 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-weakly-supervised neural network training for medical image registration
Feb 16, 2024



For training registration networks, weak supervision from segmented corresponding regions-of-interest (ROIs) have been proven effective for (a) supplementing unsupervised methods, and (b) being used independently in registration tasks in which unsupervised losses are unavailable or ineffective. This correspondence-informing supervision entails cost in annotation that requires significant specialised effort. This paper describes a semi-weakly-supervised registration pipeline that improves the model performance, when only a small corresponding-ROI-labelled dataset is available, by exploiting unlabelled image pairs. We examine two types of augmentation methods by perturbation on network weights and image resampling, such that consistency-based unsupervised losses can be applied on unlabelled data. The novel WarpDDF and RegCut approaches are proposed to allow commutative perturbation between an image pair and the predicted spatial transformation (i.e. respective input and output of registration networks), distinct from existing perturbation methods for classification or segmentation. Experiments using 589 male pelvic MR images, labelled with eight anatomical ROIs, show the improvement in registration performance and the ablated contributions from the individual strategies. Furthermore, this study attempts to construct one of the first computational atlases for pelvic structures, enabled by registering inter-subject MRs, and quantifies the significant differences due to the proposed semi-weak supervision with a discussion on the potential clinical use of example atlas-derived statistics.
ABC Easy as 123: A Blind Counter for Exemplar-Free Multi-Class Class-agnostic Counting
Sep 09, 2023Class-agnostic counting methods enumerate objects of an arbitrary class, providing tremendous utility in many fields. Prior works have limited usefulness as they require either a set of examples of the type to be counted or that the image contains only a single type of object. A significant factor in these shortcomings is the lack of a dataset to properly address counting in settings with more than one kind of object present. To address these issues, we propose the first Multi-class, Class-Agnostic Counting dataset (MCAC) and A Blind Counter (ABC123), a method that can count multiple types of objects simultaneously without using examples of type during training or inference. ABC123 introduces a new paradigm where instead of requiring exemplars to guide the enumeration, examples are found after the counting stage to help a user understand the generated outputs. We show that ABC123 outperforms contemporary methods on MCAC without the requirement of human in-the-loop annotations. We also show that this performance transfers to FSC-147, the standard class-agnostic counting dataset.
DMS: Differentiable Mean Shift for Dataset Agnostic Task Specific Clustering Using Side Information
May 29, 2023We present a novel approach, in which we learn to cluster data directly from side information, in the form of a small set of pairwise examples. Unlike previous methods, with or without side information, we do not need to know the number of clusters, their centers or any kind of distance metric for similarity. Our method is able to divide the same data points in various ways dependant on the needs of a specific task, defined by the side information. Contrastingly, other work generally finds only the intrinsic, most obvious, clusters. Inspired by the mean shift algorithm, we implement our new clustering approach using a custom iterative neural network to create Differentiable Mean Shift (DMS), a state of the art, dataset agnostic, clustering method. We found that it was possible to train a strong cluster definition without enforcing a constraint that each cluster must be presented during training. DMS outperforms current methods in both the intrinsic and non-intrinsic dataset tasks.
Contextualising Implicit Representations for Semantic Tasks
May 22, 2023Prior works have demonstrated that implicit representations trained only for reconstruction tasks typically generate encodings that are not useful for semantic tasks. In this work, we propose a method that contextualises the encodings of implicit representations, enabling their use in downstream tasks (e.g. semantic segmentation), without requiring access to the original training data or encoding network. Using an implicit representation trained for a reconstruction task alone, our contextualising module takes an encoding trained for reconstruction only and reveals meaningful semantic information that is hidden in the encodings, without compromising the reconstruction performance. With our proposed module, it becomes possible to pre-train implicit representations on larger datasets, improving their reconstruction performance compared to training on only a smaller labelled dataset, whilst maintaining their segmentation performance on the labelled dataset. Importantly, our method allows for future foundation implicit representation models to be fine-tuned on unseen tasks, regardless of encoder or dataset availability.
