 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSample, Crop, Track: Self-Supervised Mobile 3D Object Detection for Urban Driving LiDAR
Sep 21, 2022
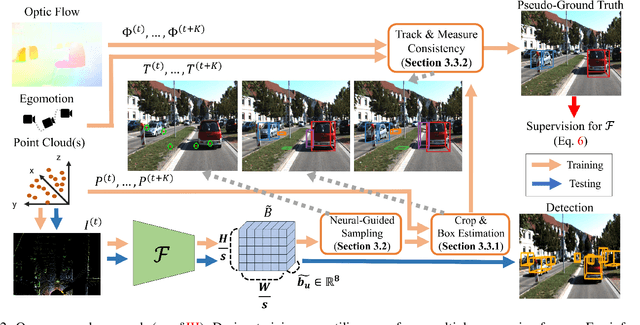
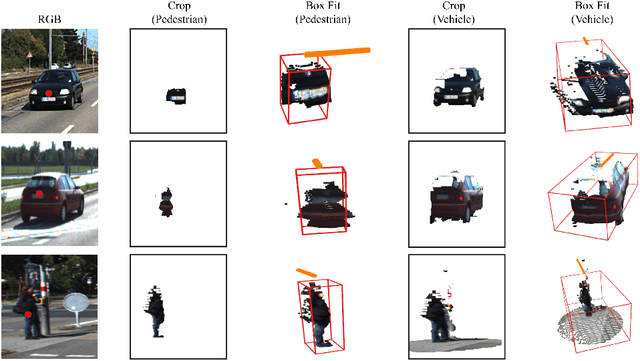
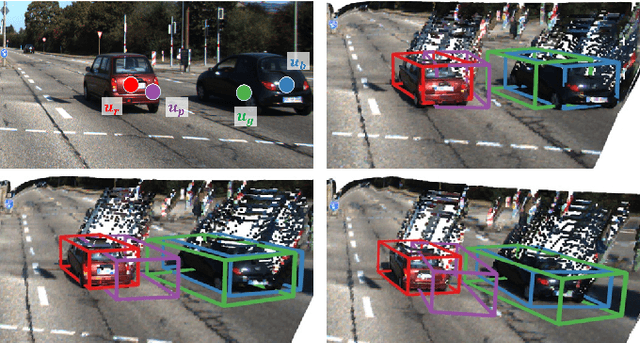
Deep learning has led to great progress in the detection of mobile (i.e. movement-capable) objects in urban driving scenes in recent years. Supervised approaches typically require the annotation of large training sets; there has thus been great interest in leveraging weakly, semi- or self-supervised methods to avoid this, with much success. Whilst weakly and semi-supervised methods require some annotation, self-supervised methods have used cues such as motion to relieve the need for annotation altogether. However, a complete absence of annotation typically degrades their performance, and ambiguities that arise during motion grouping can inhibit their ability to find accurate object boundaries. In this paper, we propose a new self-supervised mobile object detection approach called SCT. This uses both motion cues and expected object sizes to improve detection performance, and predicts a dense grid of 3D oriented bounding boxes to improve object discovery. We significantly outperform the state-of-the-art self-supervised mobile object detection method TCR on the KITTI tracking benchmark, and achieve performance that is within 30% of the fully supervised PV-RCNN++ method for IoUs <= 0.5.
