 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoxeland: Probabilistic Instance-Aware Semantic Mapping with Evidence-based Uncertainty Quantification
Nov 13, 2024Robots in human-centered environments require accurate scene understanding to perform high-level tasks effectively. This understanding can be achieved through instance-aware semantic mapping, which involves reconstructing elements at the level of individual instances. Neural networks, the de facto solution for scene understanding, still face limitations such as overconfident incorrect predictions with out-of-distribution objects or generating inaccurate masks.Placing excessive reliance on these predictions makes the reconstruction susceptible to errors, reducing the robustness of the resulting maps and hampering robot operation. In this work, we propose Voxeland, a probabilistic framework for incrementally building instance-aware semantic maps. Inspired by the Theory of Evidence, Voxeland treats neural network predictions as subjective opinions regarding map instances at both geometric and semantic levels. These opinions are aggregated over time to form evidences, which are formalized through a probabilistic model. This enables us to quantify uncertainty in the reconstruction process, facilitating the identification of map areas requiring improvement (e.g. reobservation or reclassification). As one strategy to exploit this, we incorporate a Large Vision-Language Model (LVLM) to perform semantic level disambiguation for instances with high uncertainty. Results from the standard benchmarking on the publicly available SceneNN dataset demonstrate that Voxeland outperforms state-of-the-art methods, highlighting the benefits of incorporating and leveraging both instance- and semantic-level uncertainties to enhance reconstruction robustness. This is further validated through qualitative experiments conducted on the real-world ScanNet dataset.
Doppler-only Single-scan 3D Vehicle Odometry
Oct 06, 2023We present a novel 3D odometry method that recovers the full motion of a vehicle only from a Doppler-capable range sensor. It leverages the radial velocities measured from the scene, estimating the sensor's velocity from a single scan. The vehicle's 3D motion, defined by its linear and angular velocities, is calculated taking into consideration its kinematic model which provides a constraint between the velocity measured at the sensor frame and the vehicle frame. Experiments carried out prove the viability of our single-sensor method compared to mounting an additional IMU. Our method provides the translation of the sensor, which cannot be reliably determined from an IMU, as well as its rotation. Its short-term accuracy and fast operation (~5ms) make it a proper candidate to supply the initialization to more complex localization algorithms or mapping pipelines. Not only does it reduce the error of the mapper, but it does so at a comparable level of accuracy as an IMU would. All without the need to mount and calibrate an extra sensor on the vehicle.
