 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoxeland: Probabilistic Instance-Aware Semantic Mapping with Evidence-based Uncertainty Quantification
Nov 13, 2024Robots in human-centered environments require accurate scene understanding to perform high-level tasks effectively. This understanding can be achieved through instance-aware semantic mapping, which involves reconstructing elements at the level of individual instances. Neural networks, the de facto solution for scene understanding, still face limitations such as overconfident incorrect predictions with out-of-distribution objects or generating inaccurate masks.Placing excessive reliance on these predictions makes the reconstruction susceptible to errors, reducing the robustness of the resulting maps and hampering robot operation. In this work, we propose Voxeland, a probabilistic framework for incrementally building instance-aware semantic maps. Inspired by the Theory of Evidence, Voxeland treats neural network predictions as subjective opinions regarding map instances at both geometric and semantic levels. These opinions are aggregated over time to form evidences, which are formalized through a probabilistic model. This enables us to quantify uncertainty in the reconstruction process, facilitating the identification of map areas requiring improvement (e.g. reobservation or reclassification). As one strategy to exploit this, we incorporate a Large Vision-Language Model (LVLM) to perform semantic level disambiguation for instances with high uncertainty. Results from the standard benchmarking on the publicly available SceneNN dataset demonstrate that Voxeland outperforms state-of-the-art methods, highlighting the benefits of incorporating and leveraging both instance- and semantic-level uncertainties to enhance reconstruction robustness. This is further validated through qualitative experiments conducted on the real-world ScanNet dataset.
Doppler-only Single-scan 3D Vehicle Odometry
Oct 06, 2023We present a novel 3D odometry method that recovers the full motion of a vehicle only from a Doppler-capable range sensor. It leverages the radial velocities measured from the scene, estimating the sensor's velocity from a single scan. The vehicle's 3D motion, defined by its linear and angular velocities, is calculated taking into consideration its kinematic model which provides a constraint between the velocity measured at the sensor frame and the vehicle frame. Experiments carried out prove the viability of our single-sensor method compared to mounting an additional IMU. Our method provides the translation of the sensor, which cannot be reliably determined from an IMU, as well as its rotation. Its short-term accuracy and fast operation (~5ms) make it a proper candidate to supply the initialization to more complex localization algorithms or mapping pipelines. Not only does it reduce the error of the mapper, but it does so at a comparable level of accuracy as an IMU would. All without the need to mount and calibrate an extra sensor on the vehicle.
Robotic Gas Source Localization with Probabilistic Mapping and Online Dispersion Simulation
Apr 18, 2023

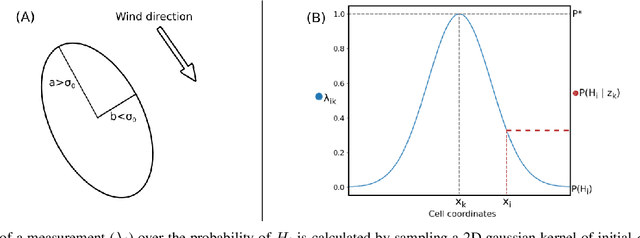

Gas source localization (GSL) with an autonomous robot is a problem with many prospective applications, from finding pipe leaks to emergency-response scenarios. In this work we present a new method to perform GSL in realistic indoor environments, featuring obstacles and turbulent flow. Given the highly complex relationship between the source position and the measurements available to the robot (the single-point gas concentration, and the wind vector) we propose an observation model that derives from contrasting the online, real-time simulation of the gas dispersion from any candidate source localization against a gas concentration map built from sensor readings. To account for a convenient and grounded integration of both into a probabilistic estimation framework, we introduce the concept of probabilistic gas-hit maps, which provide a higher level of abstraction to model the time-dependent nature of gas dispersion. Results from both simulated and real experiments show the capabilities of our current proposal to deal with source localization in complex indoor environments. To the best of our knowledge, this is the first work in olfactory robotics that doesn't make simplistic assumptions about environmental conditions like operating in open spaces and/or having an unrealistic laminar flow wind.