When the Sun Goes Down: Repairing Photometric Losses for All-Day Depth Estimation
Jun 28, 2022
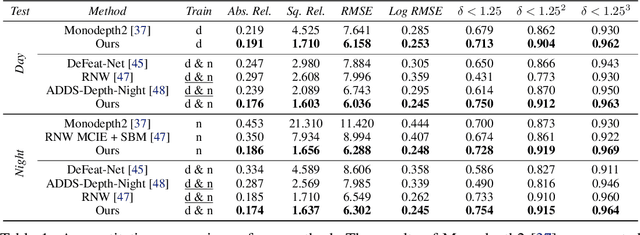
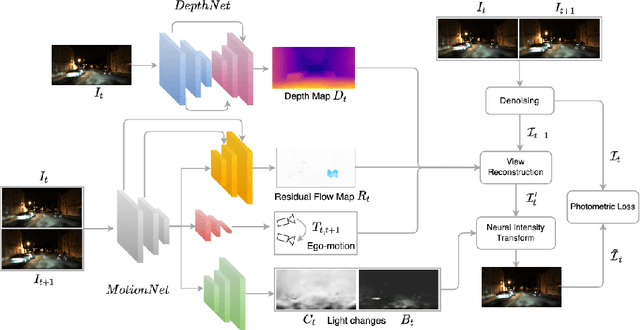
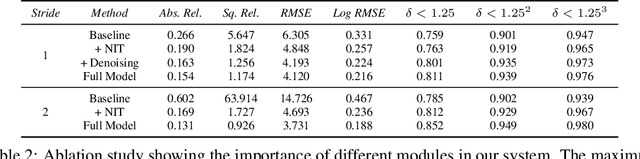
Self-supervised deep learning methods for joint depth and ego-motion estimation can yield accurate trajectories without needing ground-truth training data. However, as they typically use photometric losses, their performance can degrade significantly when the assumptions these losses make (e.g. temporal illumination consistency, a static scene, and the absence of noise and occlusions) are violated. This limits their use for e.g. nighttime sequences, which tend to contain many point light sources (including on dynamic objects) and low signal-to-noise ratio (SNR) in darker image regions. In this paper, we show how to use a combination of three techniques to allow the existing photometric losses to work for both day and nighttime images. First, we introduce a per-pixel neural intensity transformation to compensate for the light changes that occur between successive frames. Second, we predict a per-pixel residual flow map that we use to correct the reprojection correspondences induced by the estimated ego-motion and depth from the networks. And third, we denoise the training images to improve the robustness and accuracy of our approach. These changes allow us to train a single model for both day and nighttime images without needing separate encoders or extra feature networks like existing methods. We perform extensive experiments and ablation studies on the challenging Oxford RobotCar dataset to demonstrate the efficacy of our approach for both day and nighttime sequences.
Real-Time Hybrid Mapping of Populated Indoor Scenes using a Low-Cost Monocular UAV
Mar 04, 2022
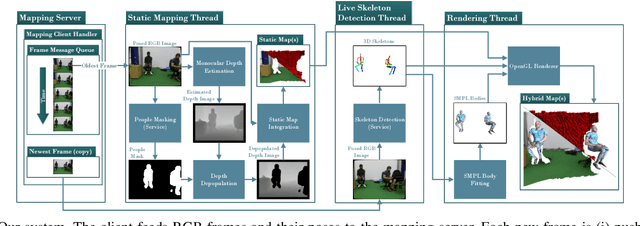
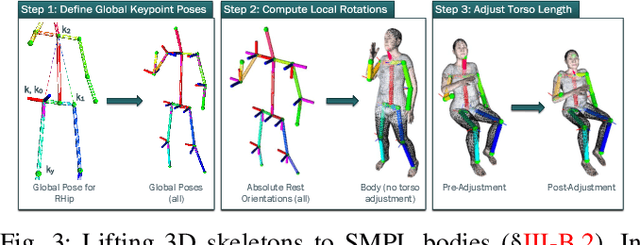
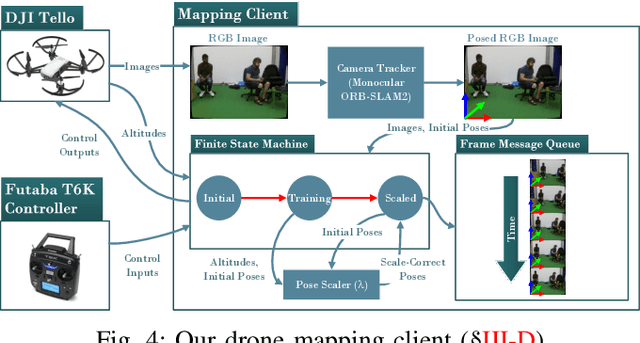
Unmanned aerial vehicles (UAVs) have been used for many applications in recent years, from urban search and rescue, to agricultural surveying, to autonomous underground mine exploration. However, deploying UAVs in tight, indoor spaces, especially close to humans, remains a challenge. One solution, when limited payload is required, is to use micro-UAVs, which pose less risk to humans and typically cost less to replace after a crash. However, micro-UAVs can only carry a limited sensor suite, e.g. a monocular camera instead of a stereo pair or LiDAR, complicating tasks like dense mapping and markerless multi-person 3D human pose estimation, which are needed to operate in tight environments around people. Monocular approaches to such tasks exist, and dense monocular mapping approaches have been successfully deployed for UAV applications. However, despite many recent works on both marker-based and markerless multi-UAV single-person motion capture, markerless single-camera multi-person 3D human pose estimation remains a much earlier-stage technology, and we are not aware of existing attempts to deploy it in an aerial context. In this paper, we present what is thus, to our knowledge, the first system to perform simultaneous mapping and multi-person 3D human pose estimation from a monocular camera mounted on a single UAV. In particular, we show how to loosely couple state-of-the-art monocular depth estimation and monocular 3D human pose estimation approaches to reconstruct a hybrid map of a populated indoor scene in real time. We validate our component-level design choices via extensive experiments on the large-scale ScanNet and GTA-IM datasets. To evaluate our system-level performance, we also construct a new Oxford Hybrid Mapping dataset of populated indoor scenes.
