 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStraight to Shapes++: Real-time Instance Segmentation Made More Accurate
May 27, 2019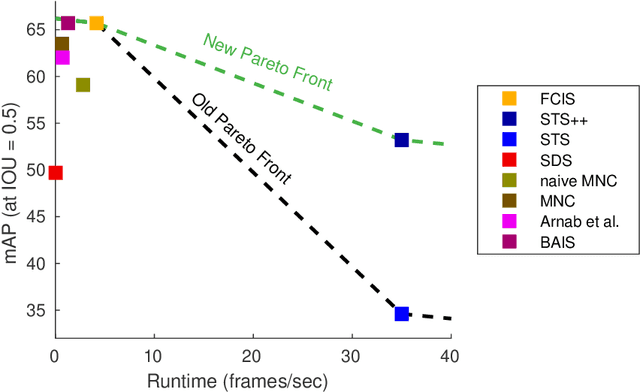
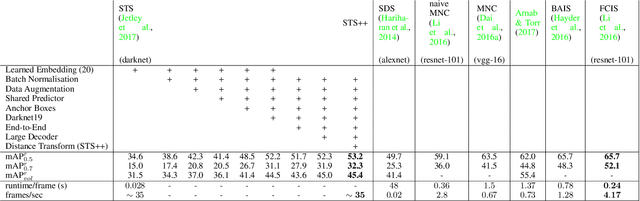
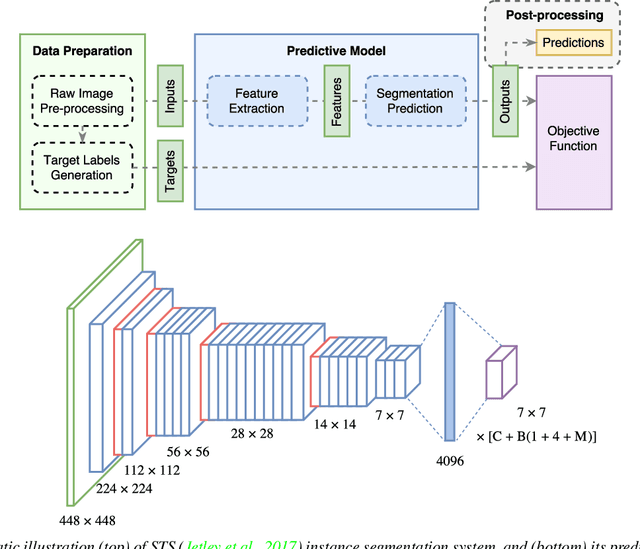
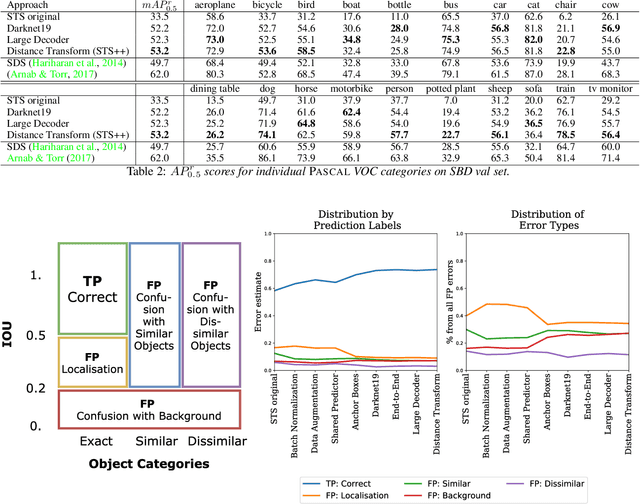
Instance segmentation is an important problem in computer vision, with applications in autonomous driving, drone navigation and robotic manipulation. However, most existing methods are not real-time, complicating their deployment in time-sensitive contexts. In this work, we extend an existing approach to real-time instance segmentation, called `Straight to Shapes' (STS), which makes use of low-dimensional shape embedding spaces to directly regress to object shape masks. The STS model can run at 35 FPS on a high-end desktop, but its accuracy is significantly worse than that of offline state-of-the-art methods. We leverage recent advances in the design and training of deep instance segmentation models to improve the performance accuracy of the STS model whilst keeping its real-time capabilities intact. In particular, we find that parameter sharing, more aggressive data augmentation and the use of structured loss for shape mask prediction all provide a useful boost to the network performance. Our proposed approach, `Straight to Shapes++', achieves a remarkable 19.7 point improvement in mAP (at IOU of 0.5) over the original method as evaluated on the PASCAL VOC dataset, thus redefining the accuracy frontier at real-time speeds. Since the accuracy of instance segmentation is closely tied to that of object bounding box prediction, we also study the error profile of the latter and examine the failure modes of our method for future improvements.
