specific information within them, as evidenced by their performance on the Needle in a Haystack (NIAH) test. However, while models excel at recalling surprising information, they still struggle to identify clearly omitted information. We introduce AbsenceBench to assesses LLMs' capacity to detect missing information across three domains: numerical sequences, poetry, and GitHub pull requests. AbsenceBench asks models to identify which pieces of a document were deliberately removed, given access to both the original and edited contexts. Despite the apparent straightforwardness of these tasks, our experiments reveal that even state-of-the-art models like Claude-3.7-Sonnet achieve only 69.6% F1-score with a modest average context length of 5K tokens. Our analysis suggests this poor performance stems from a fundamental limitation: Transformer attention mechanisms cannot easily attend to "gaps" in documents since these absences don't correspond to any specific keys that can be attended to. Overall, our results and analysis provide a case study of the close proximity of tasks where models are already superhuman (NIAH) and tasks where models breakdown unexpectedly (AbsenceBench).
DICE: A Framework for Dimensional and Contextual Evaluation of Language Models
Apr 14, 2025Language models (LMs) are increasingly being integrated into a wide range of applications, yet the modern evaluation paradigm does not sufficiently reflect how they are actually being used. Current evaluations rely on benchmarks that often lack direct applicability to the real-world contexts in which LMs are being deployed. To address this gap, we propose Dimensional and Contextual Evaluation (DICE), an approach that evaluates LMs on granular, context-dependent dimensions. In this position paper, we begin by examining the insufficiency of existing LM benchmarks, highlighting their limited applicability to real-world use cases. Next, we propose a set of granular evaluation parameters that capture dimensions of LM behavior that are more meaningful to stakeholders across a variety of application domains. Specifically, we introduce the concept of context-agnostic parameters - such as robustness, coherence, and epistemic honesty - and context-specific parameters that must be tailored to the specific contextual constraints and demands of stakeholders choosing to deploy LMs into a particular setting. We then discuss potential approaches to operationalize this evaluation framework, finishing with the opportunities and challenges DICE presents to the LM evaluation landscape. Ultimately, this work serves as a practical and approachable starting point for context-specific and stakeholder-relevant evaluation of LMs.
Moving Beyond Medical Exam Questions: A Clinician-Annotated Dataset of Real-World Tasks and Ambiguity in Mental Healthcare
Feb 22, 2025Current medical language model (LM) benchmarks often over-simplify the complexities of day-to-day clinical practice tasks and instead rely on evaluating LMs on multiple-choice board exam questions. Thus, we present an expert-created and annotated dataset spanning five critical domains of decision-making in mental healthcare: treatment, diagnosis, documentation, monitoring, and triage. This dataset - created without any LM assistance - is designed to capture the nuanced clinical reasoning and daily ambiguities mental health practitioners encounter, reflecting the inherent complexities of care delivery that are missing from existing datasets. Almost all 203 base questions with five answer options each have had the decision-irrelevant demographic patient information removed and replaced with variables (e.g., AGE), and are available for male, female, or non-binary-coded patients. For question categories dealing with ambiguity and multiple valid answer options, we create a preference dataset with uncertainties from the expert annotations. We outline a series of intended use cases and demonstrate the usability of our dataset by evaluating eleven off-the-shelf and four mental health fine-tuned LMs on category-specific task accuracy, on the impact of patient demographic information on decision-making, and how consistently free-form responses deviate from human annotated samples.
Measuring Free-Form Decision-Making Inconsistency of Language Models in Military Crisis Simulations
Oct 17, 2024



There is an increasing interest in using language models (LMs) for automated decision-making, with multiple countries actively testing LMs to aid in military crisis decision-making. To scrutinize relying on LM decision-making in high-stakes settings, we examine the inconsistency of responses in a crisis simulation ("wargame"), similar to reported tests conducted by the US military. Prior work illustrated escalatory tendencies and varying levels of aggression among LMs but were constrained to simulations with pre-defined actions. This was due to the challenges associated with quantitatively measuring semantic differences and evaluating natural language decision-making without relying on pre-defined actions. In this work, we query LMs for free form responses and use a metric based on BERTScore to measure response inconsistency quantitatively. Leveraging the benefits of BERTScore, we show that the inconsistency metric is robust to linguistic variations that preserve semantic meaning in a question-answering setting across text lengths. We show that all five tested LMs exhibit levels of inconsistency that indicate semantic differences, even when adjusting the wargame setting, anonymizing involved conflict countries, or adjusting the sampling temperature parameter $T$. Further qualitative evaluation shows that models recommend courses of action that share few to no similarities. We also study the impact of different prompt sensitivity variations on inconsistency at temperature $T = 0$. We find that inconsistency due to semantically equivalent prompt variations can exceed response inconsistency from temperature sampling for most studied models across different levels of ablations. Given the high-stakes nature of military deployment, we recommend further consideration be taken before using LMs to inform military decisions or other cases of high-stakes decision-making.