Beyond Controlled Environments: 3D Camera Re-Localization in Changing Indoor Scenes
Aug 05, 2020
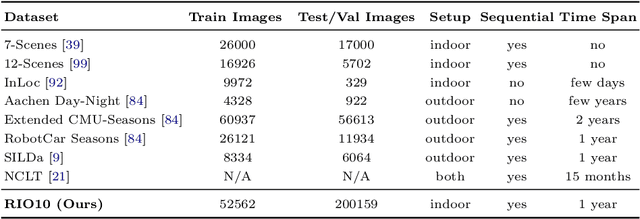
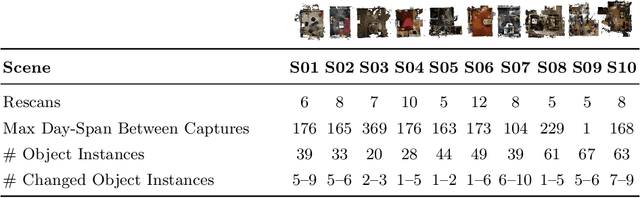

Long-term camera re-localization is an important task with numerous computer vision and robotics applications. Whilst various outdoor benchmarks exist that target lighting, weather and seasonal changes, far less attention has been paid to appearance changes that occur indoors. This has led to a mismatch between popular indoor benchmarks, which focus on static scenes, and indoor environments that are of interest for many real-world applications. In this paper, we adapt 3RScan - a recently introduced indoor RGB-D dataset designed for object instance re-localization - to create RIO10, a new long-term camera re-localization benchmark focused on indoor scenes. We propose new metrics for evaluating camera re-localization and explore how state-of-the-art camera re-localizers perform according to these metrics. We also examine in detail how different types of scene change affect the performance of different methods, based on novel ways of detecting such changes in a given RGB-D frame. Our results clearly show that long-term indoor re-localization is an unsolved problem. Our benchmark and tools are publicly available at waldjohannau.github.io/RIO10
Calibrating Deep Neural Networks using Focal Loss
Feb 21, 2020



Miscalibration -- a mismatch between a model's confidence and its correctness -- of Deep Neural Networks (DNNs) makes their predictions hard to rely on. Ideally, we want networks to be accurate, calibrated and confident. We show that, as opposed to the standard cross-entropy loss, focal loss (Lin et al., 2017) allows us to learn models that are already very well calibrated. When combined with temperature scaling, whilst preserving accuracy, it yields state-of-the-art calibrated models. We provide a thorough analysis of the factors causing miscalibration, and use the insights we glean from this to justify the empirically excellent performance of focal loss. To facilitate the use of focal loss in practice, we also provide a principled approach to automatically select the hyperparameter involved in the loss function. We perform extensive experiments on a variety of computer vision and NLP datasets, and with a wide variety of network architectures, and show that our approach achieves state-of-the-art accuracy and calibration in almost all cases.
