 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegressing Transformers for Data-efficient Visual Place Recognition
Jan 29, 2024
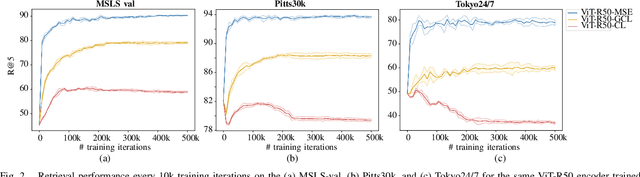
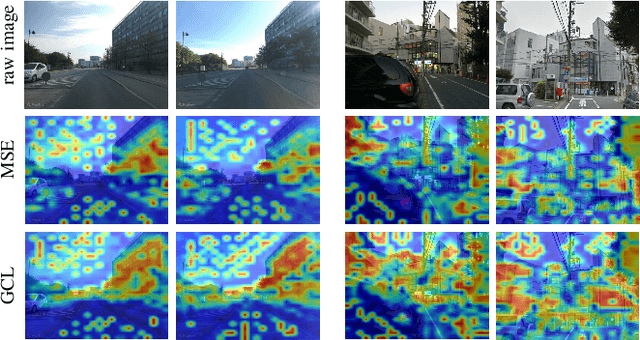
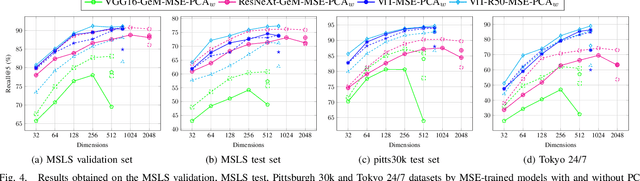
Visual place recognition is a critical task in computer vision, especially for localization and navigation systems. Existing methods often rely on contrastive learning: image descriptors are trained to have small distance for similar images and larger distance for dissimilar ones in a latent space. However, this approach struggles to ensure accurate distance-based image similarity representation, particularly when training with binary pairwise labels, and complex re-ranking strategies are required. This work introduces a fresh perspective by framing place recognition as a regression problem, using camera field-of-view overlap as similarity ground truth for learning. By optimizing image descriptors to align directly with graded similarity labels, this approach enhances ranking capabilities without expensive re-ranking, offering data-efficient training and strong generalization across several benchmark datasets.
Data-efficient Large Scale Place Recognition with Graded Similarity Supervision
Mar 25, 2023
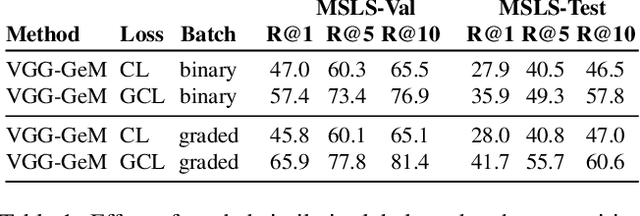
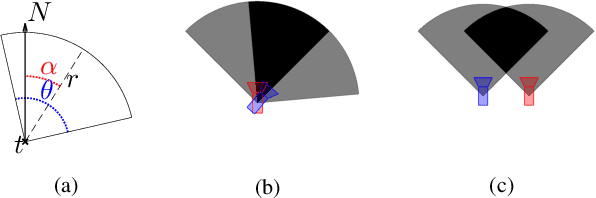

Visual place recognition (VPR) is a fundamental task of computer vision for visual localization. Existing methods are trained using image pairs that either depict the same place or not. Such a binary indication does not consider continuous relations of similarity between images of the same place taken from different positions, determined by the continuous nature of camera pose. The binary similarity induces a noisy supervision signal into the training of VPR methods, which stall in local minima and require expensive hard mining algorithms to guarantee convergence. Motivated by the fact that two images of the same place only partially share visual cues due to camera pose differences, we deploy an automatic re-annotation strategy to re-label VPR datasets. We compute graded similarity labels for image pairs based on available localization metadata. Furthermore, we propose a new Generalized Contrastive Loss (GCL) that uses graded similarity labels for training contrastive networks. We demonstrate that the use of the new labels and GCL allow to dispense from hard-pair mining, and to train image descriptors that perform better in VPR by nearest neighbor search, obtaining superior or comparable results than methods that require expensive hard-pair mining and re-ranking techniques. Code and models available at: https://github.com/marialeyvallina/generalized_contrastive_loss
Generalized Contrastive Optimization of Siamese Networks for Place Recognition
Mar 11, 2021
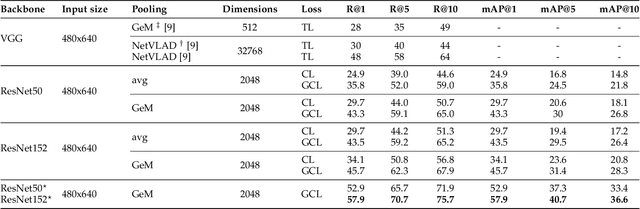
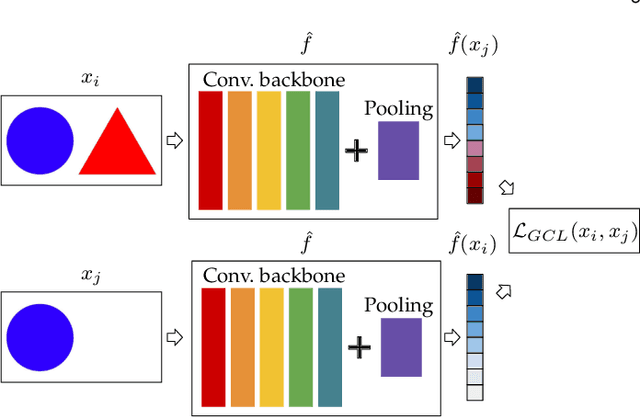
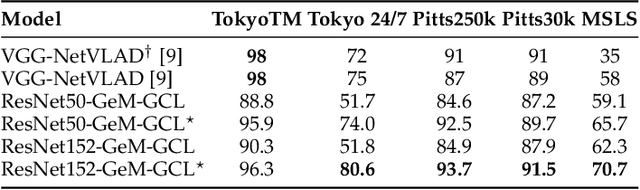
