 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMVDiffusion++: A Dense High-resolution Multi-view Diffusion Model for Single or Sparse-view 3D Object Reconstruction
Feb 20, 2024
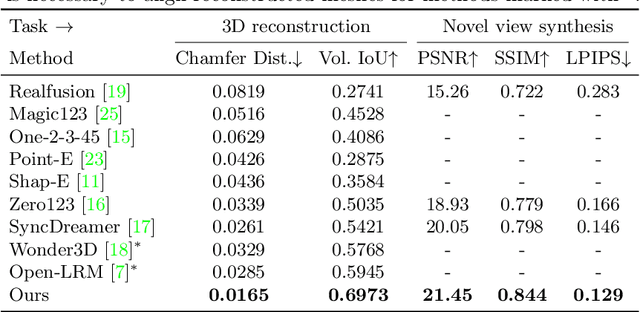
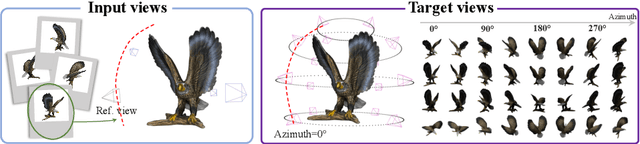
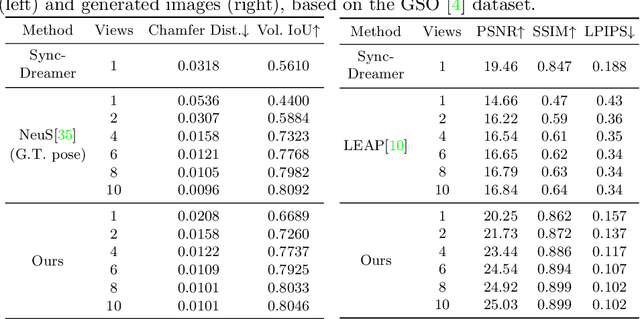
This paper presents a neural architecture MVDiffusion++ for 3D object reconstruction that synthesizes dense and high-resolution views of an object given one or a few images without camera poses. MVDiffusion++ achieves superior flexibility and scalability with two surprisingly simple ideas: 1) A ``pose-free architecture'' where standard self-attention among 2D latent features learns 3D consistency across an arbitrary number of conditional and generation views without explicitly using camera pose information; and 2) A ``view dropout strategy'' that discards a substantial number of output views during training, which reduces the training-time memory footprint and enables dense and high-resolution view synthesis at test time. We use the Objaverse for training and the Google Scanned Objects for evaluation with standard novel view synthesis and 3D reconstruction metrics, where MVDiffusion++ significantly outperforms the current state of the arts. We also demonstrate a text-to-3D application example by combining MVDiffusion++ with a text-to-image generative model.
RCP: Recurrent Closest Point for Scene Flow Estimation on 3D Point Clouds
May 24, 2022
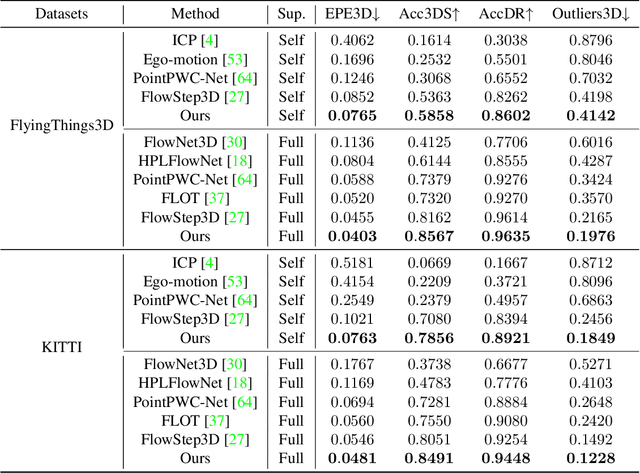
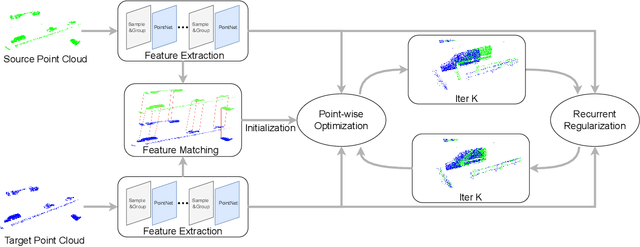
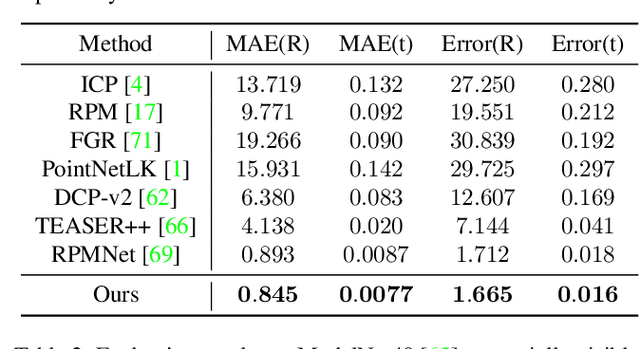
3D motion estimation including scene flow and point cloud registration has drawn increasing interest. Inspired by 2D flow estimation, recent methods employ deep neural networks to construct the cost volume for estimating accurate 3D flow. However, these methods are limited by the fact that it is difficult to define a search window on point clouds because of the irregular data structure. In this paper, we avoid this irregularity by a simple yet effective method.We decompose the problem into two interlaced stages, where the 3D flows are optimized point-wisely at the first stage and then globally regularized in a recurrent