 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObjaverse++: Curated 3D Object Dataset with Quality Annotations
Apr 09, 2025This paper presents Objaverse++, a curated subset of Objaverse enhanced with detailed attribute annotations by human experts. Recent advances in 3D content generation have been driven by large-scale datasets such as Objaverse, which contains over 800,000 3D objects collected from the Internet. Although Objaverse represents the largest available 3D asset collection, its utility is limited by the predominance of low-quality models. To address this limitation, we manually annotate 10,000 3D objects with detailed attributes, including aesthetic quality scores, texture color classifications, multi-object composition flags, transparency characteristics, etc. Then, we trained a neural network capable of annotating the tags for the rest of the Objaverse dataset. Through experiments and a user study on generation results, we demonstrate that models pre-trained on our quality-focused subset achieve better performance than those trained on the larger dataset of Objaverse in image-to-3D generation tasks. In addition, by comparing multiple subsets of training data filtered by our tags, our results show that the higher the data quality, the faster the training loss converges. These findings suggest that careful curation and rich annotation can compensate for the raw dataset size, potentially offering a more efficient path to develop 3D generative models. We release our enhanced dataset of approximately 500,000 curated 3D models to facilitate further research on various downstream tasks in 3D computer vision. In the near future, we aim to extend our annotations to cover the entire Objaverse dataset.
Cosmos-Transfer1: Conditional World Generation with Adaptive Multimodal Control
Mar 18, 2025We introduce Cosmos-Transfer, a conditional world generation model that can generate world simulations based on multiple spatial control inputs of various modalities such as segmentation, depth, and edge. In the design, the spatial conditional scheme is adaptive and customizable. It allows weighting different conditional inputs differently at different spatial locations. This enables highly controllable world generation and finds use in various world-to-world transfer use cases, including Sim2Real. We conduct extensive evaluations to analyze the proposed model and demonstrate its applications for Physical AI, including robotics Sim2Real and autonomous vehicle data enrichment. We further demonstrate an inference scaling strategy to achieve real-time world generation with an NVIDIA GB200 NVL72 rack. To help accelerate research development in the field, we open-source our models and code at https://github.com/nvidia-cosmos/cosmos-transfer1.
Cosmos World Foundation Model Platform for Physical AI
Jan 07, 2025



Physical AI needs to be trained digitally first. It needs a digital twin of itself, the policy model, and a digital twin of the world, the world model. In this paper, we present the Cosmos World Foundation Model Platform to help developers build customized world models for their Physical AI setups. We position a world foundation model as a general-purpose world model that can be fine-tuned into customized world models for downstream applications. Our platform covers a video curation pipeline, pre-trained world foundation models, examples of post-training of pre-trained world foundation models, and video tokenizers. To help Physical AI builders solve the most critical problems of our society, we make our platform open-source and our models open-weight with permissive licenses available via https://github.com/NVIDIA/Cosmos.
CamFreeDiff: Camera-free Image to Panorama Generation with Diffusion Model
Jul 09, 2024