Real-Time Highly Accurate Dense Depth on a Power Budget using an FPGA-CPU Hybrid SoC
Jul 17, 2019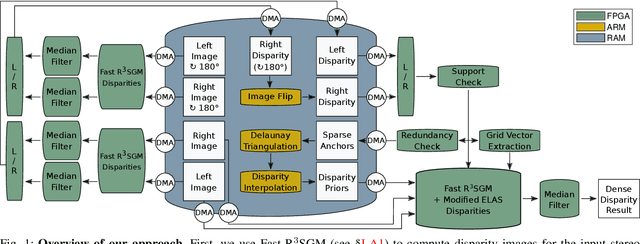
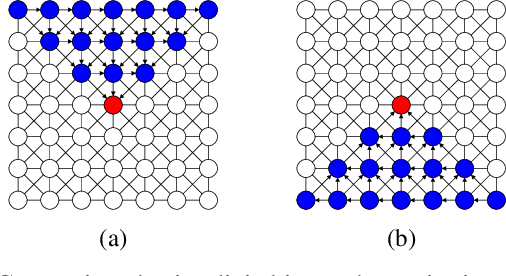

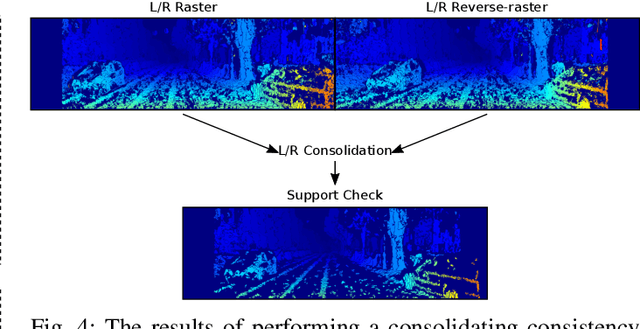
Obtaining highly accurate depth from stereo images in real time has many applications across computer vision and robotics, but in some contexts, upper bounds on power consumption constrain the feasible hardware to embedded platforms such as FPGAs. Whilst various stereo algorithms have been deployed on these platforms, usually cut down to better match the embedded architecture, certain key parts of the more advanced algorithms, e.g. those that rely on unpredictable access to memory or are highly iterative in nature, are difficult to deploy efficiently on FPGAs, and thus the depth quality that can be achieved is limited. In this paper, we leverage a FPGA-CPU chip to propose a novel, sophisticated, stereo approach that combines the best features of SGM and ELAS-based methods to compute highly accurate dense depth in real time. Our approach achieves an 8.7% error rate on the challenging KITTI 2015 dataset at over 50 FPS, with a power consumption of only 5W.
* 6 pages, 7 figures, 2 tables, journal
Let's Take This Online: Adapting Scene Coordinate Regression Network Predictions for Online RGB-D Camera Relocalisation
Jun 20, 2019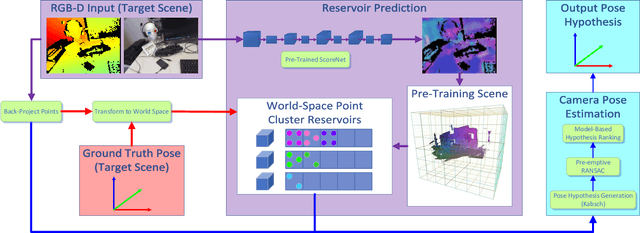
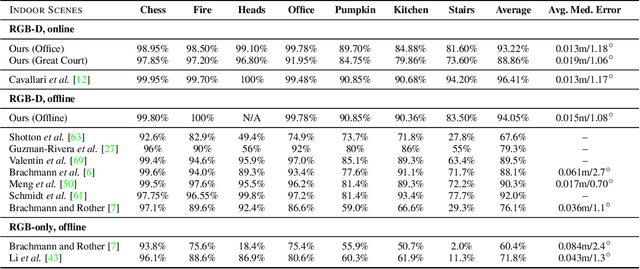
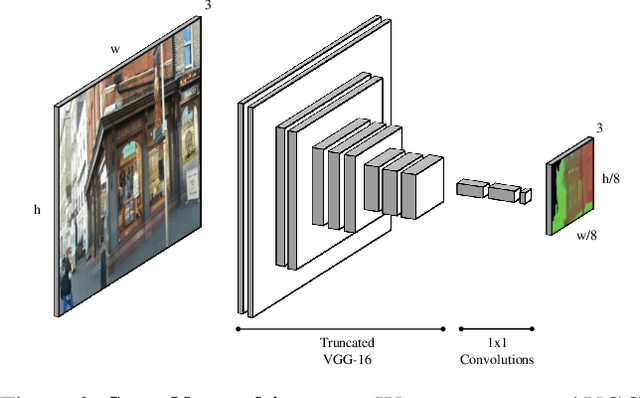
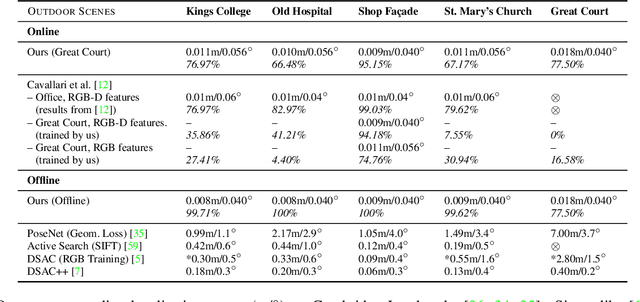
Many applications require a camera to be relocalised online, without expensive offline training on the target scene. Whilst both keyframe and sparse keypoint matching methods can be used online, the former often fail away from the training trajectory, and the latter can struggle in textureless regions. By contrast, scene coordinate regression (SCoRe) methods generalise to novel poses and can leverage dense correspondences to improve robustness, and recent work has shown how to adapt SCoRe forests between scenes, allowing their state-of-the-art performance to be leveraged online. However, because they use