 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeB-Rep Distance Functions (BR-DF): How to Represent a B-Rep Model by Volumetric Distance Functions?
Nov 18, 2025This paper presents a novel geometric representation for CAD Boundary Representation (B-Rep) based on volumetric distance functions, dubbed B-Rep Distance Functions (BR-DF). BR-DF encodes the surface mesh geometry of a CAD model as signed distance function (SDF). B-Rep vertices, edges, faces and their topology information are encoded as per-face unsigned distance functions (UDFs). An extension of the Marching Cubes algorithm converts BR-DF directly into watertight CAD B-Rep model (strictly speaking a faceted B-Rep model). A surprising characteristic of BR-DF is that this conversion process never fails. Leveraging the volumetric nature of BR-DF, we propose a multi-branch latent diffusion with 3D U-Net backbone for jointly generating the SDF and per-face UDFs of a BR-DF model. Our approach achieves comparable CAD generation performance against SOTA methods while reaching the unprecedented 100% success rate in producing (faceted) B-Rep models.
PuzzleFusion++: Auto-agglomerative 3D Fracture Assembly by Denoise and Verify
Jun 01, 2024
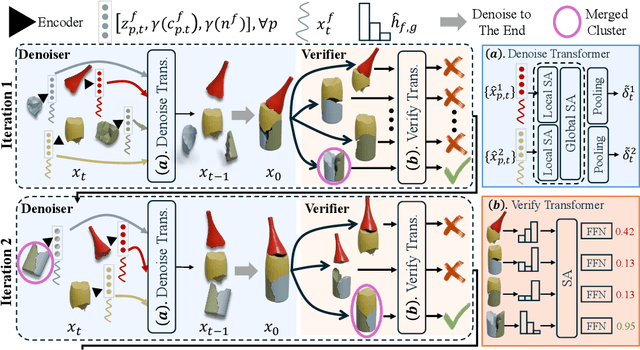


This paper proposes a novel "auto-agglomerative" 3D fracture assembly method, PuzzleFusion++, resembling how humans solve challenging spatial puzzles. Starting from individual fragments, the approach 1) aligns and merges fragments into larger groups akin to agglomerative clustering and 2) repeats the process iteratively in completing the assembly akin to auto-regressive methods. Concretely, a diffusion model denoises the 6-DoF alignment parameters of the fragments simultaneously, and a transformer model verifies and merges pairwise alignments into larger ones, whose process repeats iteratively. Extensive experiments on the Breaking Bad dataset show that PuzzleFusion++ outperforms all other state-of-the-art techniques by significant margins across all metrics, in particular by over 10% in part accuracy and 50% in Chamfer distance. The code will be available on our project page: https://puzzlefusion-plusplus.github.io.
RetailOpt: An Opt-In, Easy-to-Deploy Trajectory Estimation System Leveraging Smartphone Motion Data and Retail Facility Information
Apr 19, 2024



We present RetailOpt, a novel opt-in, easy-to-deploy system for tracking customer movements in indoor retail environments. The system utilizes information presently accessible to customers through smartphones and retail apps: motion data, store map, and purchase records. The approach eliminates the need for additional hardware installations/maintenance and ensures customers maintain full control of their data. Specifically, RetailOpt first employs inertial navigation to recover relative trajectories from smartphone motion data. The store map and purchase records are then cross-referenced to identify a list of visited shelves, providing anchors to localize the relative trajectories in a store through continuous and discrete optimization. We demonstrate the effectiveness of our system through systematic experiments in five diverse environments. The proposed system, if successful, would produce accurate customer movement data, essential for a broad range of retail applications, including customer behavior analysis and in-store navigation. The potential application could also extend to other domains such as entertainment and assistive technologies.
MapTracker: Tracking with Strided Memory Fusion for Consistent Vector HD Mapping
Mar 23, 2024



