 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShapeR: Robust Conditional 3D Shape Generation from Casual Captures
Jan 16, 2026Recent advances in 3D shape generation have achieved impressive results, but most existing methods rely on clean, unoccluded, and well-segmented inputs. Such conditions are rarely met in real-world scenarios. We present ShapeR, a novel approach for conditional 3D object shape generation from casually captured sequences. Given an image sequence, we leverage off-the-shelf visual-inertial SLAM, 3D detection algorithms, and vision-language models to extract, for each object, a set of sparse SLAM points, posed multi-view images, and machine-generated captions. A rectified flow transformer trained to effectively condition on these modalities then generates high-fidelity metric 3D shapes. To ensure robustness to the challenges of casually captured data, we employ a range of techniques including on-the-fly compositional augmentations, a curriculum training scheme spanning object- and scene-level datasets, and strategies to handle background clutter. Additionally, we introduce a new evaluation benchmark comprising 178 in-the-wild objects across 7 real-world scenes with geometry annotations. Experiments show that ShapeR significantly outperforms existing approaches in this challenging setting, achieving an improvement of 2.7x in Chamfer distance compared to state of the art.
ReScene4D: Temporally Consistent Semantic Instance Segmentation of Evolving Indoor 3D Scenes
Jan 16, 2026Indoor environments evolve as objects move, appear, or disappear. Capturing these dynamics requires maintaining temporally consistent instance identities across intermittently captured 3D scans, even when changes are unobserved. We introduce and formalize the task of temporally sparse 4D indoor semantic instance segmentation (SIS), which jointly segments, identifies, and temporally associates object instances. This setting poses a challenge for existing 3DSIS methods, which require a discrete matching step due to their lack of temporal reasoning, and for 4D LiDAR approaches, which perform poorly due to their reliance on high-frequency temporal measurements that are uncommon in the longer-horizon evolution of indoor environments. We propose ReScene4D, a novel method that adapts 3DSIS architectures for 4DSIS without needing dense observations. It explores strategies to share information across observations, demonstrating that this shared context not only enables consistent instance tracking but also improves standard 3DSIS quality. To evaluate this task, we define a new metric, t-mAP, that extends mAP to reward temporal identity consistency. ReScene4D achieves state-of-the-art performance on the 3RScan dataset, establishing a new benchmark for understanding evolving indoor scenes.
ART: Articulated Reconstruction Transformer
Dec 16, 2025We introduce ART, Articulated Reconstruction Transformer -- a category-agnostic, feed-forward model that reconstructs complete 3D articulated objects from only sparse, multi-state RGB images. Previous methods for articulated object reconstruction either rely on slow optimization with fragile cross-state correspondences or use feed-forward models limited to specific object categories. In contrast, ART treats articulated objects as assemblies of rigid parts, formulating reconstruction as part-based prediction. Our newly designed transformer architecture maps sparse image inputs to a set of learnable part slots, from which ART jointly decodes unified representations for individual parts, including their 3D geometry, texture, and explicit articulation parameters. The resulting reconstructions are physically interpretable and readily exportable for simulation. Trained on a large-scale, diverse dataset with per-part supervision, and evaluated across diverse benchmarks, ART achieves significant improvements over existing baselines and establishes a new state of the art for articulated object reconstruction from image inputs.
VertexRegen: Mesh Generation with Continuous Level of Detail
Aug 12, 2025We introduce VertexRegen, a novel mesh generation framework that enables generation at a continuous level of detail. Existing autoregressive methods generate meshes in a partial-to-complete manner and thus intermediate steps of generation represent incomplete structures. VertexRegen takes inspiration from progressive meshes and reformulates the process as the reversal of edge collapse, i.e. vertex split, learned through a generative model. Experimental results demonstrate that VertexRegen produces meshes of comparable quality to state-of-the-art methods while uniquely offering anytime generation with the flexibility to halt at any step to yield valid meshes with varying levels of detail.
