 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMVDiffusion++: A Dense High-resolution Multi-view Diffusion Model for Single or Sparse-view 3D Object Reconstruction
Paper and Code

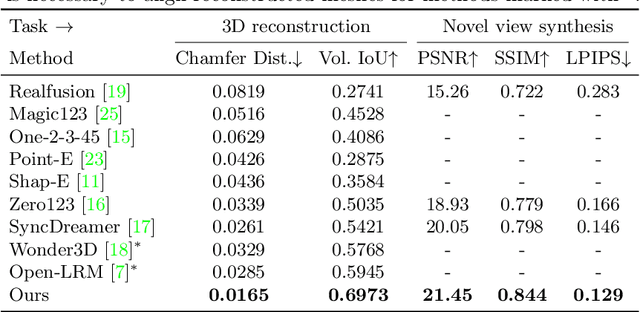
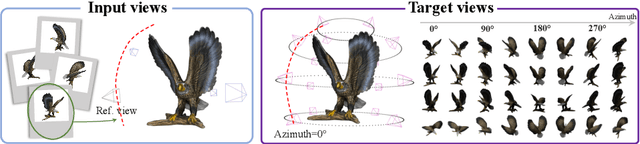
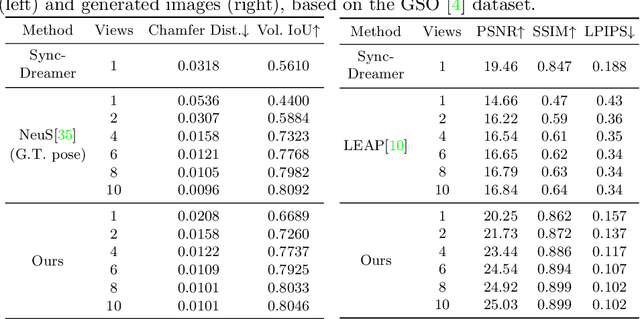
This paper presents a neural architecture MVDiffusion++ for 3D object reconstruction that synthesizes dense and high-resolution views of an object given one or a few images without camera poses. MVDiffusion++ achieves superior flexibility and scalability with two surprisingly simple ideas: 1) A ``pose-free architecture'' where standard self-attention among 2D latent features learns 3D consistency across an arbitrary number of conditional and generation views without explicitly using camera pose information; and 2) A ``view dropout strategy'' that discards a substantial number of output views during training, which reduces the training-time memory footprint and enables dense and high-resolution view synthesis at test time. We use the Objaverse for training and the Google Scanned Objects for evaluation with standard novel view synthesis and 3D reconstruction metrics, where MVDiffusion++ significantly outperforms the current state of the arts. We also demonstrate a text-to-3D application example by combining MVDiffusion++ with a text-to-image generative model.