 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeB-Rep Distance Functions (BR-DF): How to Represent a B-Rep Model by Volumetric Distance Functions?
Nov 18, 2025This paper presents a novel geometric representation for CAD Boundary Representation (B-Rep) based on volumetric distance functions, dubbed B-Rep Distance Functions (BR-DF). BR-DF encodes the surface mesh geometry of a CAD model as signed distance function (SDF). B-Rep vertices, edges, faces and their topology information are encoded as per-face unsigned distance functions (UDFs). An extension of the Marching Cubes algorithm converts BR-DF directly into watertight CAD B-Rep model (strictly speaking a faceted B-Rep model). A surprising characteristic of BR-DF is that this conversion process never fails. Leveraging the volumetric nature of BR-DF, we propose a multi-branch latent diffusion with 3D U-Net backbone for jointly generating the SDF and per-face UDFs of a BR-DF model. Our approach achieves comparable CAD generation performance against SOTA methods while reaching the unprecedented 100% success rate in producing (faceted) B-Rep models.
SceneScript: Reconstructing Scenes With An Autoregressive Structured Language Model
Mar 19, 2024

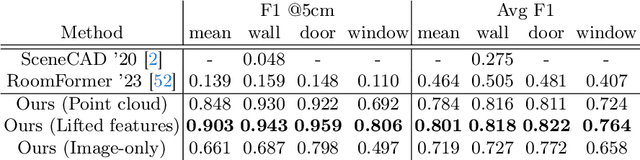
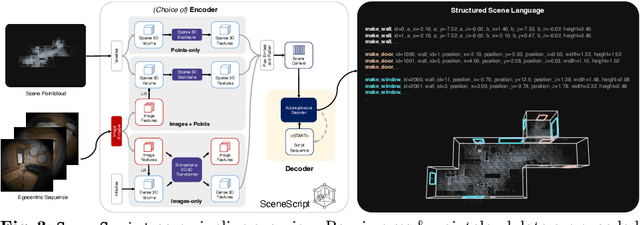
We introduce SceneScript, a method that directly produces full scene models as a sequence of structured language commands using an autoregressive, token-based approach. Our proposed scene representation is inspired by recent successes in transformers & LLMs, and departs from more traditional methods which commonly describe scenes as meshes, voxel grids, point clouds or radiance fields. Our method infers the set of structured language commands directly from encoded visual data using a scene language encoder-decoder architecture. To train SceneScript, we generate and release a large-scale synthetic dataset called Aria Synthetic Environments consisting of 100k high-quality in-door scenes, with photorealistic and ground-truth annotated renders of egocentric scene walkthroughs. Our method gives state-of-the art results in architectural layout estimation, and competitive results in 3D object detection. Lastly, we explore an advantage for SceneScript, which is the ability to readily adapt to new commands via simple additions to the structured language, which we illustrate for tasks such as coarse 3D object part reconstruction.
MVDiffusion++: A Dense High-resolution Multi-view Diffusion Model for Single or Sparse-view 3D Object Reconstruction
Feb 20, 2024
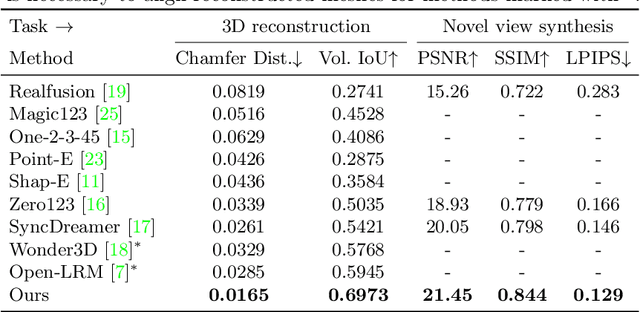
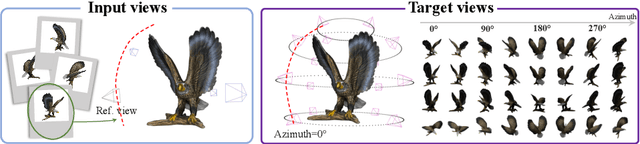
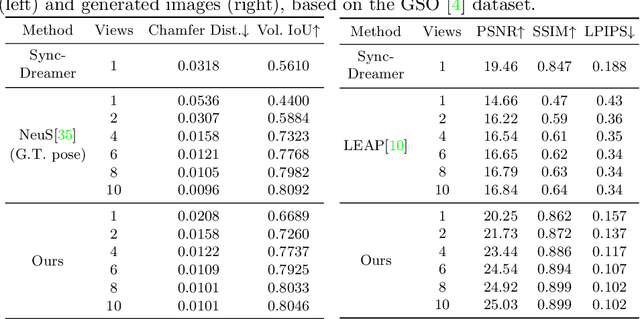
This paper presents a neural architecture MVDiffusion++ for 3D object reconstruction that synthesizes dense and high-resolution views of an object given one or a few images without camera poses. MVDiffusion++ achieves superior flexibility and scalability with two surprisingly simple ideas: 1) A ``pose-free architecture'' where standard self-attention among 2D latent features learns 3D consistency across an arbitrary number of conditional and generation views without explicitly using camera pose information; and 2) A ``view dropout strategy'' that discards a substantial number of output views during training, which reduces the training-time memory footprint and enables dense and high-resolution view synthesis at test time. We use the Objaverse for training and the Google Scanned Objects for evaluation with standard novel view synthesis and 3D reconstruction metrics, where MVDiffusion++ significantly outperforms the current state of the arts. We also demonstrate a text-to-3D application example by combining MVDiffusion++ with a text-to-image generative model.
MVDiffusion: Enabling Holistic Multi-view Image Generation with Correspondence-Aware Diffusion
Jul 16, 2023



