 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvoLearn: A Dataset of Constructivist Tutor-Student Dialogue
Jan 13, 2026In educational applications, LLMs exhibit several fundamental pedagogical limitations, such as their tendency to reveal solutions rather than support dialogic learning. We introduce ConvoLearn (https://huggingface.co/datasets/masharma/convolearn ), a dataset grounded in knowledge building theory that operationalizes six core pedagogical dimensions: cognitive engagement, formative assessment, accountability, cultural responsiveness, metacognition, and power dynamics. We construct a semi-synthetic dataset of 1250 tutor-student dialogues (20 turns each) in middle school Earth Science through controlled interactions between human teachers and a simulated student. Using QLoRA, we demonstrate that training on this dataset meaningfully shifts LLM behavior toward knowledge-building strategies. Human evaluation by 31 teachers shows our fine-tuned Mistral 7B (M = 4.10, SD = 1.03) significantly outperforms both its base version (M = 2.59, SD = 1.11) and Claude Sonnet 4.5 (M = 2.87, SD = 1.29) overall. This work establishes a potential framework to guide future development and evaluation of constructivist AI tutors.
Understanding, Protecting, and Augmenting Human Cognition with Generative AI: A Synthesis of the CHI 2025 Tools for Thought Workshop
Aug 28, 2025Generative AI (GenAI) radically expands the scope and capability of automation for work, education, and everyday tasks, a transformation posing both risks and opportunities for human cognition. How will human cognition change, and what opportunities are there for GenAI to augment it? Which theories, metrics, and other tools are needed to address these questions? The CHI 2025 workshop on Tools for Thought aimed to bridge an emerging science of how the use of GenAI affects human thought, from metacognition to critical thinking, memory, and creativity, with an emerging design practice for building GenAI tools that both protect and augment human thought. Fifty-six researchers, designers, and thinkers from across disciplines as well as industry and academia, along with 34 papers and portfolios, seeded a day of discussion, ideation, and community-building. We synthesize this material here to begin mapping the space of research and design opportunities and to catalyze a multidisciplinary community around this pressing area of research.
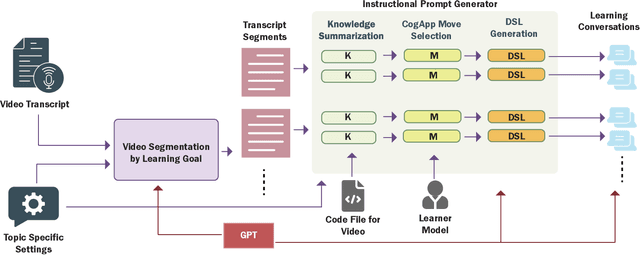
CogGen: A Learner-Centered Generative AI Architecture for Intelligent Tutoring with Programming Video
Jun 25, 2025We introduce CogGen, a learner-centered AI architecture that transforms programming videos into interactive, adaptive learning experiences by integrating student modeling with generative AI tutoring based on the Cognitive Apprenticeship framework. The architecture consists of three components: (1) video segmentation by learning goals, (2) a conversational tutoring engine applying Cognitive Apprenticeship strategies, and (3) a student model using Bayesian Knowledge Tracing to adapt instruction. Our technical evaluation demonstrates effective video segmentation accuracy and strong pedagogical alignment across knowledge, method, action, and interaction layers. Ablation studies confirm the necessity of each component in generating effective guidance. This work advances AI-powered tutoring by bridging structured student modeling with interactive AI conversations, offering a scalable approach to enhancing video-based programming education.
AI in the Writing Process: How Purposeful AI Support Fosters Student Writing
Jun 25, 2025The ubiquity of technologies like ChatGPT has raised concerns about their impact on student writing, particularly regarding reduced learner agency and superficial engagement with content. While standalone chat-based LLMs often produce suboptimal writing outcomes, evidence suggests that purposefully designed AI writing support tools can enhance the writing process. This paper investigates how different AI support approaches affect writers' sense of agency and depth of knowledge transformation. Through a randomized control trial with 90 undergraduate students, we compare three conditions: (1) a chat-based LLM writing assistant, (2) an integrated AI writing tool to support diverse subprocesses, and (3) a standard writing interface (control). Our findings demonstrate that, among AI-supported conditions, students using the integrated AI writing tool exhibited greater agency over their writing process and engaged in deeper knowledge transformation overall. These results suggest that thoughtfully designed AI writing support targeting specific aspects of the writing process can help students maintain ownership of their work while facilitating improved engagement with content.