Visual place recognition is a challenging task in computer vision and a key component of camera-based localization and navigation systems. Recently, Convolutional Neural Networks (CNNs) achieved high results and good generalization capabilities. They are usually trained using pairs or triplets of images labeled as either similar or dissimilar, in a binary fashion. In practice, the similarity between two images is not binary, but rather continuous. Furthermore, training these CNNs is computationally complex and involves costly pair and triplet mining strategies. We propose a Generalized Contrastive loss (GCL) function that relies on image similarity as a continuous measure, and use it to train a siamese CNN. Furthermore, we propose three techniques for automatic annotation of image pairs with labels indicating their degree of similarity, and deploy them to re-annotate the MSLS, TB-Places, and 7Scenes datasets. We demonstrate that siamese CNNs trained using the GCL function and the improved annotations consistently outperform their binary counterparts. Our models trained on MSLS outperform the state-of-the-art methods, including NetVLAD, and generalize well on the Pittsburgh, TokyoTM and Tokyo 24/7 datasets. Furthermore, training a siamese network using the GCL function does not require complex pair mining. We release the source code at https://github.com/marialeyvallina/generalized_contrastive_loss.
MTStereo 2.0: improved accuracy of stereo depth estimation withMax-trees
Jun 27, 2020



Efficient yet accurate extraction of depth from stereo image pairs is required by systems with low power resources, such as robotics and embedded systems. State-of-the-art stereo matching methods based on convolutional neural networks require intensive computations on GPUs and are difficult to deploy on embedded systems. In this paper, we propose a stereo matching method, called MTStereo 2.0, for limited-resource systems that require efficient and accurate depth estimation. It is based on a Max-tree hierarchical representation of image pairs, which we use to identify matching regions along image scan-lines. The method includes a cost function that considers similarity of region contextual information based on the Max-trees and a disparity border preserving cost aggregation approach. MTStereo 2.0 improves on its predecessor MTStereo 1.0 as it a) deploys a more robust cost function, b) performs more thorough detection of incorrect matches, c) computes disparity maps with pixel-level rather than node-level precision. MTStereo provides accurate sparse and semi-dense depth estimation and does not require intensive GPU computations like methods based on CNNs. Thus it can run on embedded and robotics devices with low-power requirements. We tested the proposed approach on several benchmark data sets, namely KITTI 2015, Driving, FlyingThings3D, Middlebury 2014, Monkaa and the TrimBot2020 garden data sets, and achieved competitive accuracy and efficiency. The code is available at https://github.com/rbrandt1/MaxTreeS.