This paper introduces MVDiffusion, a simple yet effective multi-view image generation method for scenarios where pixel-to-pixel correspondences are available, such as perspective crops from panorama or multi-view images given geometry (depth maps and poses). Unlike prior models that rely on iterative image warping and inpainting, MVDiffusion concurrently generates all images with a global awareness, encompassing high resolution and rich content, effectively addressing the error accumulation prevalent in preceding models. MVDiffusion specifically incorporates a correspondence-aware attention mechanism, enabling effective cross-view interaction. This mechanism underpins three pivotal modules: 1) a generation module that produces low-resolution images while maintaining global correspondence, 2) an interpolation module that densifies spatial coverage between images, and 3) a super-resolution module that upscales into high-resolution outputs. In terms of panoramic imagery, MVDiffusion can generate high-resolution photorealistic images up to 1024$\times$1024 pixels. For geometry-conditioned multi-view image generation, MVDiffusion demonstrates the first method capable of generating a textured map of a scene mesh. The project page is at https://mvdiffusion.github.io.
Structured Outdoor Architecture Reconstruction by Exploration and Classification
Aug 18, 2021


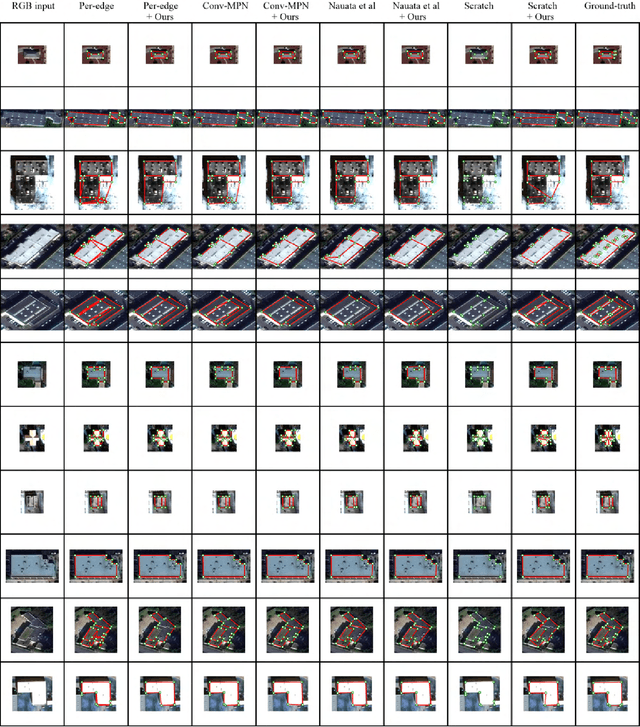
This paper presents an explore-and-classify framework for structured architectural reconstruction from an aerial image. Starting from a potentially imperfect building reconstruction by an existing algorithm, our approach 1) explores the space of building models by modifying the reconstruction via heuristic actions; 2) learns to classify the correctness of building models while generating classification labels based on the ground-truth, and 3) repeat. At test time, we iterate exploration and classification, seeking for a result with the best classification score. We evaluate the approach using initial reconstructions by two baselines and two state-of-the-art reconstruction algorithms. Qualitative and quantitative evaluations demonstrate that our approach consistently improves the reconstruction quality from every initial reconstruction.
Conv-MPN: Convolutional Message Passing Neural Network for Structured Outdoor Architecture Reconstruction
Dec 04, 2019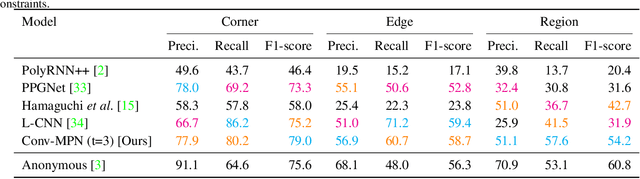
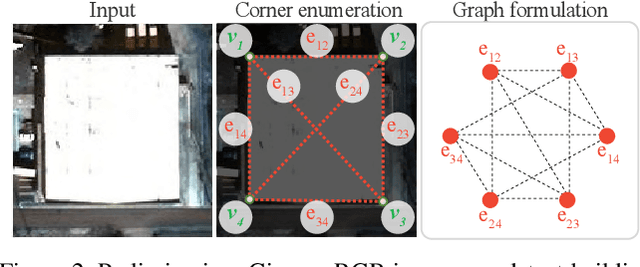
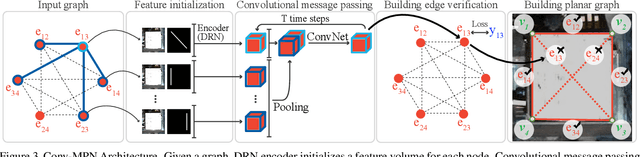

This paper proposes a novel message passing neural (MPN) architecture Conv-MPN, which reconstructs an outdoor building as a planar graph from a single RGB image. Conv-MPN is specifically designed for cases where nodes of a graph have explicit spatial embedding. In our problem, nodes correspond to building edges in an image. Conv-MPN is different from MPN in that 1) the feature associated with a node is represented as a feature volume instead of a 1D vector; and 2) convolutions encode messages instead of fully connected layers. Conv-MPN learns to select a true subset of nodes (i.e., building edges) to reconstruct a building planar graph. Our qualitative and quantitative evaluations over 2,000 buildings show that Conv-MPN makes significant improvements over the existing fully neural solutions. We believe that the paper has a potential to open a new line of graph neural network research for structured geometry reconstruction.