GroSS: Group-Size Series Decomposition for Whole Search-Space Training
Dec 02, 2019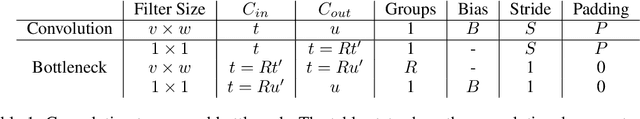
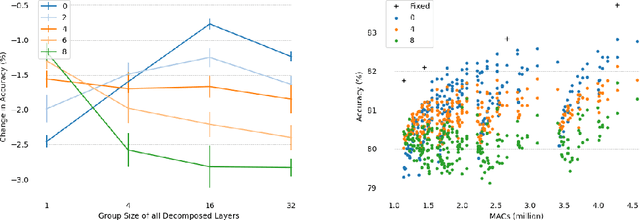
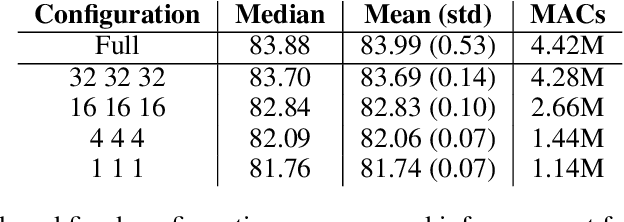
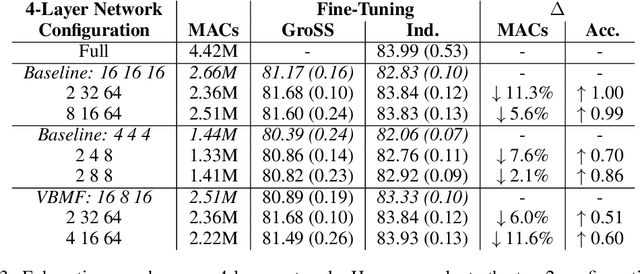
We present Group-size Series (GroSS) decomposition, a mathematical formulation of tensor factorisation into a series of approximations of increasing rank terms. GroSS allows for dynamic and differentiable selection of factorisation rank, which is analogous to a grouped convolution. Therefore, to the best of our knowledge, GroSS is the first method to simultaneously train differing numbers of groups within a single layer, as well as all possible combinations between layers. In doing so, GroSS trains an entire grouped convolution architecture search-space concurrently. We demonstrate this through proof-of-concept architecture searches with performance objectives. GroSS represents a significant step towards liberating network architecture search from the burden of training and fine-tuning.
Real-Time RGB-D Camera Pose Estimation in Novel Scenes using a Relocalisation Cascade
Oct 29, 2018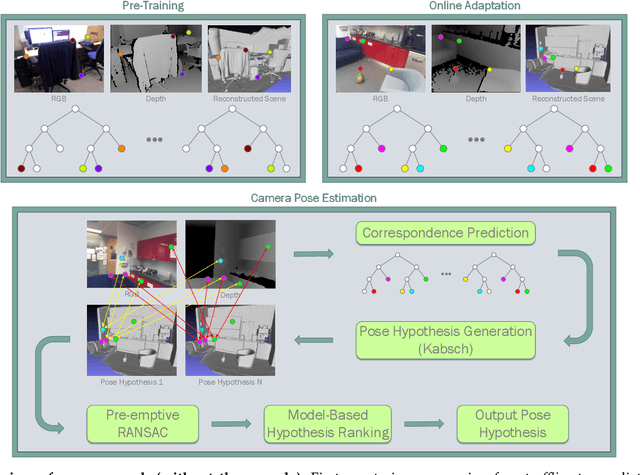
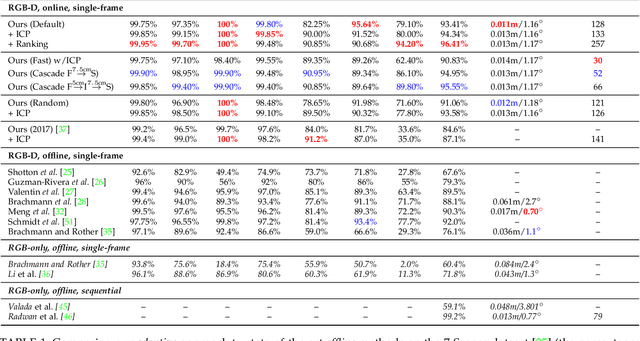

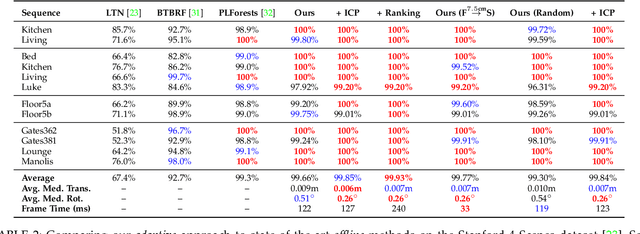
Camera pose estimation is an important problem in computer vision. Common techniques either match the current image against keyframes with known poses, directly regress the pose, or establish correspondences between keypoints in the image and points in the scene to estimate the pose. In recent years, regression forests have become a popular alternative to establish such correspondences. They achieve accurate results, but have traditionally needed to be trained offline on the target scene, preventing relocalisation in new environments. Recently, we showed how to circumvent this limitation by adapting a pre-trained forest to a new scene on the fly. The adapted forests achieved relocalisation performance that was on par with that of offline forests, and our approach was able to estimate the camera pose in close to real time. In this paper, we present an