AltCanvas: A Tile-Based Image Editor with Generative AI for Blind or Visually Impaired People
Aug 05, 2024



People with visual impairments often struggle to create content that relies heavily on visual elements, particularly when conveying spatial and structural information. Existing accessible drawing tools, which construct images line by line, are suitable for simple tasks like math but not for more expressive artwork. On the other hand, emerging generative AI-based text-to-image tools can produce expressive illustrations from descriptions in natural language, but they lack precise control over image composition and properties. To address this gap, our work integrates generative AI with a constructive approach that provides users with enhanced control and editing capabilities. Our system, AltCanvas, features a tile-based interface enabling users to construct visual scenes incrementally, with each tile representing an object within the scene. Users can add, edit, move, and arrange objects while receiving speech and audio feedback. Once completed, the scene can be rendered as a color illustration or as a vector for tactile graphic generation. Involving 14 blind or low-vision users in design and evaluation, we found that participants effectively used the AltCanvas workflow to create illustrations.
A Conceptual Framework for Ethical Evaluation of Machine Learning Systems
Aug 05, 2024Research in Responsible AI has developed a range of principles and practices to ensure that machine learning systems are used in a manner that is ethical and aligned with human values. However, a critical yet often neglected aspect of ethical ML is the ethical implications that appear when designing evaluations of ML systems. For instance, teams may have to balance a trade-off between highly informative tests to ensure downstream product safety, with potential fairness harms inherent to the implemented testing procedures. We conceptualize ethics-related concerns in standard ML evaluation techniques. Specifically, we present a utility framework, characterizing the key trade-off in ethical evaluation as balancing information gain against potential ethical harms. The framework is then a tool for characterizing challenges teams face, and systematically disentangling competing considerations that teams seek to balance. Differentiating between different types of issues encountered in evaluation allows us to highlight best practices from analogous domains, such as clinical trials and automotive crash testing, which navigate these issues in ways that can offer inspiration to improve evaluation processes in ML. Our analysis underscores the critical need for development teams to deliberately assess and manage ethical complexities that arise during the evaluation of ML systems, and for the industry to move towards designing institutional policies to support ethical evaluations.
Tutorly: Turning Programming Videos Into Apprenticeship Learning Environments with LLMs
May 21, 2024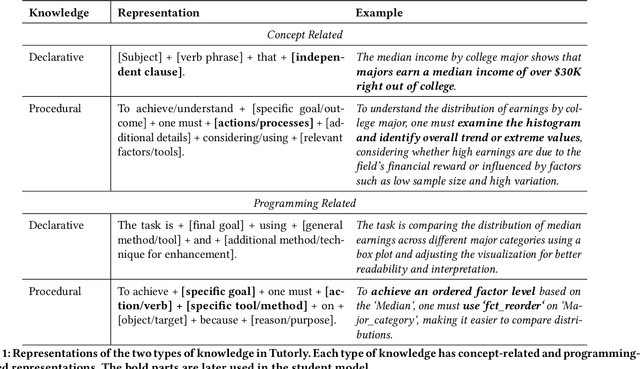
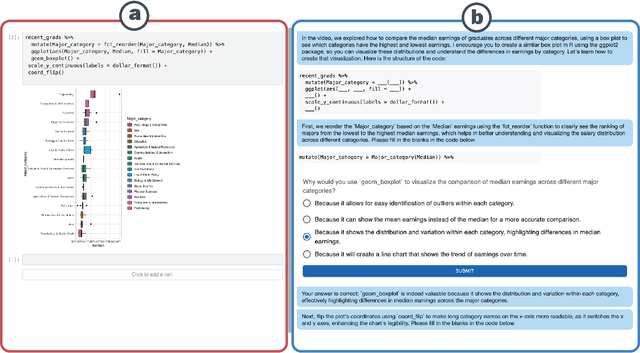
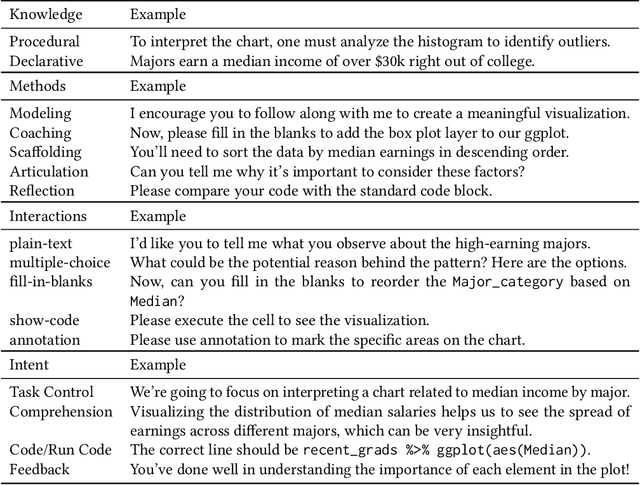
Online programming videos, including tutorials and streamcasts, are widely popular and contain a wealth of expert knowledge. However, effectively utilizing these resources to achieve targeted learning goals can be challenging. Unlike direct tutoring, video content lacks tailored guidance based on individual learning paces, personalized feedback, and interactive engagement necessary for support and monitoring. Our work transforms programming videos into one-on-one tutoring experiences using the cognitive apprenticeship framework. Tutorly, developed as a JupyterLab Plugin, allows learners to (1) set personalized learning goals, (2) engage in learning-by-doing through a conversational LLM-based mentor agent, (3) receive guidance and feedback based on a student model that steers the mentor moves. In a within-subject study with 16 participants learning exploratory data analysis from a streamcast, Tutorly significantly improved their performance from 61.9% to 76.6% based on a post-test questionnaire. Tutorly demonstrates the potential for enhancing programming video learning experiences with LLM and learner modeling.
