 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Moment Localization using Object Evidence and Reverse Captioning
Jun 18, 2020
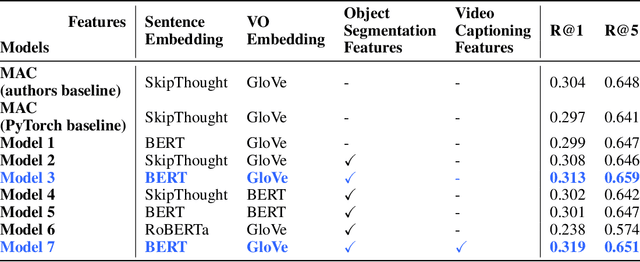
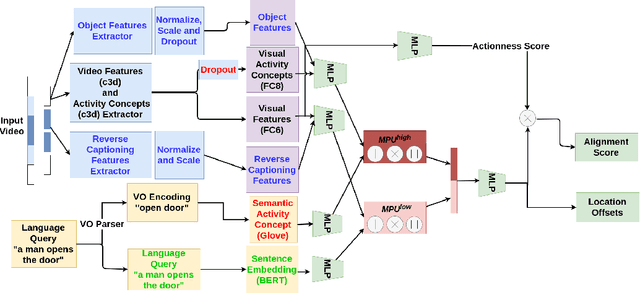

We address the problem of language-based temporal localization of moments in untrimmed videos. Compared to temporal localization with fixed categories, this problem is more challenging as the language-based queries have no predefined activity classes and may also contain complex descriptions. Current state-of-the-art model MAC addresses it by mining activity concepts from both video and language modalities. This method encodes the semantic activity concepts from the verb/object pair in a language query and leverages visual activity concepts from video activity classification prediction scores. We propose "Multi-faceted VideoMoment Localizer" (MML), an extension of MAC model by the introduction of visual object evidence via object segmentation masks and video understanding features via video captioning. Furthermore, we improve language modelling in sentence embedding. We experimented on Charades-STA dataset and identified that MML outperforms MAC baseline by 4.93% and 1.70% on R@1 and R@5metrics respectively. Our code and pre-trained model are publicly available at https://github.com/madhawav/MML.
STWalk: Learning Trajectory Representations in Temporal Graphs
Nov 11, 2017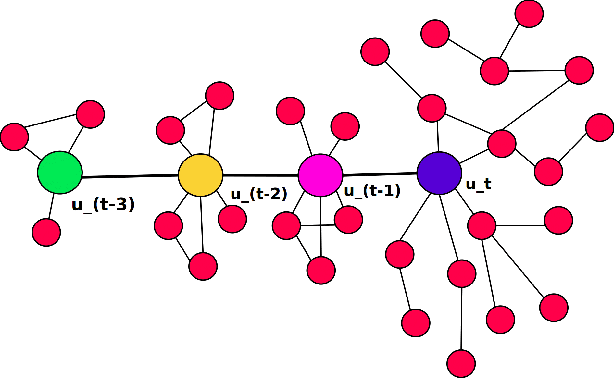
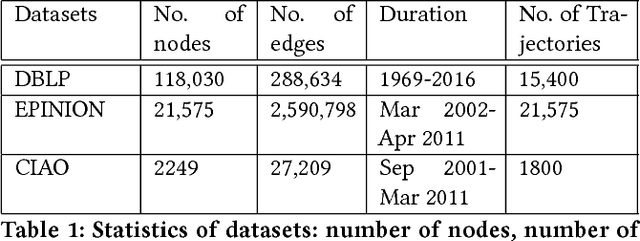
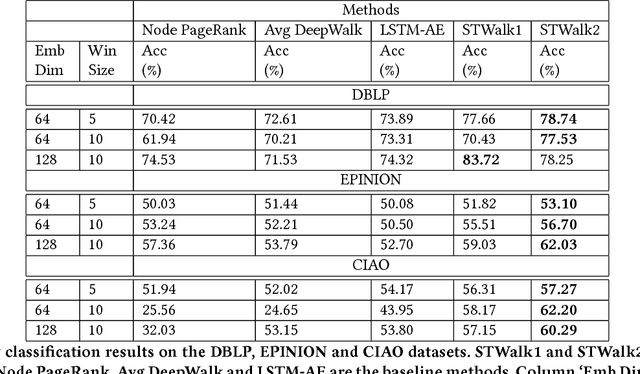
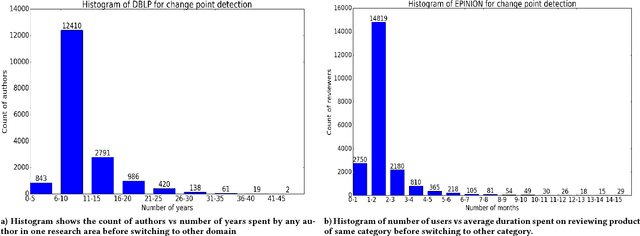
Analyzing the temporal behavior of nodes in time-varying graphs is useful for many applications such as targeted advertising, community evolution and outlier detection. In this paper, we present a novel approach, STWalk, for learning trajectory representations of nodes in temporal graphs. The proposed framework makes use of structural properties of graphs at current and previous time-steps to learn effective node trajectory representations. STWalk performs random walks on a graph at a given time step (called space-walk) as well as on graphs from past time-steps (called time-walk) to capture the spatio-temporal behavior of nodes. We propose two variants of STWalk to learn trajectory representations. In one algorithm, we perform space-walk and time-walk as part of a single step. In the other variant, we perform space-walk and time-walk separately and combine the learned representations to get the final trajectory embedding. Extensive experiments on three real-world temporal graph datasets validate the effectiveness of the learned representations when compared to three baseline methods. We also show the goodness of the learned trajectory embeddings for change point detection, as well as demonstrate that arithmetic operations on these trajectory representations yield interesting and interpretable results.
Survey of Recent Advances in Visual Question Answering
Sep 24, 2017

Visual Question Answering (VQA) presents a unique challenge as it requires the ability to understand and encode the multi-modal inputs - in terms of image processing and natural language processing. The algorithm further needs to learn how to perform reasoning over this multi-modal representation so it can answer the questions correctly. This paper presents a survey of different approaches proposed to solve the problem of Visual Question Answering. We also describe the current state of the art model in later part of paper. In particular, the paper describes the approaches taken by various algorithms to extract image features, text features and the way these are employed to predict answers. We also briefly discuss the experiments performed to evaluate the VQA models and report their performances on diverse datasets including newly released VQA2.0[8].