Place recognition in gardens by learning visual representations: data set and benchmark analysis
Jun 28, 2019


Visual place recognition is an important component of systems for camera localization and loop closure detection. It concerns the recognition of a previously visited place based on visual cues only. Although it is a widely studied problem for indoor and urban environments, the recent use of robots for automation of agricultural and gardening tasks has created new problems, due to the challenging appearance of garden-like environments. Garden scenes predominantly contain green colors, as well as repetitive patterns and textures. The lack of available data recorded in gardens and natural environments makes the improvement of visual localization algorithms difficult. In this paper we propose an extended version of the TB-Places data set, which is designed for testing algorithms for visual place recognition. It contains images with ground truth camera pose recorded in real gardens in different seasons, with varying light conditions. We constructed and released a ground truth for all possible pairs of images, indicating whether they depict the same place or not. We present the results of a benchmark analysis of methods based on convolutional neural networks for holistic image description and place recognition. We train existing networks (i.e. ResNet, DenseNet and VGG NetVLAD) as backbone of a two-way architecture with a contrastive loss function. The results that we obtained demonstrate that learning garden-tailored representations contribute to an improvement of performance, although the generalization capabilities are limited.
Towards Emotion Retrieval in Egocentric PhotoStream
May 10, 2019
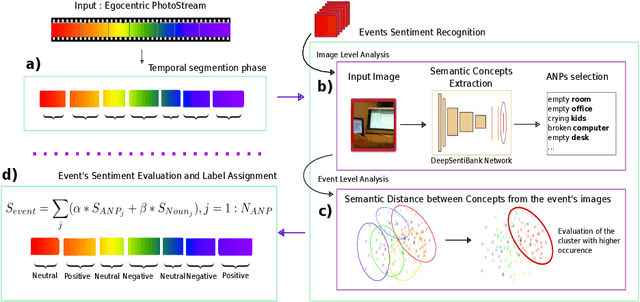
The availability and use of egocentric data are rapidly increasing due to the growing use of wearable cameras. Our aim is to study the effect (positive, neutral or negative) of egocentric images or events on an observer. Given egocentric photostreams capturing the wearer's days, we propose a method that aims to assign sentiment to events extracted from egocentric photostreams. Such moments can be candidates to retrieve according to their possibility of representing a positive experience for the camera's wearer. The proposed approach obtained a classification accuracy of 75% on the test set, with a deviation of 8%. Our model makes a step forward opening the door to sentiment recognition in egocentric photostreams.