features hand-crafted for indoor use, they do not generalise well to harder outdoor scenes. Whilst replacing the forest with a neural network and learning suitable features for outdoor use is possible, the techniques used to adapt forests between scenes are unfortunately harder to transfer to a network context. In this paper, we address this by proposing a novel way of leveraging a network trained on one scene to predict points in another scene. Our approach replaces the appearance clustering performed by the branching structure of a regression forest with a two-step process that first uses the network to predict points in the original scene, and then uses these predicted points to look up clusters of points from the new scene. We show experimentally that our online approach achieves state-of-the-art performance on both the 7-Scenes and Cambridge Landmarks datasets, whilst running in under 300ms, making it highly effective in live scenarios.
Straight to Shapes++: Real-time Instance Segmentation Made More Accurate
May 27, 2019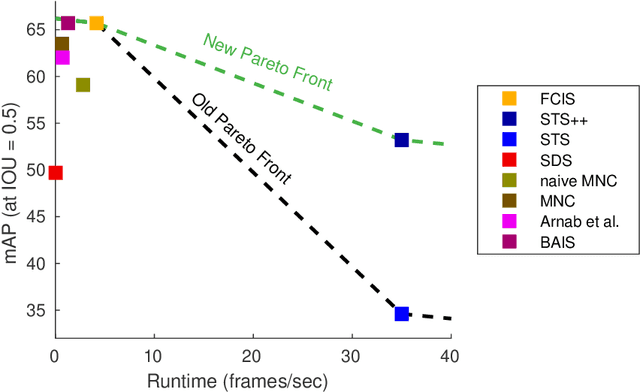
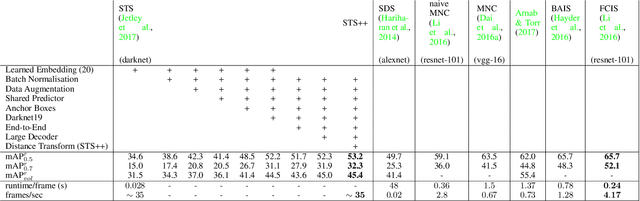
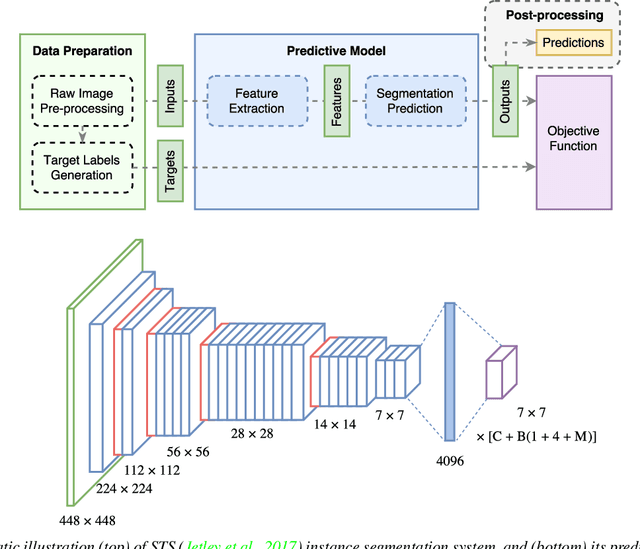
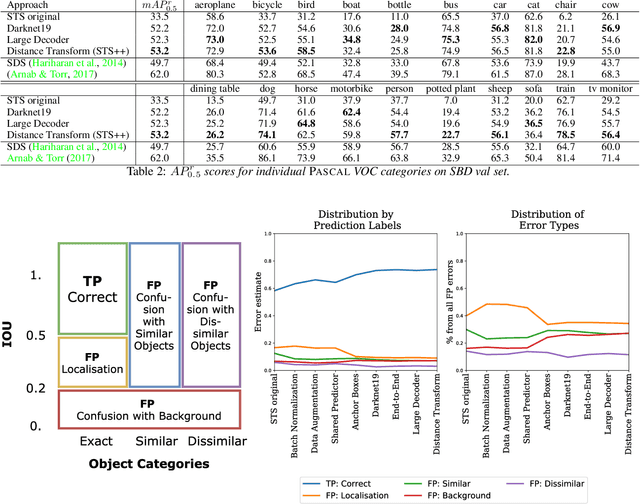
Instance segmentation is an important problem in computer vision, with applications in autonomous driving, drone navigation and robotic manipulation. However, most existing methods are not real-time, complicating their deployment in time-sensitive contexts. In this work, we extend an existing approach to real-time instance segmentation, called `Straight to Shapes' (STS), which makes use of low-dimensional shape embedding spaces to directly regress to object shape masks. The STS model can run at 35 FPS on a high-end desktop, but its accuracy is significantly worse than that of offline state-of-the-art methods. We leverage recent advances in the design and training of deep instance segmentation models to improve the performance accuracy of the STS model whilst keeping its real-time capabilities intact. In particular, we find that parameter sharing, more aggressive data augmentation and the use of structured loss for shape