 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Multi-Sensor Extrinsic Calibration for Mobile Robots
Jun 11, 2019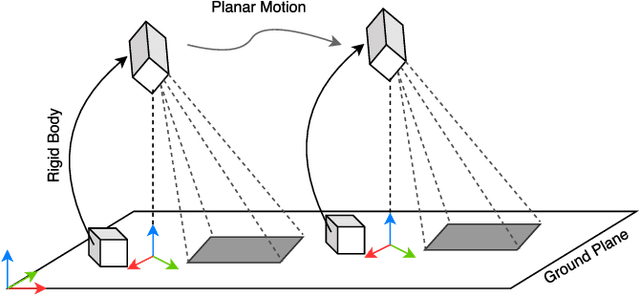
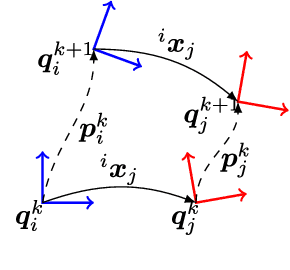
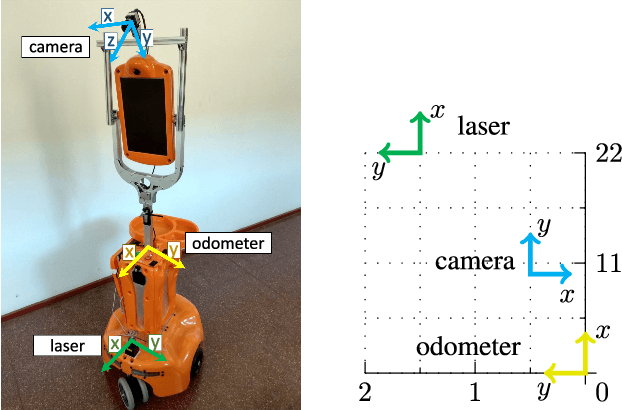
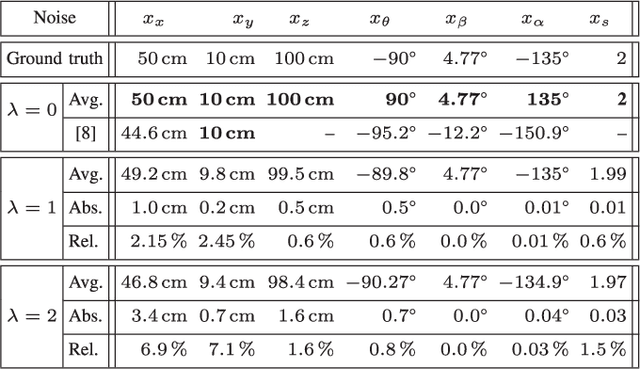
In order to fuse measurements from multiple sensors mounted on a mobile robot, it is needed to express them in a common reference system through their relative spatial transformations. In this paper, we present a method to estimate the full 6DoF extrinsic calibration parameters of multiple heterogeneous sensors (Lidars, Depth and RGB cameras) suitable for automatic execution on a mobile robot. Our method computes the 2D calibration parameters (x, y, yaw) through a motion-based approach, while for the remaining 3 parameters (z, pitch, roll) it requires the observation of the ground plane for a short period of time. What set this proposal apart from others is that: i) all calibration parameters are initialized in closed form, and ii) the scale ambiguity inherent to motion estimation from a monocular camera is explicitly handled, enabling the combination of these sensors and metric ones (Lidars, stereo rigs, etc.) within the same optimization framework. %Additionally, outlier observations arising from local sensor drift are automatically detected and removed from the calibration process. We provide a formal definition of the problem, as well as of the contributed method, for which a C++ implementation has been made publicly available. The suitability of the method has been assessed in simulation an with real data from indoor and outdoor scenarios. Finally, improvements over state-of-the-art motion-based calibration proposals are shown through experimental evaluation.
Geometric-based Line Segment Tracking for HDR Stereo Sequences
Sep 25, 2018