Why and When LLM-Based Assistants Can Go Wrong: Investigating the Effectiveness of Prompt-Based Interactions for Software Help-Seeking
Feb 12, 2024Large Language Model (LLM) assistants, such as ChatGPT, have emerged as potential alternatives to search methods for helping users navigate complex, feature-rich software. LLMs use vast training data from domain-specific texts, software manuals, and code repositories to mimic human-like interactions, offering tailored assistance, including step-by-step instructions. In this work, we investigated LLM-generated software guidance through a within-subject experiment with 16 participants and follow-up interviews. We compared a baseline LLM assistant with an LLM optimized for particular software contexts, SoftAIBot, which also offered guidelines for constructing appropriate prompts. We assessed task completion, perceived accuracy, relevance, and trust. Surprisingly, although SoftAIBot outperformed the baseline LLM, our results revealed no significant difference in LLM usage and user perceptions with or without prompt guidelines and the integration of domain context. Most users struggled to understand how the prompt's text related to the LLM's responses and often followed the LLM's suggestions verbatim, even if they were incorrect. This resulted in difficulties when using the LLM's advice for software tasks, leading to low task completion rates. Our detailed analysis also revealed that users remained unaware of inaccuracies in the LLM's responses, indicating a gap between their lack of software expertise and their ability to evaluate the LLM's assistance. With the growing push for designing domain-specific LLM assistants, we emphasize the importance of incorporating explainable, context-aware cues into LLMs to help users understand prompt-based interactions, identify biases, and maximize the utility of LLM assistants.
Are Generative AI systems Capable of Supporting Information Needs of Patients?
Jan 31, 2024Patients managing a complex illness such as cancer face a complex information challenge where they not only must learn about their illness but also how to manage it. Close interaction with healthcare experts (radiologists, oncologists) can improve patient learning and thereby, their disease outcome. However, this approach is resource intensive and takes expert time away from other critical tasks. Given the recent advancements in Generative AI models aimed at improving the healthcare system, our work investigates whether and how generative visual question answering systems can responsibly support patient information needs in the context of radiology imaging data. We conducted a formative need-finding study in which participants discussed chest computed tomography (CT) scans and associated radiology reports of a fictitious close relative with a cardiothoracic radiologist. Using thematic analysis of the conversation between participants and medical experts, we identified commonly occurring themes across interactions, including clarifying medical terminology, locating the problems mentioned in the report in the scanned image, understanding disease prognosis, discussing the next diagnostic steps, and comparing treatment options. Based on these themes, we evaluated two state-of-the-art generative visual language models against the radiologist's responses. Our results reveal variability in the quality of responses generated by the models across various themes. We highlight the importance of patient-facing generative AI systems to accommodate a diverse range of conversational themes, catering to the real-world informational needs of patients.