mask prediction all provide a useful boost to the network performance. Our proposed approach, `Straight to Shapes++', achieves a remarkable 19.7 point improvement in mAP (at IOU of 0.5) over the original method as evaluated on the PASCAL VOC dataset, thus redefining the accuracy frontier at real-time speeds. Since the accuracy of instance segmentation is closely tied to that of object bounding box prediction, we also study the error profile of the latter and examine the failure modes of our method for future improvements.
R$^3$SGM: Real-time Raster-Respecting Semi-Global Matching for Power-Constrained Systems
Oct 30, 2018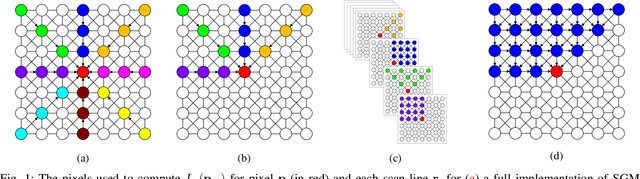
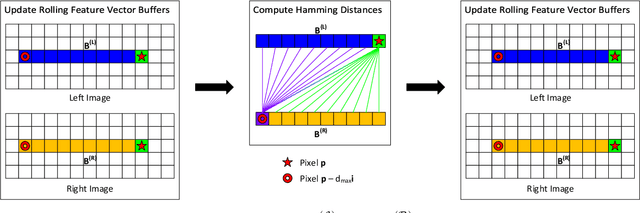
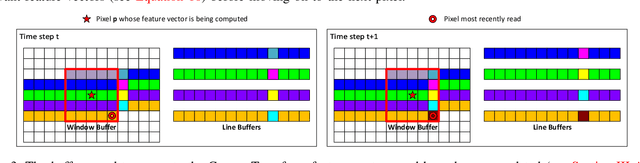
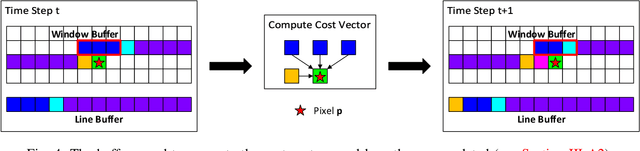
Stereo depth estimation is used for many computer vision applications. Though many popular methods strive solely for depth quality, for real-time mobile applications (e.g. prosthetic glasses or micro-UAVs), speed and power efficiency are equally, if not more, important. Many real-world systems rely on Semi-Global Matching (SGM) to achieve a good accuracy vs. speed balance, but power efficiency is hard to achieve with conventional hardware, making the use of embedded devices such as FPGAs attractive for low-power applications. However, the full SGM algorithm is ill-suited to deployment on FPGAs, and so most FPGA variants of it are partial, at the expense of accuracy. In a non-FPGA context, the accuracy of SGM has been improved by More Global Matching (MGM), which also helps tackle the streaking artifacts that afflict SGM. In this paper, we propose a novel, resource-efficient method that is inspired by MGM's techniques for improving depth quality, but which can be implemented to run in real time on a low-power FPGA. Through evaluation on multiple datasets (KITTI and Middlebury), we show that in comparison to other real-time capable stereo approaches, we can achieve a state-of-the-art balance between accuracy, power efficiency and speed, making our approach highly desirable for use in real-time systems with limited power.