Hierarchical approach to classify food scenes in egocentric photo-streams
May 10, 2019
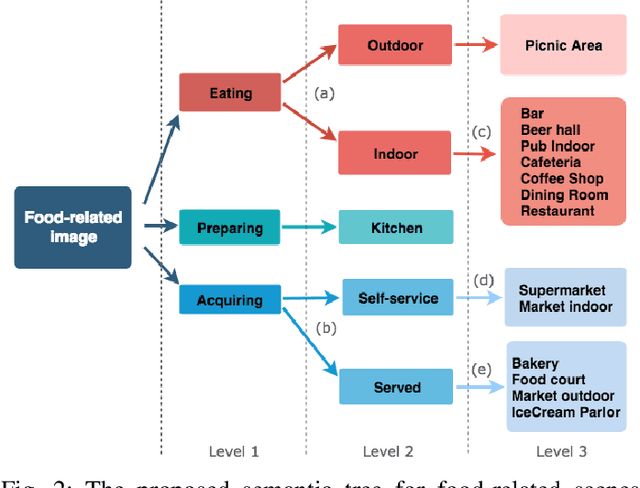
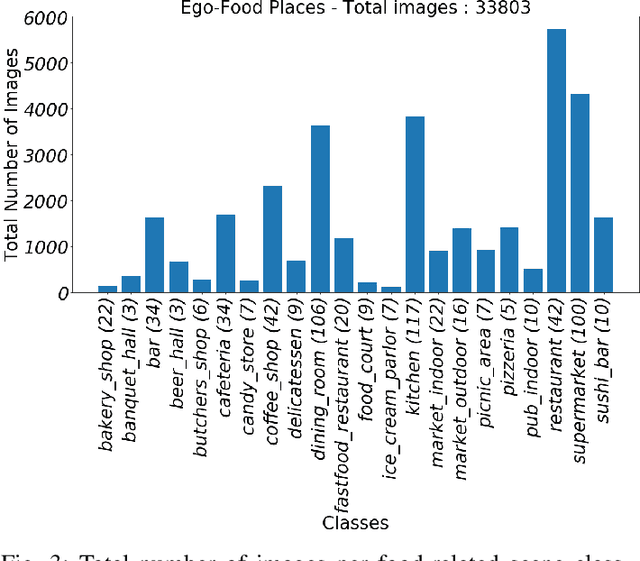
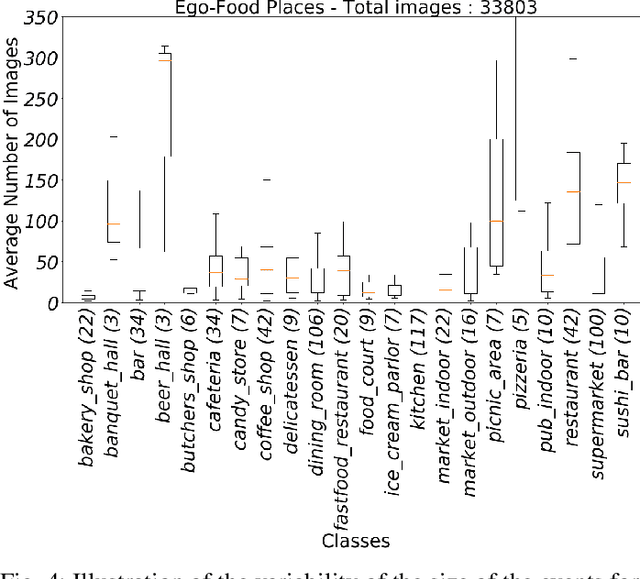
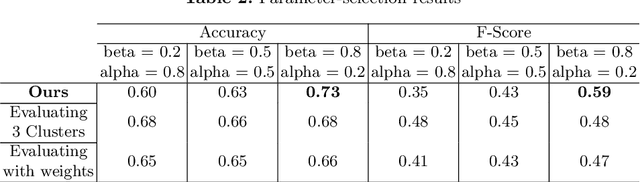
Recent studies have shown that the environment where people eat can affect their nutritional behaviour. In this work, we provide automatic tools for a personalised analysis of a person's health habits by the examination of daily recorded egocentric photo-streams. Specifically, we propose a new automatic approach for the classification of food-related environments, that is able to classify up to 15 such scenes. In this way, people can monitor the context around their food intake in order to get an objective insight into their daily eating routine. We propose a model that classifies food-related scenes organized in a semantic hierarchy. Additionally, we present and make available a new egocentric dataset composed of more than 33000 images recorded by a wearable camera, over which our proposed model has been tested. Our approach obtains an accuracy and F-score of 56\% and 65\%, respectively, clearly outperforming the baseline methods.
Towards Unsupervised Familiar Scene Recognition in Egocentric Videos
May 10, 2019

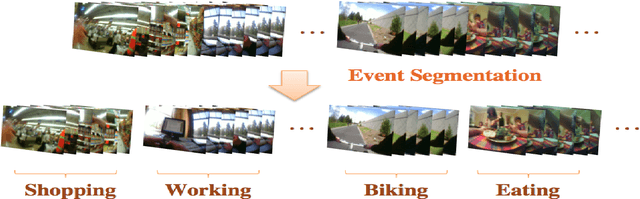

Nowadays, there is an upsurge of interest in using lifelogging devices. Such devices generate huge amounts of image data; consequently, the need for automatic methods for analyzing and summarizing these data is drastically increasing. We present a new method for familiar scene recognition in egocentric videos, based on background pattern detection through automatically configurable COSFIRE filters. We present some experiments over egocentric data acquired with the Narrative Clip.