Human-in-the-Loop Local Corrections of 3D Scene Layouts via Infilling
Mar 14, 2025We present a novel human-in-the-loop approach to estimate 3D scene layout that uses human feedback from an egocentric standpoint. We study this approach through introduction of a novel local correction task, where users identify local errors and prompt a model to automatically correct them. Building on SceneScript, a state-of-the-art framework for 3D scene layout estimation that leverages structured language, we propose a solution that structures this problem as "infilling", a task studied in natural language processing. We train a multi-task version of SceneScript that maintains performance on global predictions while significantly improving its local correction ability. We integrate this into a human-in-the-loop system, enabling a user to iteratively refine scene layout estimates via a low-friction "one-click fix'' workflow. Our system enables the final refined layout to diverge from the training distribution, allowing for more accurate modelling of complex layouts.
SceneScript: Reconstructing Scenes With An Autoregressive Structured Language Model
Mar 19, 2024

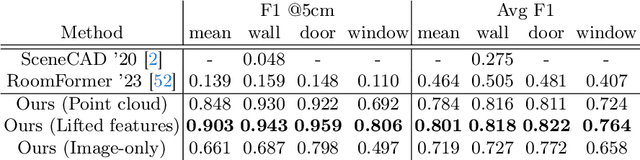
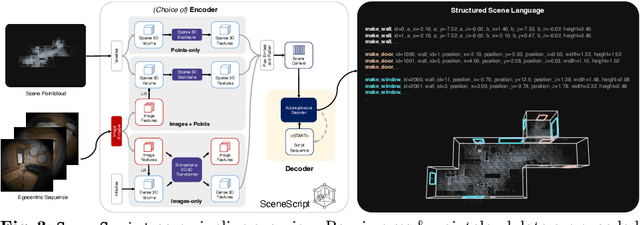
We introduce SceneScript, a method that directly produces full scene models as a sequence of structured language commands using an autoregressive, token-based approach. Our proposed scene representation is inspired by recent successes in transformers & LLMs, and departs from more traditional methods which commonly describe scenes as meshes, voxel grids, point clouds or radiance fields. Our method infers the set of structured language commands directly from encoded visual data using a scene language encoder-decoder architecture. To train SceneScript, we generate and release a large-scale synthetic dataset called Aria Synthetic Environments consisting of 100k high-quality in-door scenes, with photorealistic and ground-truth annotated renders of egocentric scene walkthroughs. Our method gives state-of-the art results in architectural layout estimation, and competitive results in 3D object detection. Lastly, we explore an advantage for SceneScript, which is the ability to readily adapt to new commands via simple additions to the structured language, which we illustrate for tasks such as coarse 3D object part reconstruction.
Cos R-CNN for Online Few-shot Object Detection
Jul 25, 2023



We propose Cos R-CNN, a simple exemplar-based R-CNN formulation that is designed for online few-shot object detection. That is, it is able to localise and classify novel object categories in images with few examples without fine-tuning. Cos R-CNN frames detection as a learning-to-compare task: unseen classes are represented as exemplar images, and objects are detected based on their similarity to these exemplars. The cosine-based classification head allows for dynamic adaptation of classification parameters to the exemplar embedding, and encourages the clustering of similar classes in embedding space without the need for manual tuning of distance-metric hyperparameters. This simple formulation achieves best results on the recently proposed 5-way ImageNet few-shot detection benchmark, beating the online 1/5/10-shot scenarios by more than 8/3/1%, as well as performing up to 20% better in online 20-way few-shot VOC across all shots on novel classes.