Real-Time RGB-D Camera Pose Estimation in Novel Scenes using a Relocalisation Cascade
Oct 29, 2018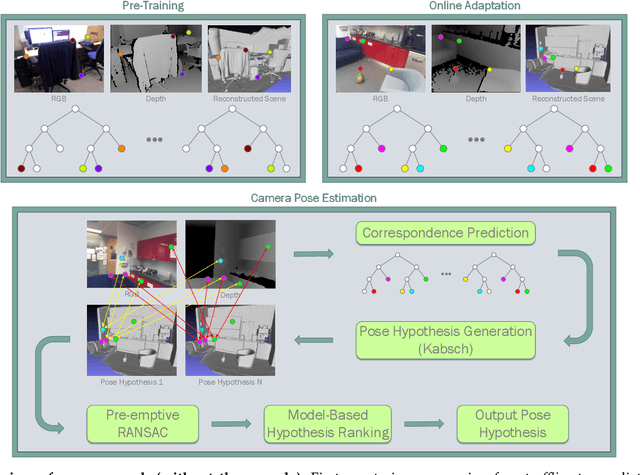
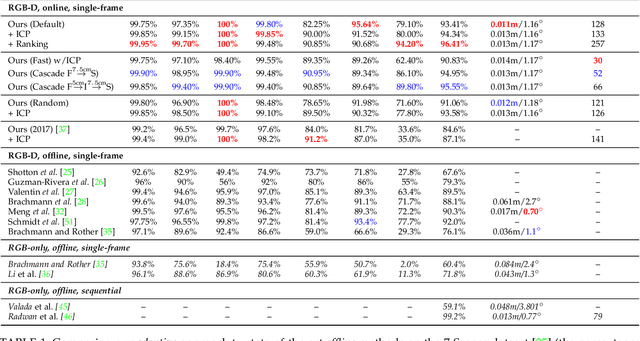

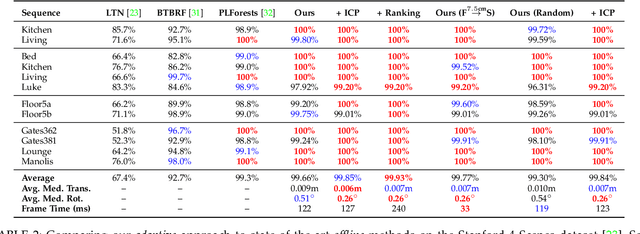
Camera pose estimation is an important problem in computer vision. Common techniques either match the current image against keyframes with known poses, directly regress the pose, or establish correspondences between keypoints in the image and points in the scene to estimate the pose. In recent years, regression forests have become a popular alternative to establish such correspondences. They achieve accurate results, but have traditionally needed to be trained offline on the target scene, preventing relocalisation in new environments. Recently, we showed how to circumvent this limitation by adapting a pre-trained forest to a new scene on the fly. The adapted forests achieved relocalisation performance that was on par with that of offline forests, and our approach was able to estimate the camera pose in close to real time. In this paper, we present an extension of this work that achieves significantly better relocalisation performance whilst running fully in real time. To achieve this, we make several changes to the original approach: (i) instead of accepting the camera pose hypothesis without question, we make it possible to score the final few hypotheses using a geometric approach and select the most promising; (ii) we chain several instantiations of our relocaliser together in a cascade, allowing us to try faster but less accurate relocalisation first, only falling back to slower, more accurate relocalisation as necessary; and (iii) we tune the parameters of our cascade to achieve effective overall performance. These changes allow us to significantly improve upon the performance our original state-of-the-art method was able to achieve on the well-known 7-Scenes and Stanford 4 Scenes benchmarks. As additional contributions, we present a way of visualising the internal behaviour of our forests and show how to entirely circumvent the need to pre-train a forest on a generic scene.