 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlan2Scene: Converting Floorplans to 3D Scenes
Jun 09, 2021



We address the task of converting a floorplan and a set of associated photos of a residence into a textured 3D mesh model, a task which we call Plan2Scene. Our system 1) lifts a floorplan image to a 3D mesh model; 2) synthesizes surface textures based on the input photos; and 3) infers textures for unobserved surfaces using a graph neural network architecture. To train and evaluate our system we create indoor surface texture datasets, and augment a dataset of floorplans and photos from prior work with rectified surface crops and additional annotations. Our approach handles the challenge of producing tileable textures for dominant surfaces such as floors, walls, and ceilings from a sparse set of unaligned photos that only partially cover the residence. Qualitative and quantitative evaluations show that our system produces realistic 3D interior models, outperforming baseline approaches on a suite of texture quality metrics and as measured by a holistic user study.
Video Moment Localization using Object Evidence and Reverse Captioning
Jun 18, 2020
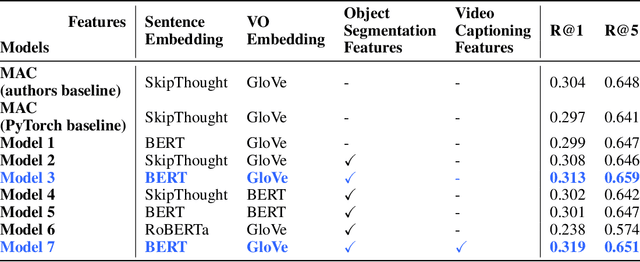
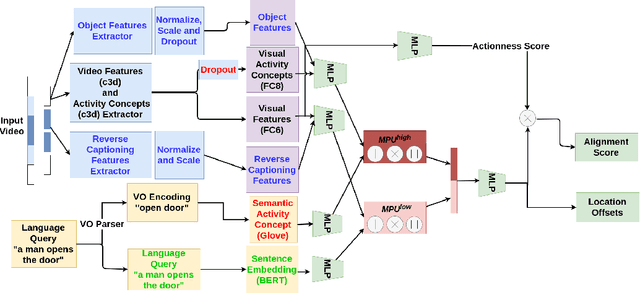

We address the problem of language-based temporal localization of moments in untrimmed videos. Compared to temporal localization with fixed categories, this problem is more challenging as the language-based queries have no predefined activity classes and may also contain complex descriptions. Current state-of-the-art model MAC addresses it by mining activity concepts from both video and language modalities. This method encodes the semantic activity concepts from the verb/object pair in a language query and leverages visual activity concepts from video activity classification prediction scores. We propose "Multi-faceted VideoMoment Localizer" (MML), an extension of MAC model by the introduction of visual object evidence via object segmentation masks and video understanding features via video captioning. Furthermore, we improve language modelling in sentence embedding. We experimented on Charades-STA dataset and identified that MML outperforms MAC baseline by 4.93% and 1.70% on R@1 and R@5metrics respectively. Our code and pre-trained model are publicly available at https://github.com/madhawav/MML.
Cognitive Analysis of 360 degree Surround Photos
Jan 17, 2019
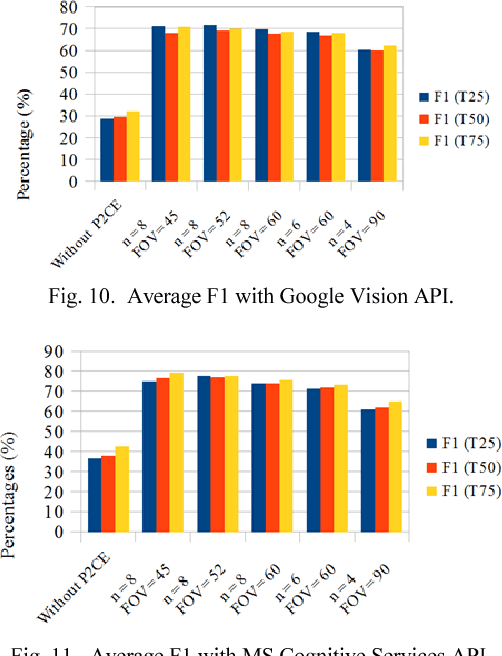
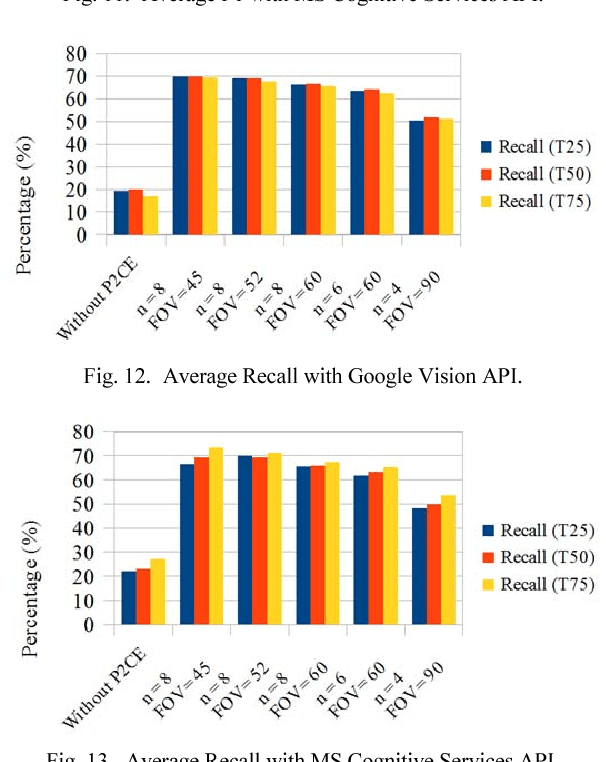
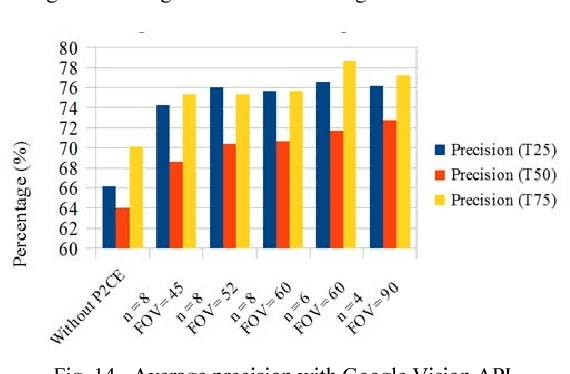
360 degrees surround photography or photospheres have taken the world by storm as the new media for content creation providing viewers rich, immersive experience compared to conventional photography. With the emergence of Virtual Reality as a mainstream trend, the 360 degrees photography is increasingly important to offer a practical approach to the general public to capture virtual reality ready content from their mobile phones without explicit tool support or knowledge. Even though the amount of 360-degree surround content being uploaded to the Internet continues to grow, there is no proper way to index them or to process them for further information. This is because of the difficulty in image processing the photospheres due to the distorted nature of objects embedded. This challenge lies in the way 360-degree panoramic photospheres are saved. This paper presents a unique, and innovative technique named Photosphere to Cognition Engine (P2CE), which allows cognitive analysis on 360-degree surround photos using existing image cognitive analysis algorithms and APIs designed for conventional photos. We have optimized the system using a wide variety of indoor and outdoor samples and extensive evaluation approaches. On average, P2CE provides up-to 100% growth in accuracy on image cognitive analysis of Photospheres over direct use of conventional non-photosphere based Image Cognition Systems.