Unsupervised routine discovery in egocentric photo-streams
May 10, 2019
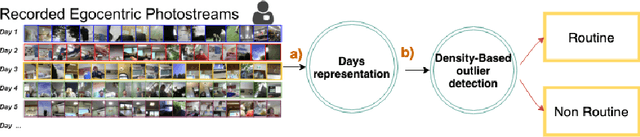

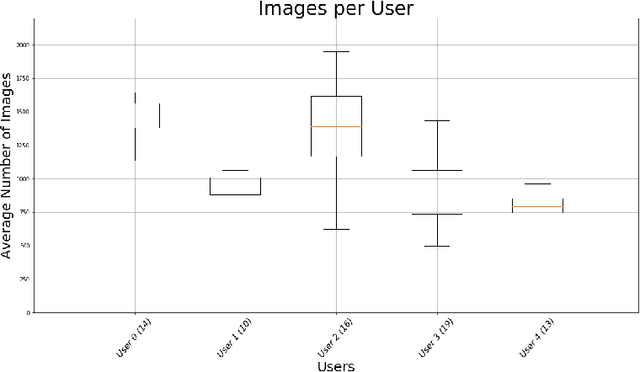
The routine of a person is defined by the occurrence of activities throughout different days, and can directly affect the person's health. In this work, we address the recognition of routine related days. To do so, we rely on egocentric images, which are recorded by a wearable camera and allow to monitor the life of the user from a first-person view perspective. We propose an unsupervised model that identifies routine related days, following an outlier detection approach. We test the proposed framework over a total of 72 days in the form of photo-streams covering around 2 weeks of the life of 5 different camera wearers. Our model achieves an average of 76% Accuracy and 68% Weighted F-Score for all the users. Thus, we show that our framework is able to recognise routine related days and opens the door to the understanding of the behaviour of people.
Towards Egocentric Person Re-identification and Social Pattern Analysis
May 10, 2019

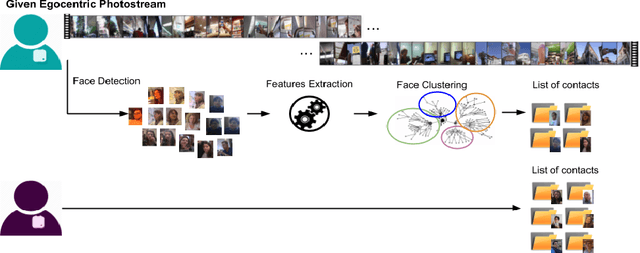
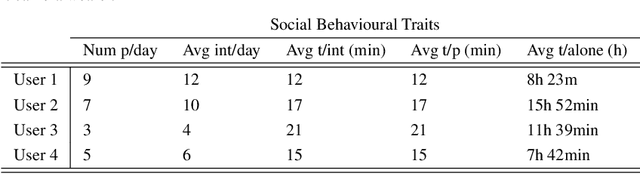
Wearable cameras capture a first-person view of the daily activities of the camera wearer, offering a visual diary of the user behaviour. Detection of the appearance of people the camera user interacts with for social interactions analysis is of high interest. Generally speaking, social events, lifestyle and health are highly correlated, but there is a lack of tools to monitor and analyse them. We consider that egocentric vision provides a tool to obtain information and understand users social interactions. We propose a model that enables us to evaluate and visualize social traits obtained by analysing social interactions appearance within egocentric photostreams. Given sets of egocentric images, we detect the appearance of faces within the days of the camera wearer, and rely on clustering algorithms to group their feature descriptors in order to re-identify persons. Recurrence of detected faces within photostreams allows us to shape an idea of the social pattern of behaviour of the user. We validated our model over several weeks recorded by different camera wearers. Our findings indicate that social profiles are potentially useful for social behaviour interpretation.