 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGroSS: Group-Size Series Decomposition for Whole Search-Space Training
Paper and Code
Dec 02, 2019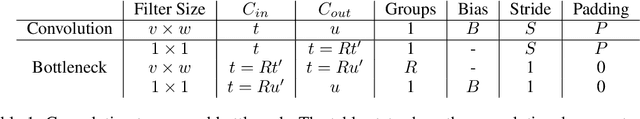
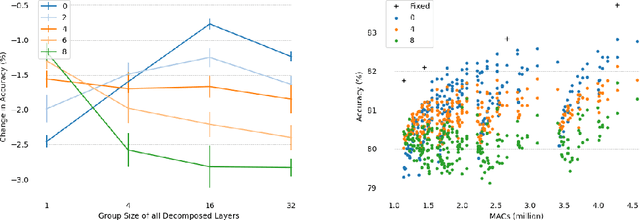
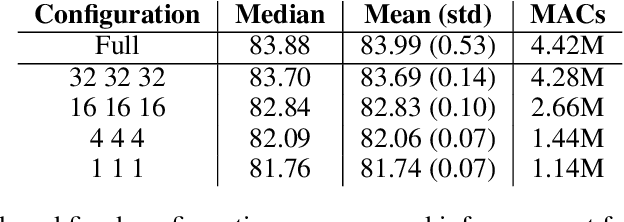
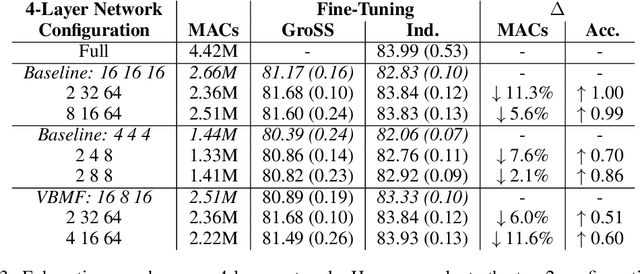
We present Group-size Series (GroSS) decomposition, a mathematical formulation of tensor factorisation into a series of approximations of increasing rank terms. GroSS allows for dynamic and differentiable selection of factorisation rank, which is analogous to a grouped convolution. Therefore, to the best of our knowledge, GroSS is the first method to simultaneously train differing numbers of groups within a single layer, as well as all possible combinations between layers. In doing so, GroSS trains an entire grouped convolution architecture search-space concurrently. We demonstrate this through proof-of-concept architecture searches with performance objectives. GroSS represents a significant step towards liberating network architecture search from the burden of training and fine-tuning.