 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo It For Me vs. Do It With Me: Investigating User Perceptions of Different Paradigms of Automation in Copilots for Feature-Rich Software
Apr 22, 2025



Large Language Model (LLM)-based in-application assistants, or copilots, can automate software tasks, but users often prefer learning by doing, raising questions about the optimal level of automation for an effective user experience. We investigated two automation paradigms by designing and implementing a fully automated copilot (AutoCopilot) and a semi-automated copilot (GuidedCopilot) that automates trivial steps while offering step-by-step visual guidance. In a user study (N=20) across data analysis and visual design tasks, GuidedCopilot outperformed AutoCopilot in user control, software utility, and learnability, especially for exploratory and creative tasks, while AutoCopilot saved time for simpler visual tasks. A follow-up design exploration (N=10) enhanced GuidedCopilot with task-and state-aware features, including in-context preview clips and adaptive instructions. Our findings highlight the critical role of user control and tailored guidance in designing the next generation of copilots that enhance productivity, support diverse skill levels, and foster deeper software engagement.
Why and When LLM-Based Assistants Can Go Wrong: Investigating the Effectiveness of Prompt-Based Interactions for Software Help-Seeking
Feb 12, 2024

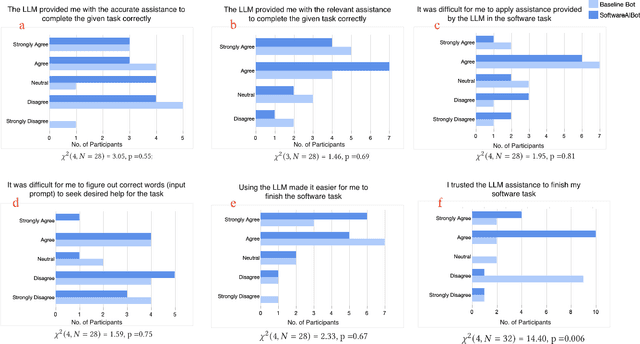

Large Language Model (LLM) assistants, such as ChatGPT, have emerged as potential alternatives to search methods for helping users navigate complex, feature-rich software. LLMs use vast training data from domain-specific texts, software manuals, and code repositories to mimic human-like interactions, offering tailored assistance, including step-by-step instructions. In this work, we investigated LLM-generated software guidance through a within-subject experiment with 16 participants and follow-up interviews. We compared a baseline LLM assistant with an LLM optimized for particular software contexts, SoftAIBot, which also offered guidelines for constructing appropriate prompts. We assessed task completion, perceived accuracy, relevance, and trust. Surprisingly, although SoftAIBot outperformed the baseline LLM, our results revealed no significant difference in LLM usage and user perceptions with or without prompt guidelines and the integration of domain context. Most users struggled to understand how the prompt's text related to the LLM's responses and often followed the LLM's suggestions verbatim, even if they were incorrect. This resulted in difficulties when using the LLM's advice for software tasks, leading to low task completion rates. Our detailed analysis also revealed that users remained unaware of inaccuracies in the LLM's responses, indicating a gap between their lack of software expertise and their ability to evaluate the LLM's assistance. With the growing push for designing domain-specific LLM assistants, we emphasize the importance of incorporating explainable, context-aware cues into LLMs to help users understand prompt-based interactions, identify biases, and maximize the utility of LLM assistants.
Video Moment Localization using Object Evidence and Reverse Captioning
Jun 18, 2020
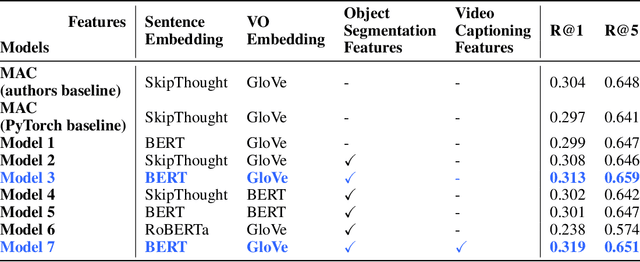
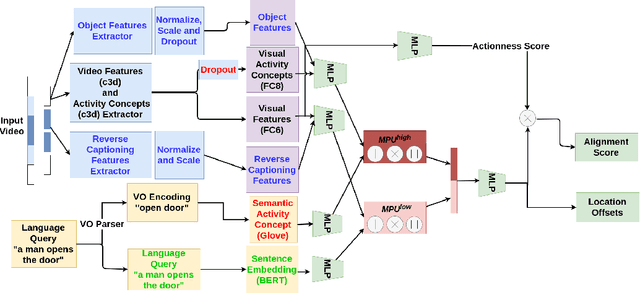

We address the problem of language-based temporal localization of moments in untrimmed videos. Compared to temporal localization with fixed categories, this problem is more challenging as the language-based queries have no predefined activity classes and may also contain complex descriptions. Current state-of-the-art model MAC addresses it by mining activity concepts from both video and language modalities. This method encodes the semantic activity concepts from the verb/object pair in a language query and leverages visual activity concepts from video activity classification prediction scores. We propose "Multi-faceted VideoMoment Localizer" (MML), an extension of MAC model by the introduction of visual object evidence via object segmentation masks and video understanding features via video captioning. Furthermore, we improve language modelling in sentence embedding. We experimented on Charades-STA dataset and identified that MML outperforms MAC baseline by 4.93% and 1.70% on R@1 and R@5metrics respectively. Our code and pre-trained model are publicly available at https://github.com/madhawav/MML.