With Friends Like These, Who Needs Adversaries?
Jul 23, 2018

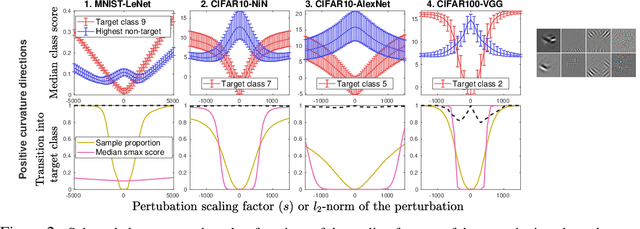
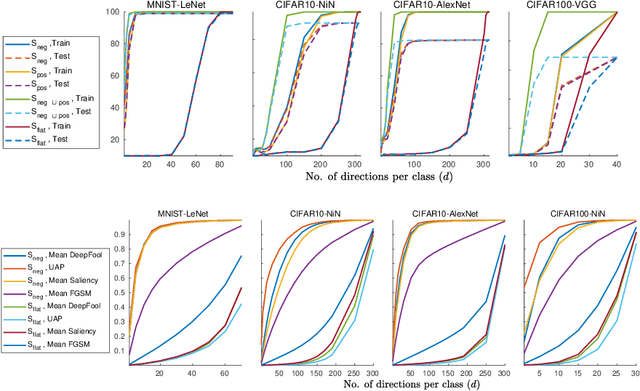
The vulnerability of deep image classification networks to adversarial attack is now well known, but less well understood. Via a novel experimental analysis, we illustrate some facts about deep convolutional networks (DCNs) that shed new light on their behaviour and its connection to the problem of adversaries, with two key results. The first is a straightforward explanation of the existence of universal adversarial perturbations and their association with specific class identities, obtained by analysing the properties of nets' logit responses as functions of 1D movements along specific image-space directions. The second is the clear demonstration of the tight coupling between classification performance and vulnerability to adversarial attack within the spaces spanned by these directions. Prior work has noted the importance of low-dimensional subspaces in adversarial vulnerability: we illustrate that this likewise represents the nets' notion of saliency. In all, we provide a digestible perspective from which to understand previously reported results which have appeared disjoint or contradictory, with implications for efforts to construct neural nets that are both accurate and robust to adversarial attack.
Learn To Pay Attention
Apr 26, 2018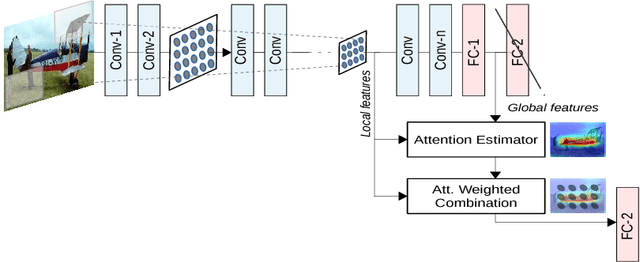
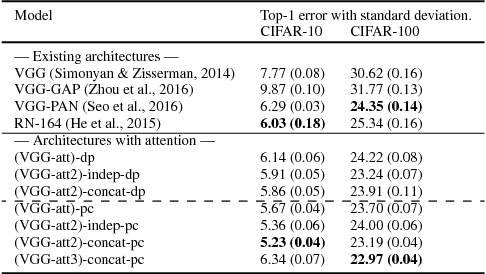
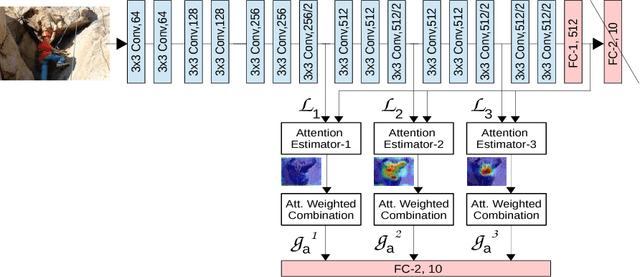
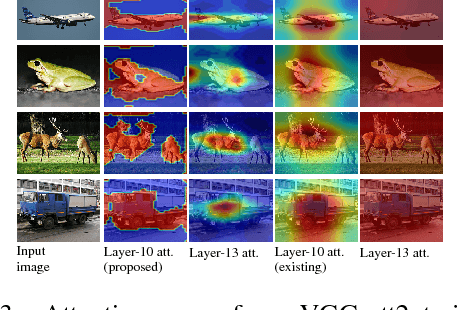
We propose an end-to-end-trainable attention module for convolutional neural network (CNN) architectures built for image classification. The module takes as input the 2D feature vector maps which form the intermediate representations of the input image at different stages in the CNN pipeline, and outputs a 2D matrix of scores for each map. Standard CNN architectures are modified through the incorporation of this module, and trained under the constraint that a convex combination of the intermediate 2D feature vectors, as parameterised by the score matrices, must \textit{alone} be used for classification. Incentivised to amplify the relevant and suppress the irrelevant or misleading, the scores thus assume the role of attention values. Our experimental observations provide clear evidence to this effect: the learned attention maps neatly highlight the regions of interest while suppressing background clutter. Consequently, the proposed