LaLaLoc: Latent Layout Localisation in Dynamic, Unvisited Environments
Apr 19, 2021
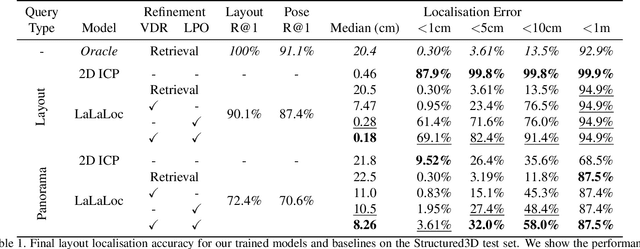
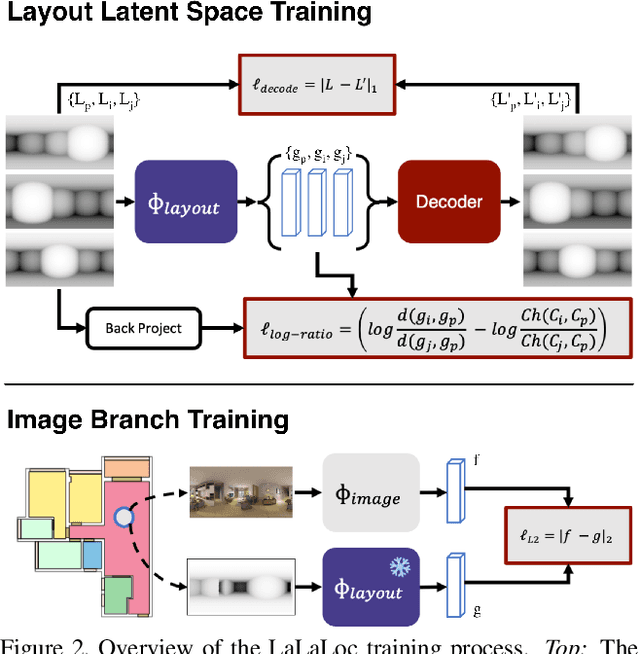
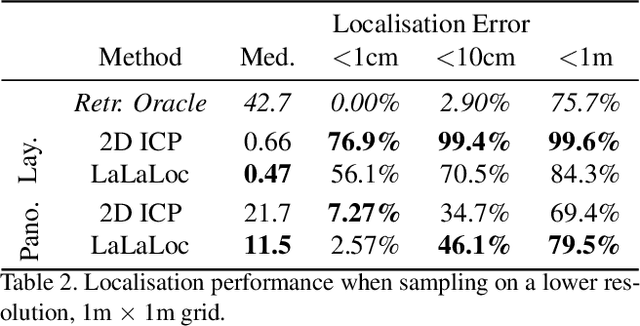
We present LaLaLoc to localise in environments without the need for prior visitation, and in a manner that is robust to large changes in scene appearance, such as a full rearrangement of furniture. Specifically, LaLaLoc performs localisation through latent representations of room layout. LaLaLoc learns a rich embedding space shared between RGB panoramas and layouts inferred from a known floor plan that encodes the structural similarity between locations. Further, LaLaLoc introduces direct, cross-modal pose optimisation in its latent space. Thus, LaLaLoc enables fine-grained pose estimation in a scene without the need for prior visitation, as well as being robust to dynamics, such as a change in furniture configuration. We show that in a domestic environment LaLaLoc is able to accurately localise a single RGB panorama image to within 8.3cm, given only a floor plan as a prior.
Correspondence Networks with Adaptive Neighbourhood Consensus
Mar 26, 2020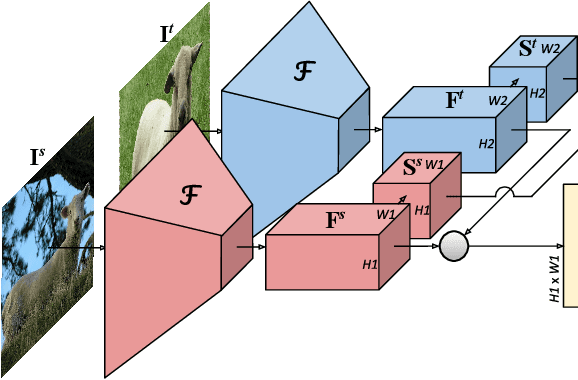
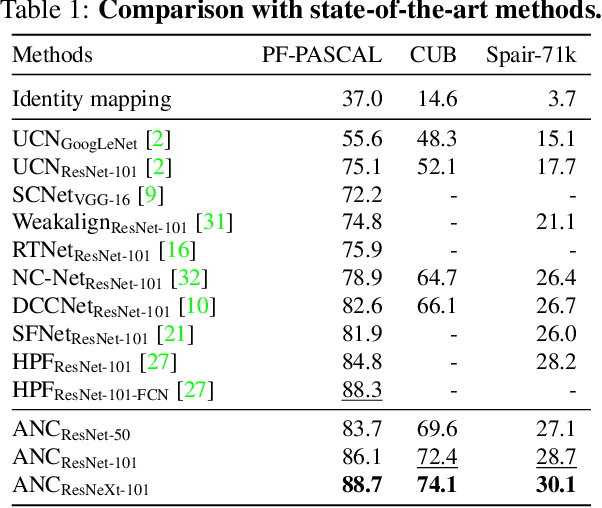
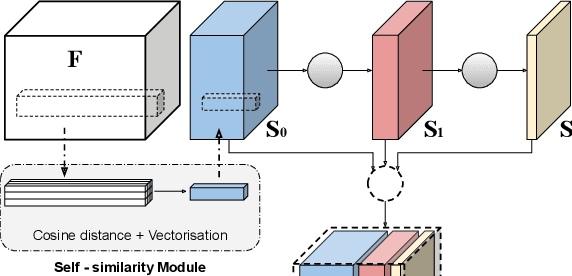

In this paper, we tackle the task of establishing dense visual correspondences between images containing objects of the same category. This is a challenging task due to large intra-class variations and a lack of dense pixel level annotations. We propose a convolutional neural network architecture, called adaptive neighbourhood consensus network (ANC-Net), that can be trained end-to-end with sparse key-point annotations, to handle this challenge. At the core of ANC-Net is our proposed non-isotropic 