This paper introduces Camera-free Diffusion (CamFreeDiff) model for 360-degree image outpainting from a single camera-free image and text description. This method distinguishes itself from existing strategies, such as MVDiffusion, by eliminating the requirement for predefined camera poses. Instead, our model incorporates a mechanism for predicting homography directly within the multi-view diffusion framework. The core of our approach is to formulate camera estimation by predicting the homography transformation from the input view to a predefined canonical view. The homography provides point-level correspondences between the input image and targeting panoramic images, allowing connections enforced by correspondence-aware attention in a fully differentiable manner. Qualitative and quantitative experimental results demonstrate our model's strong robustness and generalization ability for 360-degree image outpainting in the challenging context of camera-free inputs.
MVDiffusion++: A Dense High-resolution Multi-view Diffusion Model for Single or Sparse-view 3D Object Reconstruction
Feb 20, 2024
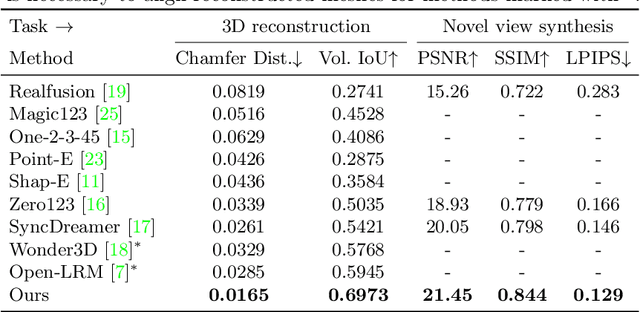
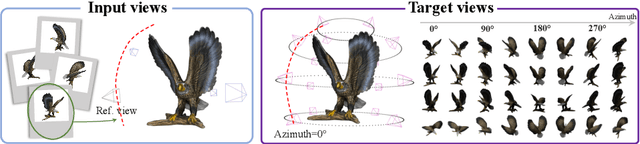
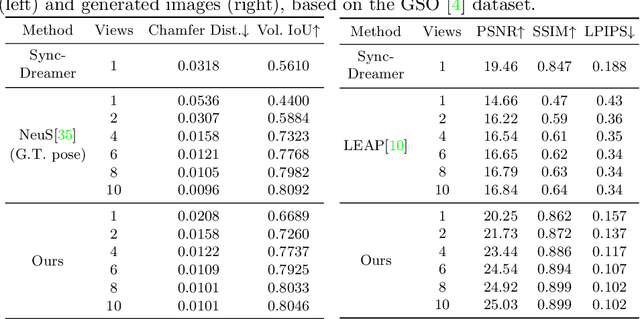
This paper presents a neural architecture MVDiffusion++ for 3D object reconstruction that synthesizes dense and high-resolution views of an object given one or a few images without camera poses. MVDiffusion++ achieves superior flexibility and scalability with two surprisingly simple ideas: 1) A ``pose-free architecture'' where standard self-attention among 2D latent features learns 3D consistency across an arbitrary number of conditional and generation views without explicitly using camera pose information; and 2) A ``view dropout strategy'' that discards a substantial number of output views during training, which reduces the training-time memory footprint and enables dense and high-resolution view synthesis at test time. We use the Objaverse for training and the Google Scanned Objects for evaluation with standard novel view synthesis and 3D reconstruction metrics, where MVDiffusion++ significantly outperforms the current state of the arts. We also demonstrate a text-to-3D application example by combining MVDiffusion++ with a text-to-image generative model.
BESA: Pruning Large Language Models with Blockwise Parameter-Efficient Sparsity Allocation
Feb 18, 2024Large language models (LLMs) have demonstrated outstanding performance in various tasks, such as text summarization, text question-answering, and etc. While their performance is impressive, the computational footprint due to their vast number of parameters can be prohibitive. Existing solutions such as SparseGPT and Wanda attempt to alleviate this issue through weight pruning. However, their layer-wise approach results in significant perturbation to the model's output and requires meticulous hyperparameter tuning, such as the pruning rate, which can adversely affect overall model performance. To address this, this paper introduces a novel LLM pruning technique dubbed blockwise parameter-efficient sparsity allocation (BESA) by applying a blockwise reconstruction loss. In contrast to the typical layer-wise pruning techniques, BESA is characterized by two distinctive attributes: i) it targets the overall pruning error with respect to individual transformer blocks, and ii) it allocates layer-specific sparsity in a differentiable manner, both of which ensure reduced performance degradation after pruning. Our experiments show that BESA achieves state-of-the-art performance, efficiently pruning LLMs like LLaMA1, and LLaMA2 with 7B to 70B parameters on a single A100 GPU in just five hours. Code is available at \href{https://github.com/OpenGVLab/LLMPrune-BESA}{here}.
MVDiffusion: Enabling Holistic Multi-view Image Generation with Correspondence-Aware Diffusion
Jul 16, 2023



This paper introduces MVDiffusion, a simple yet effective multi-view image generation method for scenarios where pixel-to-pixel correspondences are available, such as perspective crops from panorama or multi-view images given geometry (depth maps and poses). Unlike prior models that rely on iterative image warping and inpainting, MVDiffusion concurrently generates all images with a global awareness, encompassing high resolution and rich content, effectively addressing the error accumulation prevalent in preceding models. MVDiffusion specifically incorporates a correspondence-aware attention mechanism, enabling effective cross-view interaction. This mechanism underpins three pivotal modules: 1) a generation module that produces low-resolution images while maintaining global correspondence, 2) an interpolation module that densifies spatial coverage between images, and 3) a super-resolution module that upscales into high-resolution outputs. In terms of panoramic imagery, MVDiffusion can generate high-resolution photorealistic images up to 1024$\times$1024 pixels. For geometry-conditioned multi-view image generation, MVDiffusion demonstrates the first method capable of generating a textured map of a scene mesh. The project page is at https://mvdiffusion.github.io.
NeuMap: Neural Coordinate Mapping by Auto-Transdecoder for Camera Localization
Nov 21, 2022