An Analytical Solution to the IMU Initialization Problem for Visual-Inertial Systems
Mar 05, 2021


The fusion of visual and inertial measurements is becoming more and more popular in the robotics community since both sources of information complement well each other. However, in order to perform this fusion, the biases of the Inertial Measurement Unit (IMU) as well as the direction of gravity must be initialized first. Additionally, in case of a monocular camera, the metric scale is also needed. The most popular visual-inertial initialization approaches rely on accurate vision-only motion estimates to build a non-linear optimization problem that solves for these parameters in an iterative way. In this paper, we rely on the previous work in [1] and propose an analytical solution to estimate the accelerometer bias, the direction of gravity and the scale factor in a maximum-likelihood framework. This formulation results in a very efficient estimation approach and, due to the non-iterative nature of the solution, avoids the intrinsic issues of previous iterative solutions. We present an extensive validation of the proposed IMU initialization approach and a performance comparison against the state-of-the-art approach described in [2] with real data from the publicly available EuRoC dataset, achieving comparable accuracy at a fraction of its computational cost and without requiring an initial guess for the scale factor. We also provide a C++ open source reference implementation.
Fast and Robust Certifiable Estimation of the Relative Pose Between Two Calibrated Cameras
Jan 21, 2021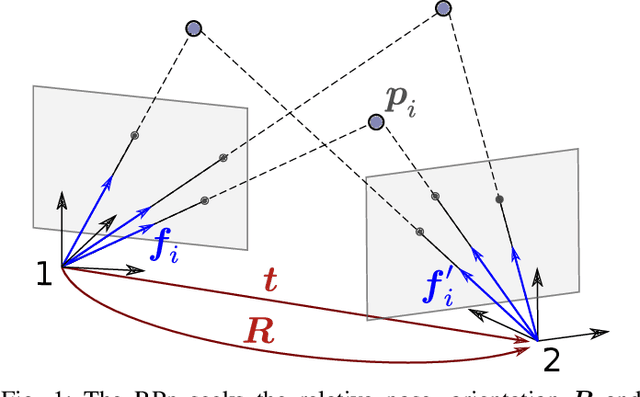
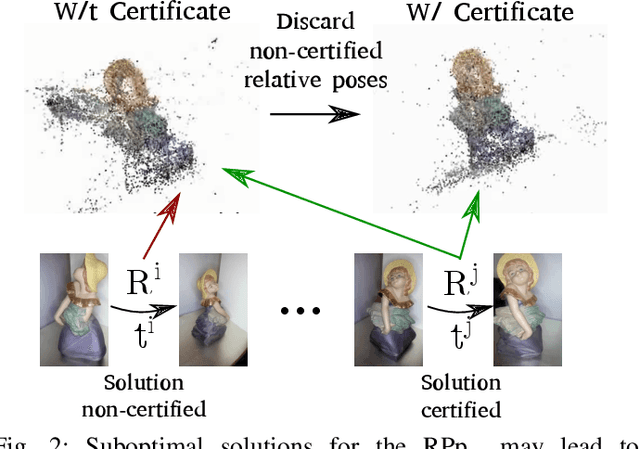
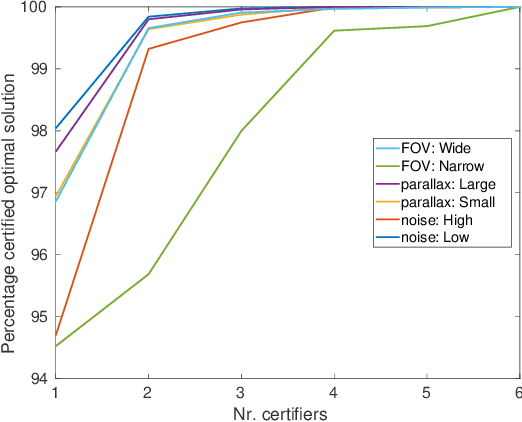
The Relative Pose problem (RPp) for cameras aims to estimate the relative orientation and translation (pose) given a set of pair-wise feature correspondences between two central and calibrated cameras. The RPp is stated as an optimization problem where the squared, normalized epipolar error is minimized over the set of normalized essential matrices. In this work, we contribute an efficient and complete algorithm based on results from duality theory that is able to certify whether the solution to a RPp instance is the global optimum. Specifically, we present a family of certifiers that is shown to increase the ratio of detected optimal solutions. This set of certifiers is incorporated into an efficient essential matrix estimation pipeline that, given any initial guess for the RPp, refines it iteratively on the product space of 3D rotations and 2-sphere and thereupon, certifies the optimality of the solution. We integrate our fast certifiable pipeline into a robust framework that combines Graduated Non-convexity and the Black-Rangarajan duality between robust functions and line processes. This combination has been shown in the literature to outperform the robustness to outliers provided by approaches based on RANSAC. We proved through extensive experiments on synthetic and real data that the proposed framework provides a fast and robust relative pose estimation. We compare our proposal against the state-of-the-art methods on both accuracy and computational cost, and show that our estimations improve the output of the gold-standard approach for the RPp, the 2-view Bundle-Adjustment. We make the code publicly available \url{https://github.com/mergarsal/FastCertRelPose.git}.