LaLaLoc: Latent Layout Localisation in Dynamic, Unvisited Environments
Apr 19, 2021
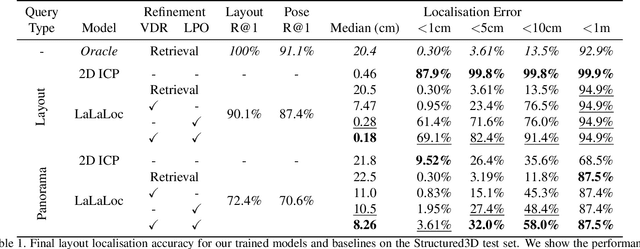
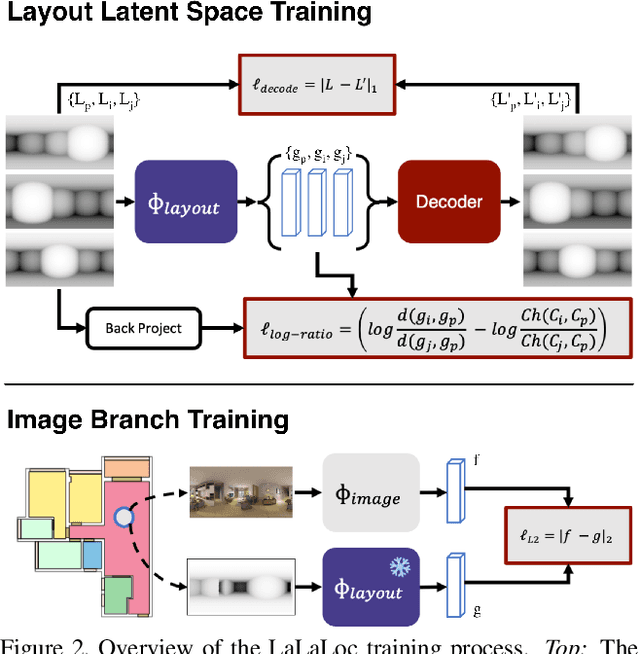
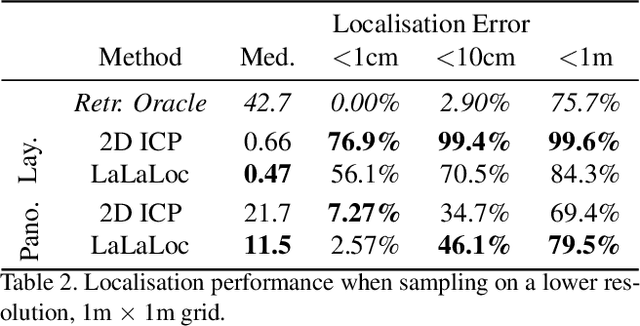
We present LaLaLoc to localise in environments without the need for prior visitation, and in a manner that is robust to large changes in scene appearance, such as a full rearrangement of furniture. Specifically, LaLaLoc performs localisation through latent representations of room layout. LaLaLoc learns a rich embedding space shared between RGB panoramas and layouts inferred from a known floor plan that encodes the structural similarity between locations. Further, LaLaLoc introduces direct, cross-modal pose optimisation in its latent space. Thus, LaLaLoc enables fine-grained pose estimation in a scene without the need for prior visitation, as well as being robust to dynamics, such as a change in furniture configuration. We show that in a domestic environment LaLaLoc is able to accurately localise a single RGB panorama image to within 8.3cm, given only a floor plan as a prior.
Intrinsic Calibration of Depth Cameras for Mobile Robots using a Radial Laser Scanner
Jul 03, 2019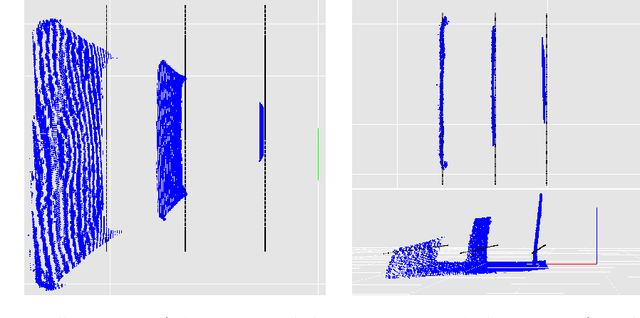
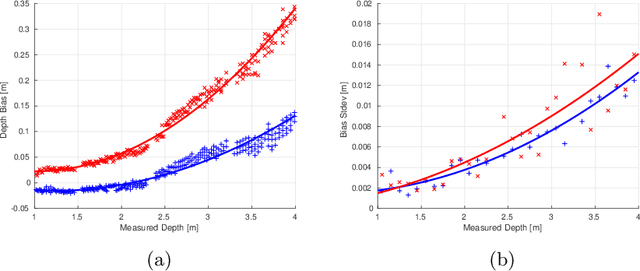


Depth cameras, typically in RGB-D configurations, are common devices in mobile robotic platforms given their appealing features: high frequency and resolution, low price and power requirements, among others. These sensors may come with significant, non-linear errors in the depth measurements that jeopardize robot tasks, like free-space detection, environment reconstruction or visual robot-human interaction. This paper presents a method to calibrate such systematic errors with the help of a second, more precise range sensor, in our case a radial laser scanner. In contrast to what it may seem at first, this does not mean a serious limitation in practice since these two sensors are often mounted jointly in many mobile robotic platforms, as they complement well each other. Moreover, the laser scanner can be used just for the calibration process and get rid of it after that. The main contributions of the paper are: i) the calibration is formulated from a probabilistic perspective through a Maximum Likelihood Estimation problem, and ii) the proposed method can be easily executed automatically by mobile robotic platforms. To validate the proposed approach we evaluated for both, local distortion of 3D planar reconstructions and global shifts in the measurements, obtaining considerably more accurate results. A C++ open-source implementation of the presented method has been released for the benefit of the community.