network at the second stage. Therefore, the recurrent network only receives the regular point-wise information as the input. In the experiments, we evaluate the proposed method on both the 3D scene flow estimation and the point cloud registration task. For 3D scene flow estimation, we make comparisons on the widely used FlyingThings3D and KITTIdatasets. For point cloud registration, we follow previous works and evaluate the data pairs with large pose and partially overlapping from ModelNet40. The results show that our method outperforms the previous method and achieves a new state-of-the-art performance on both 3D scene flow estimation and point cloud registration, which demonstrates the superiority of the proposed zero-order method on irregular point cloud data.
Learning Camera Localization via Dense Scene Matching
Mar 31, 2021
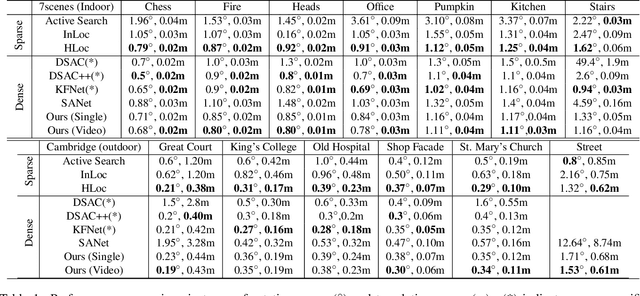
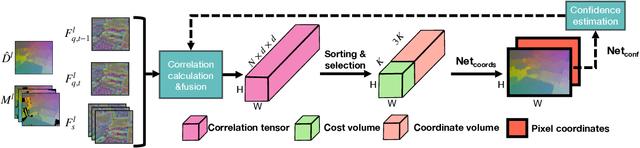

Camera localization aims to estimate 6 DoF camera poses from RGB images. Traditional methods detect and match interest points between a query image and a pre-built 3D model. Recent learning-based approaches encode scene structures into a specific convolutional neural network (CNN) and thus are able to predict dense coordinates from RGB images. However, most of them require re-training or re-adaption for a new scene and have difficulties in handling large-scale scenes due to limited network capacity. We present a new method for scene agnostic camera localization using dense scene matching (DSM), where a cost volume is constructed between a query image and a scene. The cost volume and the corresponding coordinates are processed by a CNN to predict dense coordinates. Camera poses can then be solved by PnP algorithms. In addition, our method can be extended to temporal domain, which leads to extra performance boost during testing time. Our scene-agnostic approach achieves comparable accuracy as the existing scene-specific approaches, such as KFNet, on the 7scenes and Cambridge benchmark. This approach also remarkably outperforms state-of-the-art scene-agnostic dense coordinate regression network SANet. The Code is available at https://github.com/Tangshitao/Dense-Scene-Matching.