Certifiable Relative Pose Estimation
Mar 30, 2020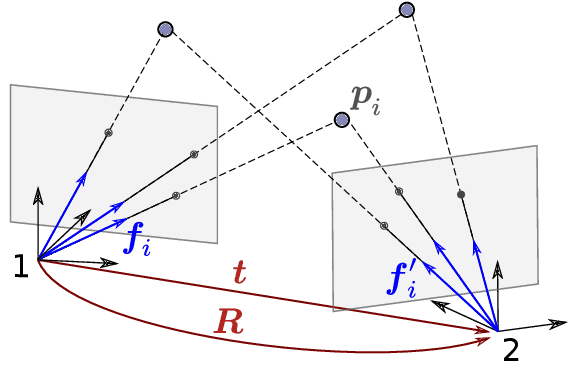

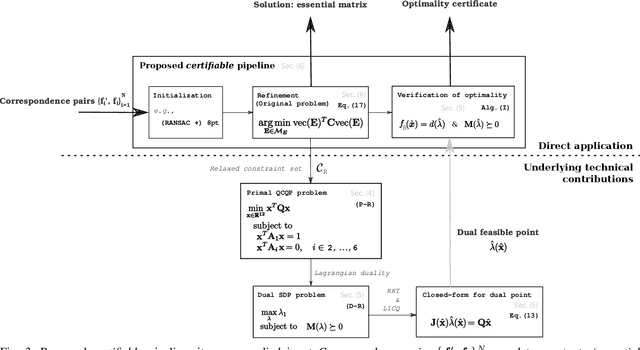
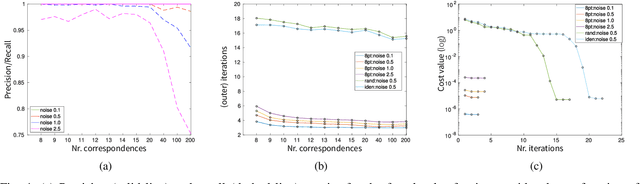
In this paper we present the first fast optimality certifier for the non-minimal version of the Relative Pose problem for calibrated cameras from epipolar constraints. The proposed certifier is based on Lagrangian duality and relies on a novel closed-form expression for dual points. We also leverage an efficient solver that performs local optimization on the manifold of the original problem's non-convex domain. The optimality of the solution is then checked via our novel fast certifier. The extensive conducted experiments demonstrate that, despite its simplicity, this certifiable solver performs excellently on synthetic data, repeatedly attaining the (certified \textit{a posteriori}) optimal solution and shows a satisfactory performance on real data.