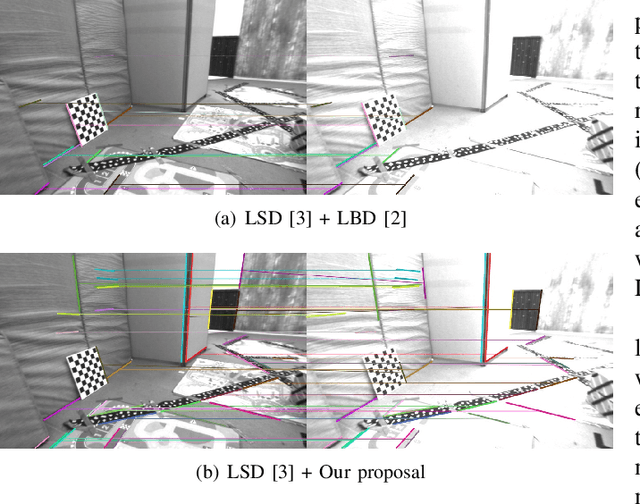

In this work, we propose a purely geometrical approach for the robust matching of line segments for challenging stereo streams with severe illumination changes or High Dynamic Range (HDR) environments. To that purpose, we exploit the univocal nature of the matching problem, i.e. every observation must be corresponded with a single feature or not corresponded at all. We state the problem as a sparse, convex, L1-minimization of the matching vector regularized by the geometric constraints. This formulation allows for the robust tracking of line segments along sequences where traditional appearance-based matching techniques tend to fail due to dynamic changes in illumination conditions. Moreover, the proposed matching algorithm also results in a considerable speed-up of previous state of the art techniques making it suitable for real-time applications such as Visual Odometry (VO). This, of course, comes at expense of a slightly lower number of matches in comparison with appearance based methods, and also limits its application to continuous video sequences, as it is rather constrained to small pose increments between consecutive frames. We validate the claimed advantages by first evaluating the matching performance in challenging video sequences, and then testing the method in a benchmarked point and line based VO algorithm.
PL-SLAM: a Stereo SLAM System through the Combination of Points and Line Segments
Apr 09, 2018



Traditional approaches to stereo visual SLAM rely on point features to estimate the camera trajectory and build a map of the environment. In low-textured environments, though, it is often difficult to find a sufficient number of reliable point features and, as a consequence, the performance of such algorithms degrades. This paper proposes PL-SLAM, a stereo visual SLAM system that combines both points and line segments to work robustly in a wider variety of scenarios, particularly in those where point features are scarce or not well-distributed in the image. PL-SLAM leverages both points and segments at all the instances of the process: visual odometry, keyframe selection, bundle adjustment, etc. We contribute also with a loop closure procedure through a novel bag-of-words approach that exploits the combined descriptive power of the two kinds of features. Additionally, the resulting map is richer and more diverse in 3D elements, which can be exploited to infer valuable, high-level scene structures like planes, empty spaces, ground plane, etc. (not addressed in this work). Our proposal has been tested with several popular datasets (such as KITTI and EuRoC), and is compared to state of the art methods like ORB-SLAM, revealing a more robust performance in most of the experiments, while still running in real-time. An open source version of the PL-SLAM C++ code will be released for the benefit of the community.
Learning-based Image Enhancement for Visual Odometry in Challenging HDR Environments
Apr 09, 2018



One of the main open challenges in visual odometry (VO) is the robustness to difficult illumination conditions or high dynamic range (HDR) environments. The main difficulties in these situations come from both the limitations of the sensors and the inability to perform a successful tracking of interest points because of the bold assumptions in VO, such as brightness constancy. We address this problem from a deep learning perspective, for which we first fine-tune a Deep Neural Network (DNN) with the purpose of obtaining enhanced representations of the sequences for VO. Then, we demonstrate how the insertion of Long Short Term Memory (LSTM) allows us to obtain temporally consistent sequences, as the estimation depends on previous states. However, the use of very deep networks does not allow the insertion into a real-time VO framework; therefore, we also propose a Convolutional Neural Network (CNN) of reduced size capable of performing faster. Finally, we validate the enhanced representations by evaluating the sequences produced by the two architectures in several state-of-art VO algorithms, such as ORB-SLAM and DSO.
Training a Convolutional Neural Network for Appearance-Invariant Place Recognition
May 27, 2015
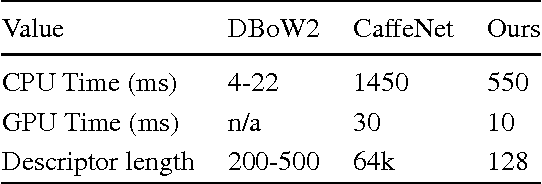
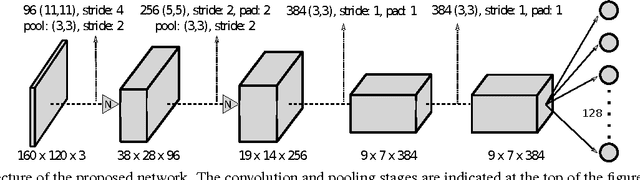

Place recognition is one of the most challenging problems in computer vision, and has become a key part in mobile robotics and autonomous driving applications for performing loop closure in visual SLAM systems. Moreover, the difficulty of recognizing a revisited location increases with appearance changes caused, for instance, by weather or illumination variations, which hinders the long-term application of such algorithms in real environments. In this paper we present a convolutional neural network (CNN), trained for the first time with the purpose of recognizing revisited locations under severe appearance changes, which maps images to a low dimensional space where Euclidean distances represent place dissimilarity. In order for the network to learn the desired invariances, we train it with triplets of images selected from datasets which present a challenging variability in visual appearance. The triplets are selected in such way that two samples are from the same location and the third one is taken from a different place. We validate our system through extensive experimentation, where we demonstrate better performance than state-of-art algorithms in a number of popular datasets.