DRO: Deep Recurrent Optimizer for Structure-from-Motion
Mar 25, 2021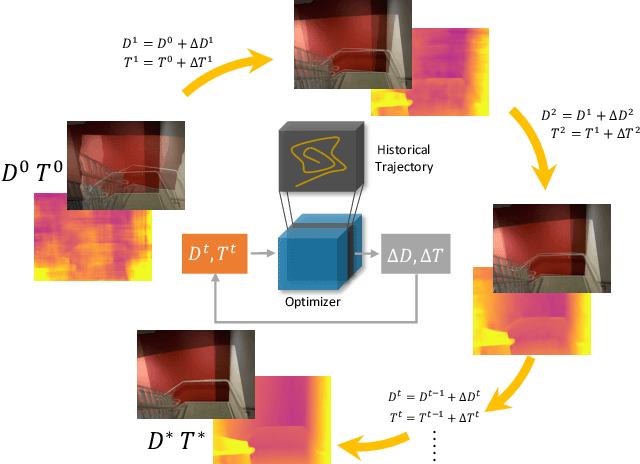
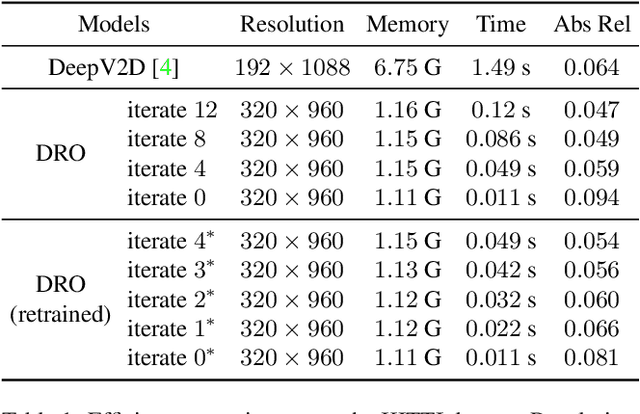
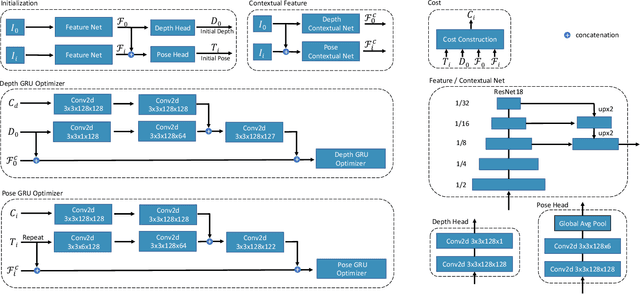
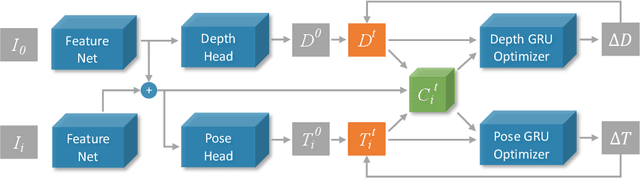
There are increasing interests of studying the structure-from-motion (SfM) problem with machine learning techniques. While earlier methods directly learn a mapping from images to depth maps and camera poses, more recent works enforce multi-view geometry through optimization embed in the learning framework. This paper presents a novel optimization method based on recurrent neural networks to further exploit the potential of neural networks in SfM. Our neural optimizer alternatively updates the depth and camera poses through iterations to minimize a feature-metric cost. Two gated recurrent units are designed to trace the historical information during the iterations. Our network works as a zeroth-order optimizer, where the computation and memory expensive cost volume or gradients are avoided. Experiments demonstrate that our recurrent optimizer effectively reduces the feature-metric cost while refining the depth and poses. Our method outperforms previous methods and is more efficient in computation and memory consumption than cost-volume-based methods. The code of our method will be made public.
LSM: Learning Subspace Minimization for Low-level Vision
Apr 20, 2020


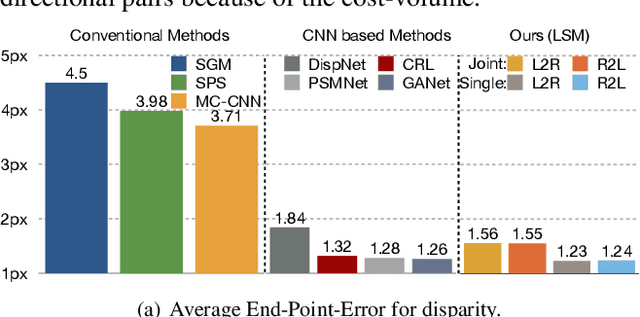
We study the energy minimization problem in low-level vision tasks from a novel perspective. We replace the heuristic regularization term with a learnable subspace constraint, and preserve the data term to exploit domain knowledge derived from the first principle of a task. This learning subspace minimization (LSM) framework unifies the network structures and the parameters for many low-level vision tasks, which allows us to train a single network for multiple tasks simultaneously with completely shared parameters, and even generalizes the trained network to an unseen task as long as its data term can be formulated. We demonstrate our LSM framework on four low-level tasks including interactive image segmentation, video segmentation, stereo matching, and optical flow, and validate the network on various datasets. The experiments show that the proposed LSM generates state-of-the-art results with smaller model size, faster training convergence, and real-time inference.
BA-Net: Dense Bundle Adjustment Network
Jun 13, 2018



This paper introduces a neural network to solve the structure-from-motion (SfM) problem via feature bundle adjustment (BA), which explicitly enforces multi-view geometry constraints in the form of feature reprojection error. The whole pipeline is differentiable, so that the network can learn suitable feature representations that make the BA problem more trackable. Furthermore, this work introduces a novel depth parameterization to recover dense per-pixel depth. The network first generates some bases depth maps according to the input image, and optimizes the final depth as a linear combination of these bases via feature BA. The bases depth map generator is also learned via end-to-end training. The whole system nicely combines domain knowledge (i.e. hard-coded multi-view geometry constraints) and machine learning (i.e. feature learning and basis depth map generator learning) to address the challenging SfM problem. Experiments on large scale real data prove the success of the proposed method.