Intrinsic Calibration of Depth Cameras for Mobile Robots using a Radial Laser Scanner
Jul 03, 2019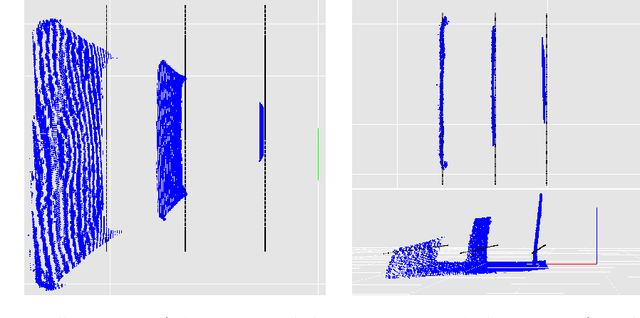
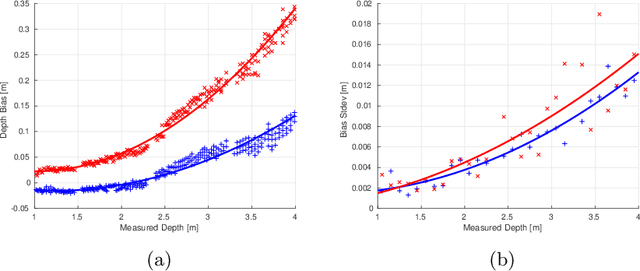


Depth cameras, typically in RGB-D configurations, are common devices in mobile robotic platforms given their appealing features: high frequency and resolution, low price and power requirements, among others. These sensors may come with significant, non-linear errors in the depth measurements that jeopardize robot tasks, like free-space detection, environment reconstruction or visual robot-human interaction. This paper presents a method to calibrate such systematic errors with the help of a second, more precise range sensor, in our case a radial laser scanner. In contrast to what it may seem at first, this does not mean a serious limitation in practice since these two sensors are often mounted jointly in many mobile robotic platforms, as they complement well each other. Moreover, the laser scanner can be used just for the calibration process and get rid of it after that. The main contributions of the paper are: i) the calibration is formulated from a probabilistic perspective through a Maximum Likelihood Estimation problem, and ii) the proposed method can be easily executed automatically by mobile robotic platforms. To validate the proposed approach we evaluated for both, local distortion of 3D planar reconstructions and global shifts in the measurements, obtaining considerably more accurate results. A C++ open-source implementation of the presented method has been released for the benefit of the community.
Automatic Multi-Sensor Extrinsic Calibration for Mobile Robots
Jun 11, 2019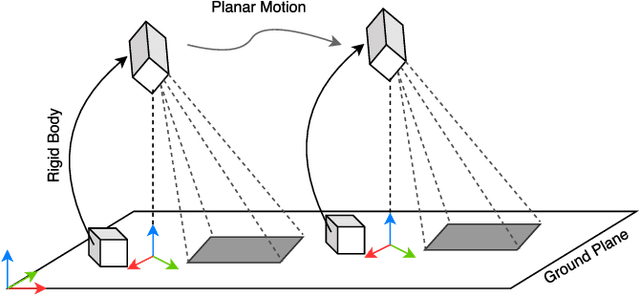
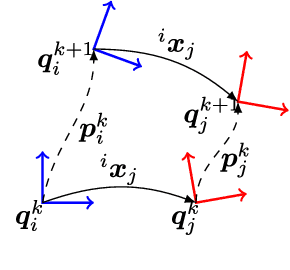
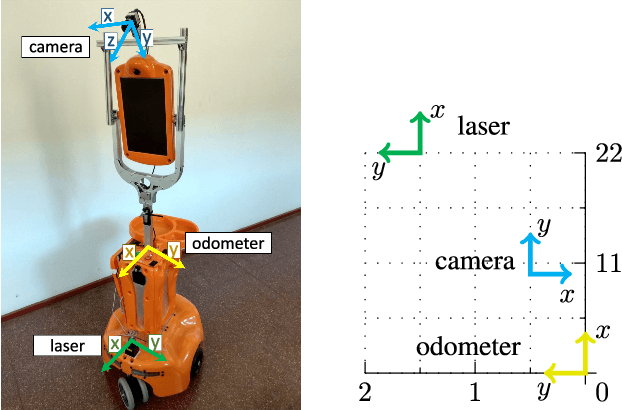
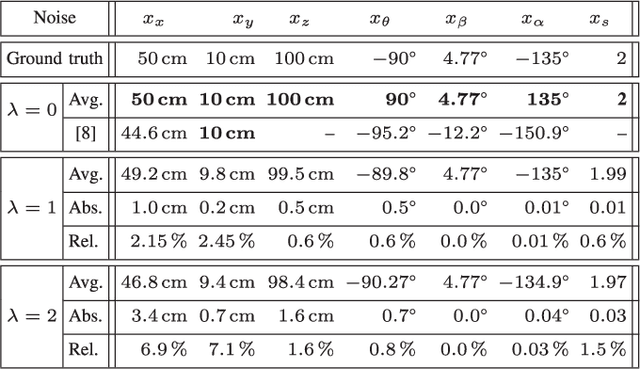
In order to fuse measurements from multiple sensors mounted on a mobile robot, it is needed to express them in a common reference system through their relative spatial transformations. In this paper, we present a method to estimate the full 6DoF extrinsic calibration parameters of multiple heterogeneous sensors (Lidars, Depth and RGB cameras) suitable for automatic execution on a mobile robot. Our method computes the 2D calibration parameters (x, y, yaw) through a motion-based approach, while for the remaining 3 parameters (z, pitch, roll) it requires the observation of the ground plane for a short period of time. What set this proposal apart from others is that: i) all calibration parameters are initialized in closed form, and ii) the scale ambiguity inherent to motion estimation from a monocular camera is explicitly handled, enabling the combination of these sensors and metric ones (Lidars, stereo rigs, etc.) within the same optimization framework. %Additionally, outlier observations arising from local sensor drift are automatically detected and removed from the calibration process. We provide a formal definition of the problem, as well as of the contributed method, for which a C++ implementation has been made publicly available. The suitability of the method has been assessed in simulation an with real data from indoor and outdoor scenarios. Finally, improvements over state-of-the-art motion-based calibration proposals are shown through experimental evaluation.