extension of this work that achieves significantly better relocalisation performance whilst running fully in real time. To achieve this, we make several changes to the original approach: (i) instead of accepting the camera pose hypothesis without question, we make it possible to score the final few hypotheses using a geometric approach and select the most promising; (ii) we chain several instantiations of our relocaliser together in a cascade, allowing us to try faster but less accurate relocalisation first, only falling back to slower, more accurate relocalisation as necessary; and (iii) we tune the parameters of our cascade to achieve effective overall performance. These changes allow us to significantly improve upon the performance our original state-of-the-art method was able to achieve on the well-known 7-Scenes and Stanford 4 Scenes benchmarks. As additional contributions, we present a way of visualising the internal behaviour of our forests and show how to entirely circumvent the need to pre-train a forest on a generic scene.
SemanticPaint: A Framework for the Interactive Segmentation of 3D Scenes
Oct 13, 2015

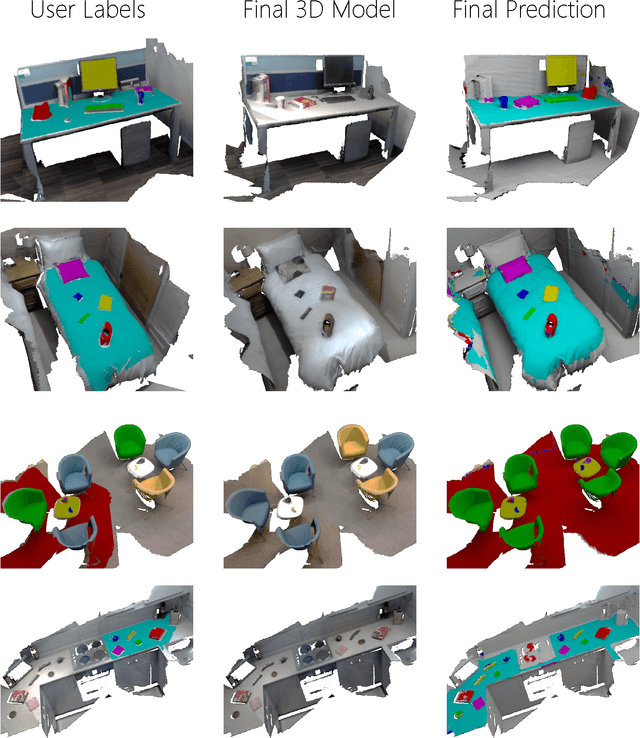
We present an open-source, real-time implementation of SemanticPaint, a system for geometric reconstruction, object-class segmentation and learning of 3D scenes. Using our system, a user can walk into a room wearing a depth camera and a virtual reality headset, and both densely reconstruct the 3D scene and interactively segment the environment into object classes such as 'chair', 'floor' and 'table'. The user interacts physically with the real-world scene, touching objects and using voice commands to assign them appropriate labels. These user-generated labels are leveraged by an online random forest-based machine learning algorithm, which is used to predict labels for previously unseen parts of the scene. The entire pipeline runs in real time, and the user stays 'in the loop' throughout the process, receiving immediate feedback about the progress of the labelling and interacting with the scene as necessary to refine the predicted segmentation.