Automatic Multi-Sensor Extrinsic Calibration for Mobile Robots
Jun 11, 2019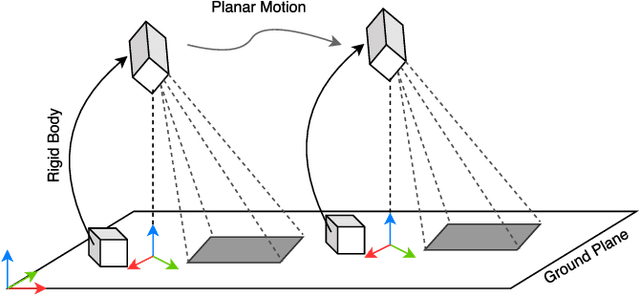
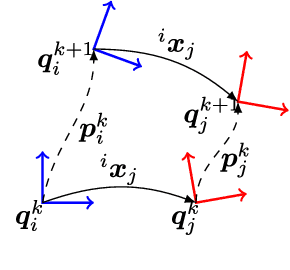
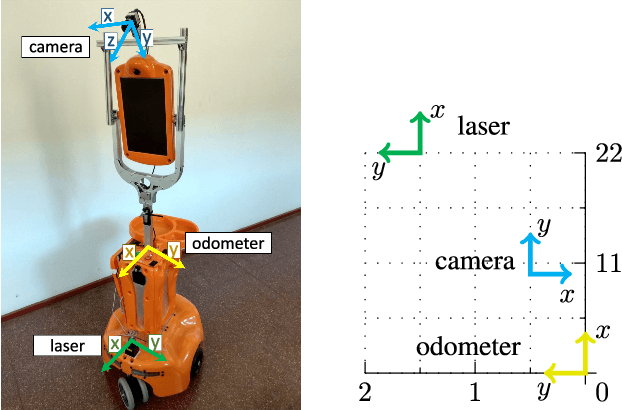
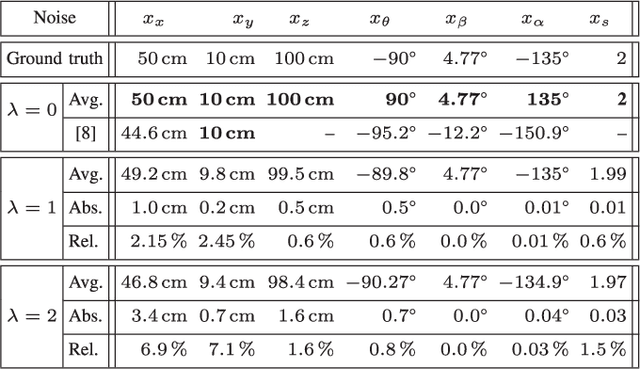
In order to fuse measurements from multiple sensors mounted on a mobile robot, it is needed to express them in a common reference system through their relative spatial transformations. In this paper, we present a method to estimate the full 6DoF extrinsic calibration parameters of multiple heterogeneous sensors (Lidars, Depth and RGB cameras) suitable for automatic execution on a mobile robot. Our method computes the 2D calibration parameters (x, y, yaw) through a motion-based approach, while for the remaining 3 parameters (z, pitch, roll) it requires the observation of the ground plane for a short period of time. What set this proposal apart from others is that: i) all calibration parameters are initialized in closed form, and ii) the scale ambiguity inherent to motion estimation from a monocular camera is explicitly handled, enabling the combination of these sensors and metric ones (Lidars, stereo rigs, etc.) within the same optimization framework. %Additionally, outlier observations arising from local sensor drift are automatically detected and removed from the calibration process. We provide a formal definition of the problem, as well as of the contributed method, for which a C++ implementation has been made publicly available. The suitability of the method has been assessed in simulation an with real data from indoor and outdoor scenarios. Finally, improvements over state-of-the-art motion-based calibration proposals are shown through experimental evaluation.