Geometric-based Line Segment Tracking for HDR Stereo Sequences
Sep 25, 2018

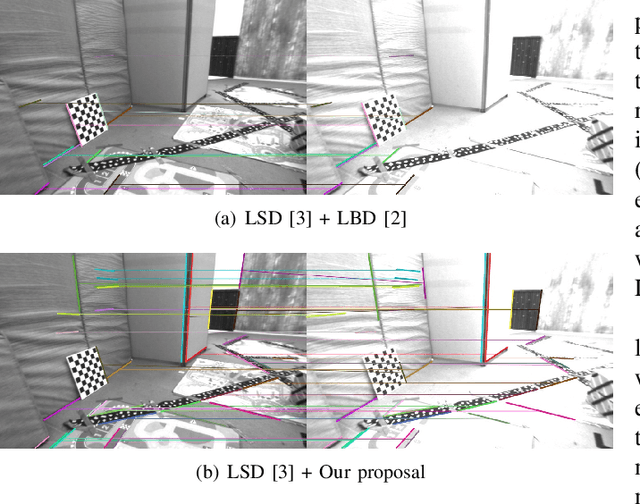

In this work, we propose a purely geometrical approach for the robust matching of line segments for challenging stereo streams with severe illumination changes or High Dynamic Range (HDR) environments. To that purpose, we exploit the univocal nature of the matching problem, i.e. every observation must be corresponded with a single feature or not corresponded at all. We state the problem as a sparse, convex, L1-minimization of the matching vector regularized by the geometric constraints. This formulation allows for the robust tracking of line segments along sequences where traditional appearance-based matching techniques tend to fail due to dynamic changes in illumination conditions. Moreover, the proposed matching algorithm also results in a considerable speed-up of previous state of the art techniques making it suitable for real-time applications such as Visual Odometry (VO). This, of course, comes at expense of a slightly lower number of matches in comparison with appearance based methods, and also limits its application to continuous video sequences, as it is rather constrained to small pose increments between consecutive frames. We validate the claimed advantages by first evaluating the matching performance in challenging video sequences, and then testing the method in a benchmarked point and line based VO algorithm.
PL-SLAM: a Stereo SLAM System through the Combination of Points and Line Segments
Apr 09, 2018



Traditional approaches to stereo visual SLAM rely on point features to estimate the camera trajectory and build a map of the environment. In low-textured environments, though, it is often difficult to find a sufficient number of reliable point features and, as a consequence, the performance of such algorithms degrades. This paper proposes PL-SLAM, a stereo visual SLAM system that combines both points and line segments to work robustly in a wider variety of scenarios, particularly in those where point features are scarce or not well-distributed in the image. PL-SLAM leverages both points and segments at all the instances of the process: visual odometry, keyframe selection, bundle adjustment, etc. We contribute also with a loop closure procedure through a novel bag-of-words approach that exploits the combined descriptive power of the two kinds of features. Additionally, the resulting map is richer and more diverse in 3D elements, which can be exploited to infer valuable, high-level scene structures like planes, empty spaces, ground plane, etc. (not addressed in this work). Our proposal has been tested with several popular datasets (such as KITTI and EuRoC), and is compared to state of the art methods like ORB-SLAM, revealing a more robust performance in most of the experiments, while still running in real-time. An open source version of the PL-SLAM C++ code will be released for the benefit of the community.