GSLAM: Initialization-robust Monocular Visual SLAM via Global Structure-from-Motion
Oct 19, 2017
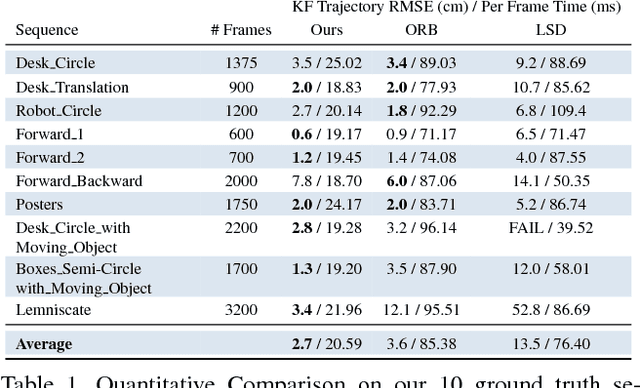
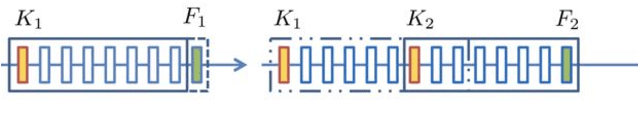

Many monocular visual SLAM algorithms are derived from incremental structure-from-motion (SfM) methods. This work proposes a novel monocular SLAM method which integrates recent advances made in global SfM. In particular, we present two main contributions to visual SLAM. First, we solve the visual odometry problem by a novel rank-1 matrix factorization technique which is more robust to the errors in map initialization. Second, we adopt a recent global SfM method for the pose-graph optimization, which leads to a multi-stage linear formulation and enables L1 optimization for better robustness to false loops. The combination of these two approaches generates more robust reconstruction and is significantly faster (4X) than recent state-of-the-art SLAM systems. We also present a new dataset recorded with ground truth camera motion in a Vicon motion capture room, and compare our method to prior systems on it and established benchmark datasets.
Linear Global Translation Estimation with Feature Tracks
Sep 04, 2015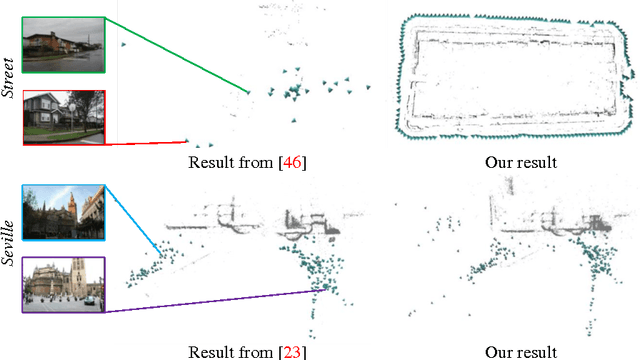

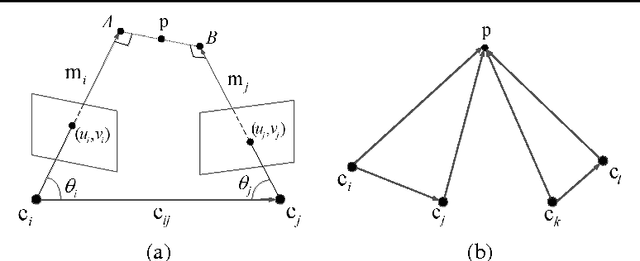
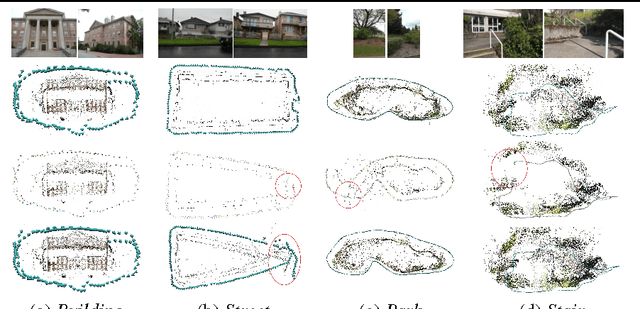
This paper derives a novel linear position constraint for cameras seeing a common scene point, which leads to a direct linear method for global camera translation estimation. Unlike previous solutions, this method deals with collinear camera motion and weak image association at the same time. The final linear formulation does not involve the coordinates of scene points, which makes it efficient even for large scale data. We solve the linear equation based on $L_1$ norm, which makes our system more robust to outliers in essential matrices and feature correspondences. We experiment this method on both sequentially captured images and unordered Internet images. The experiments demonstrate its strength in robustness, accuracy, and efficiency.