This paper presents a vector HD-mapping algorithm that formulates the mapping as a tracking task and uses a history of memory latents to ensure consistent reconstructions over time. Our method, MapTracker, accumulates a sensor stream into memory buffers of two latent representations: 1) Raster latents in the bird's-eye-view (BEV) space and 2) Vector latents over the road elements (i.e., pedestrian-crossings, lane-dividers, and road-boundaries). The approach borrows the query propagation paradigm from the tracking literature that explicitly associates tracked road elements from the previous frame to the current, while fusing a subset of memory latents selected with distance strides to further enhance temporal consistency. A vector latent is decoded to reconstruct the geometry of a road element. The paper further makes benchmark contributions by 1) Improving processing code for existing datasets to produce consistent ground truth with temporal alignments and 2) Augmenting existing mAP metrics with consistency checks. MapTracker significantly outperforms existing methods on both nuScenes and Agroverse2 datasets by over 8% and 19% on the conventional and the new consistency-aware metrics, respectively. The code will be available on our project page: https://map-tracker.github.io.
MVDiffusion++: A Dense High-resolution Multi-view Diffusion Model for Single or Sparse-view 3D Object Reconstruction
Feb 20, 2024
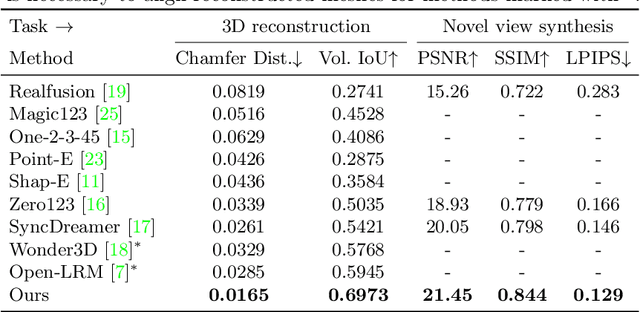
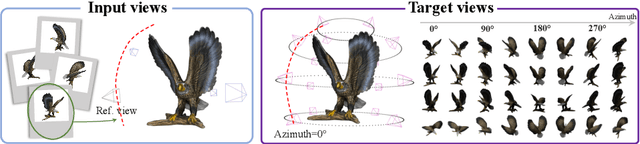
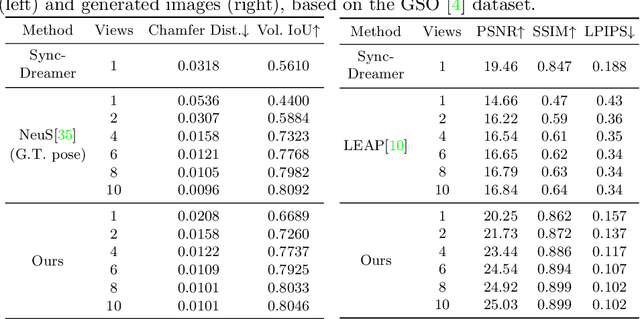
This paper presents a neural architecture MVDiffusion++ for 3D object reconstruction that synthesizes dense and high-resolution views of an object given one or a few images without camera poses. MVDiffusion++ achieves superior flexibility and scalability with two surprisingly simple ideas: 1) A ``pose-free architecture'' where standard self-attention among 2D latent features learns 3D consistency across an arbitrary number of conditional and generation views without explicitly using camera pose information; and 2) A ``view dropout strategy'' that discards a substantial number of output views during training, which reduces the training-time memory footprint and enables dense and high-resolution view synthesis at test time. We use the Objaverse for training and the Google Scanned Objects for evaluation with standard novel view synthesis and 3D reconstruction metrics, where MVDiffusion++ significantly outperforms the current state of the arts. We also demonstrate a text-to-3D application example by combining MVDiffusion++ with a text-to-image generative model.
BrepGen: A B-rep Generative Diffusion Model with Structured Latent Geometry
Jan 28, 2024



This paper presents BrepGen, a diffusion-based generative approach that directly outputs a Boundary representation (B-rep) Computer-Aided Design (CAD) model. BrepGen represents a B-rep model as a novel structured latent geometry in a hierarchical tree. With the root node representing a whole CAD solid, each element of a B-rep model (i.e., a face, an edge, or a vertex) progressively turns into a child-node from top to bottom. B-rep geometry information goes into the nodes as the global bounding box of each primitive along with a latent code describing the local geometric shape. The B-rep topology information is implicitly represented by node duplication. When two faces share an edge, the edge curve will appear twice in the tree, and a T-junction vertex with three incident edges appears six times in the tree with identical node features. Starting from the root and progressing to the leaf, BrepGen employs Transformer-based diffusion models to sequentially denoise node features while duplicated nodes are detected and merged, recovering the B-Rep topology information. Extensive experiments show that BrepGen sets a new milestone in CAD B-rep generation, surpassing existing methods on various benchmarks. Results on our newly collected furniture dataset further showcase its exceptional capability in generating complicated geometry. While previous methods were limited to generating simple prismatic shapes, BrepGen incorporates free-form and doubly-curved surfaces for the first time. Additional applications of BrepGen include CAD autocomplete and design interpolation. The code, pretrained models, and dataset will be released.
A-Scan2BIM: Assistive Scan to Building Information Modeling
Nov 30, 2023