4D convolution kernel, which forms the building block for the adaptive neighbourhood consensus module for robust matching. We also introduce a simple and efficient multi-scale self-similarity module in ANC-Net to make the learned feature robust to intra-class variations. Furthermore, we propose a novel orthogonal loss that can enforce the one-to-one matching constraint. We thoroughly evaluate the effectiveness of our method on various benchmarks, where it substantially outperforms state-of-the-art methods.
FlowNet3D++: Geometric Losses For Deep Scene Flow Estimation
Dec 10, 2019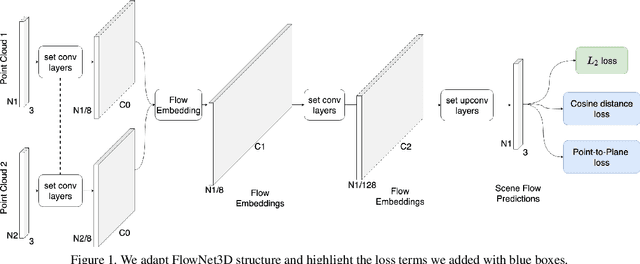
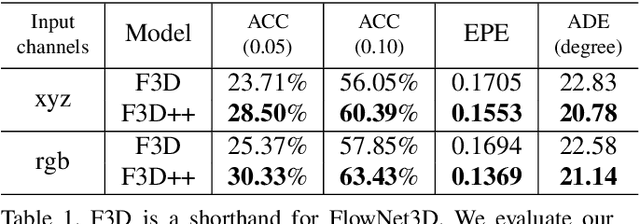
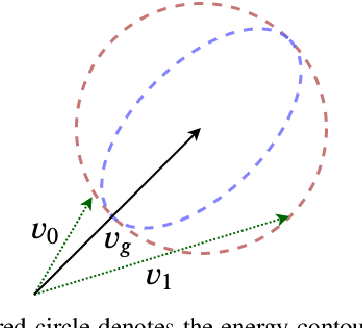
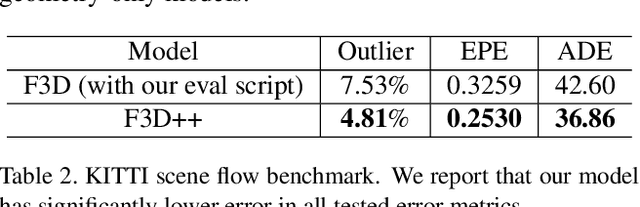
We present FlowNet3D++, a deep scene flow estimation network. Inspired by classical methods, FlowNet3D++ incorporates geometric constraints in the form of point-to-plane distance and angular alignment between individual vectors in the flow field, into FlowNet3D. We demonstrate that the addition of these geometric loss terms improves the previous state-of-art FlowNet3D accuracy from 57.85% to 63.43%. To further demonstrate the effectiveness of our geometric constraints, we propose a benchmark for flow estimation on the task of dynamic 3D reconstruction, thus providing a more holistic and practical measure of performance than the breakdown of individual metrics previously used to evaluate scene flow. This is made possible through the contribution of a novel pipeline to integrate point-based scene flow predictions into a global dense volume. FlowNet3D++ achieves up to a 15.0% reduction in reconstruction error over FlowNet3D, and up to a 35.2% improvement over KillingFusion alone. We will release our scene flow estimation code later.