This paper presents an end-to-end neural mapping method for camera localization, encoding a whole scene into a grid of latent codes, with which a Transformer-based auto-decoder regresses 3D coordinates of query pixels. State-of-the-art camera localization methods require each scene to be stored as a 3D point cloud with per-point features, which takes several gigabytes of storage per scene. While compression is possible, the performance drops significantly at high compression rates. NeuMap achieves extremely high compression rates with minimal performance drop by using 1) learnable latent codes to store scene information and 2) a scene-agnostic Transformer-based auto-decoder to infer coordinates for a query pixel. The scene-agnostic network design also learns robust matching priors by training with large-scale data, and further allows us to just optimize the codes quickly for a new scene while fixing the network weights. Extensive evaluations with five benchmarks show that NeuMap outperforms all the other coordinate regression methods significantly and reaches similar performance as the feature matching methods while having a much smaller scene representation size. For example, NeuMap achieves 39.1% accuracy in Aachen night benchmark with only 6MB of data, while other compelling methods require 100MB or a few gigabytes and fail completely under high compression settings. The codes are available at https://github.com/Tangshitao/NeuMap.
RenderNet: Visual Relocalization Using Virtual Viewpoints in Large-Scale Indoor Environments
Jul 26, 2022
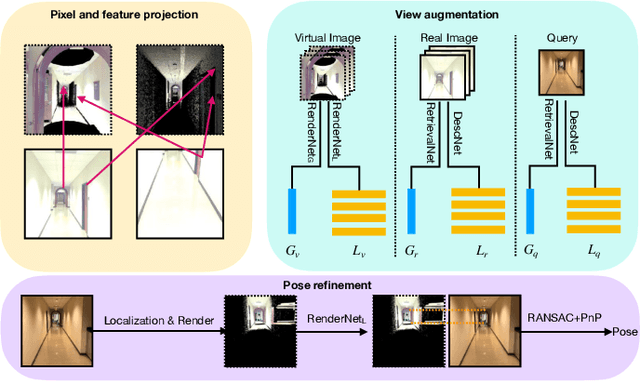
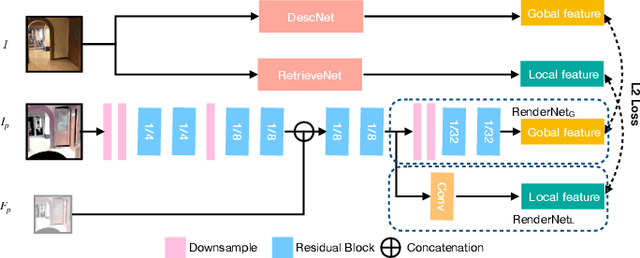

Visual relocalization has been a widely discussed problem in 3D vision: given a pre-constructed 3D visual map, the 6 DoF (Degrees-of-Freedom) pose of a query image is estimated. Relocalization in large-scale indoor environments enables attractive applications such as augmented reality and robot navigation. However, appearance changes fast in such environments when the camera moves, which is challenging for the relocalization system. To address this problem, we propose a virtual view synthesis-based approach, RenderNet, to enrich the database and refine poses regarding this particular scenario. Instead of rendering real images which requires high-quality 3D models, we opt to directly render the needed global and local features of virtual viewpoints and apply them in the subsequent image retrieval and feature matching operations respectively. The proposed method can largely improve the performance in large-scale indoor environments, e.g., achieving an improvement of 7.1\% and 12.2\% on the Inloc dataset.
QuadTree Attention for Vision Transformers
Jan 08, 2022
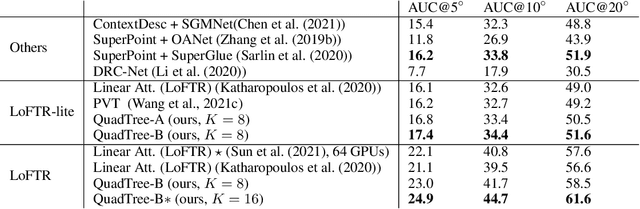
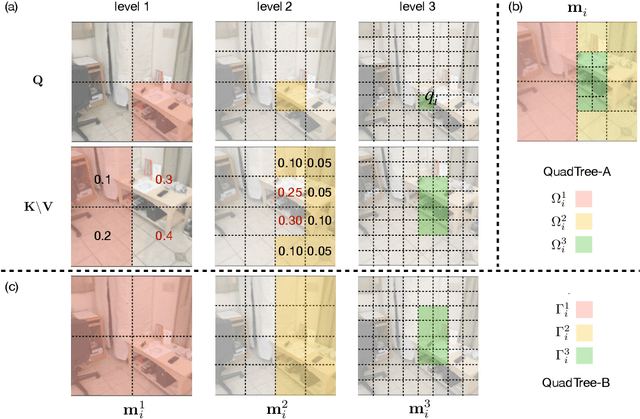
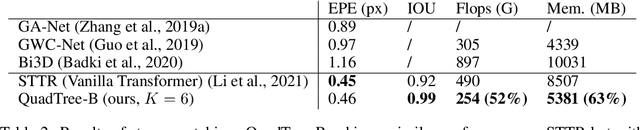
Transformers have been successful in many vision tasks, thanks to their capability of capturing long-range dependency. However, their quadratic computational complexity poses a major obstacle for applying them to vision tasks requiring dense predictions, such as object detection, feature matching, stereo, etc. We introduce QuadTree Attention, which reduces the computational complexity from quadratic to linear. Our quadtree transformer builds token pyramids and computes attention in a coarse-to-fine manner. At each level, the top K patches with the highest attention scores are selected, such that at the next level, attention is only evaluated within the relevant regions corresponding to these top K patches. We demonstrate that quadtree attention achieves state-of-the-art performance in various vision tasks, e.g. with 4.0% improvement in feature matching on ScanNet, about 50% flops reduction in stereo matching, 0.4-1.5% improvement in top-1 accuracy on ImageNet classification, 1.2-1.8% improvement on COCO object detection, and 0.7-2.4% improvement on semantic segmentation over previous state-of-the-art transformers. The codes are available at https://github.com/Tangshitao/QuadtreeAttention}{https://github.com/Tangshitao/QuadtreeAttention.