This paper proposes an assistive system for architects that converts a large-scale point cloud into a standardized digital representation of a building for Building Information Modeling (BIM) applications. The process is known as Scan-to-BIM, which requires many hours of manual work even for a single building floor by a professional architect. Given its challenging nature, the paper focuses on helping architects on the Scan-to-BIM process, instead of replacing them. Concretely, we propose an assistive Scan-to-BIM system that takes the raw sensor data and edit history (including the current BIM model), then auto-regressively predicts a sequence of model editing operations as APIs of a professional BIM software (i.e., Autodesk Revit). The paper also presents the first building-scale Scan2BIM dataset that contains a sequence of model editing operations as the APIs of Autodesk Revit. The dataset contains 89 hours of Scan2BIM modeling processes by professional architects over 16 scenes, spanning over 35,000 m^2. We report our system's reconstruction quality with standard metrics, and we introduce a novel metric that measures how natural the order of reconstructed operations is. A simple modification to the reconstruction module helps improve performance, and our method is far superior to two other baselines in the order metric. We will release data, code, and models at a-scan2bim.github.io.
MVDiffusion: Enabling Holistic Multi-view Image Generation with Correspondence-Aware Diffusion
Jul 16, 2023



This paper introduces MVDiffusion, a simple yet effective multi-view image generation method for scenarios where pixel-to-pixel correspondences are available, such as perspective crops from panorama or multi-view images given geometry (depth maps and poses). Unlike prior models that rely on iterative image warping and inpainting, MVDiffusion concurrently generates all images with a global awareness, encompassing high resolution and rich content, effectively addressing the error accumulation prevalent in preceding models. MVDiffusion specifically incorporates a correspondence-aware attention mechanism, enabling effective cross-view interaction. This mechanism underpins three pivotal modules: 1) a generation module that produces low-resolution images while maintaining global correspondence, 2) an interpolation module that densifies spatial coverage between images, and 3) a super-resolution module that upscales into high-resolution outputs. In terms of panoramic imagery, MVDiffusion can generate high-resolution photorealistic images up to 1024$\times$1024 pixels. For geometry-conditioned multi-view image generation, MVDiffusion demonstrates the first method capable of generating a textured map of a scene mesh. The project page is at https://mvdiffusion.github.io.
Hierarchical Neural Coding for Controllable CAD Model Generation
Jun 30, 2023



This paper presents a novel generative model for Computer Aided Design (CAD) that 1) represents high-level design concepts of a CAD model as a three-level hierarchical tree of neural codes, from global part arrangement down to local curve geometry; and 2) controls the generation or completion of CAD models by specifying the target design using a code tree. Concretely, a novel variant of a vector quantized VAE with "masked skip connection" extracts design variations as neural codebooks at three levels. Two-stage cascaded auto-regressive transformers learn to generate code trees from incomplete CAD models and then complete CAD models following the intended design. Extensive experiments demonstrate superior performance on conventional tasks such as random generation while enabling novel interaction capabilities on conditional generation tasks. The code is available at https://github.com/samxuxiang/hnc-cad.
PolyDiffuse: Polygonal Shape Reconstruction via Guided Set Diffusion Models
Jun 02, 2023This paper presents PolyDiffuse, a novel structured reconstruction algorithm that transforms visual sensor data into polygonal shapes with Diffusion Models (DM), an emerging machinery amid exploding generative AI, while formulating reconstruction as a generation process conditioned on sensor data. The task of structured reconstruction poses two fundamental challenges to DM: 1) A structured geometry is a ``set'' (e.g., a set of polygons for a floorplan geometry), where a sample of $N$ elements has $N!$ different but equivalent representations, making the denoising highly ambiguous; and 2) A ``reconstruction'' task has a single solution, where an initial noise needs to be chosen carefully, while any initial noise works for a generation task. Our technical contribution is the introduction of a Guided Set Diffusion Model where 1) the forward diffusion process learns guidance networks to control noise injection so that one representation of a sample remains distinct from its other permutation variants, thus resolving denoising ambiguity; and 2) the reverse denoising process reconstructs polygonal shapes, initialized and directed by the guidance networks, as a conditional generation process subject to the sensor data. We have evaluated our approach for reconstructing two types of polygonal shapes: floorplan as a set of polygons and HD map for autonomous cars as a set of polylines. Through extensive experiments on standard benchmarks, we demonstrate that PolyDiffuse significantly advances the current state of the art and enables broader practical applications.