function is able to bootstrap standard CNN architectures for the task of image classification, demonstrating superior generalisation over 6 unseen benchmark datasets. When binarised, our attention maps outperform other CNN-based attention maps, traditional saliency maps, and top object proposals for weakly supervised segmentation as demonstrated on the Object Discovery dataset. We also demonstrate improved robustness against the fast gradient sign method of adversarial attack.
Prototypical Priors: From Improving Classification to Zero-Shot Learning
Apr 25, 2018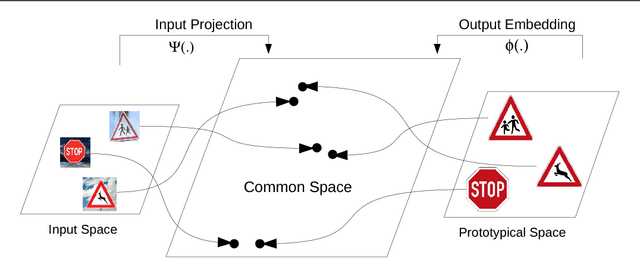
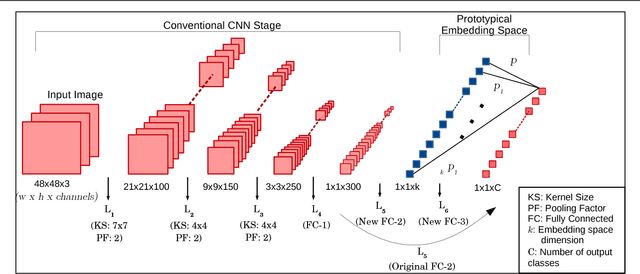
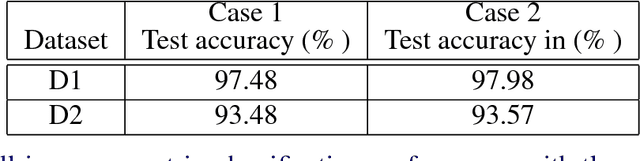
Recent works on zero-shot learning make use of side information such as visual attributes or natural language semantics to define the relations between output visual classes and then use these relationships to draw inference on new unseen classes at test time. In a novel extension to this idea, we propose the use of visual prototypical concepts as side information. For most real-world visual object categories, it may be difficult to establish a unique prototype. However, in cases such as traffic signs, brand logos, flags, and even natural language characters, these prototypical templates are available and can be leveraged for an improved recognition performance. The present work proposes a way to incorporate this prototypical information in a deep learning framework. Using prototypes as prior information, the deepnet pipeline learns the input image projections into the prototypical embedding space subject to minimization of the final classification loss. Based on our experiments with two different datasets of traffic signs and brand logos, prototypical embeddings incorporated in a conventional convolutional neural network improve the recognition performance. Recognition accuracy on the Belga logo dataset is especially noteworthy and establishes a new state-of-the-art. In zero-shot learning scenarios, the same system can be directly deployed to draw inference on unseen classes by simply adding the prototypical information for these new classes at test time. Thus, unlike earlier approaches, testing on seen and unseen classes is handled using the same pipeline, and the system can be tuned for a trade-off of seen and unseen class performance as per task requirement. Comparison with one of the latest works in the zero-shot learning domain yields top results on the two datasets mentioned above.
End-to-End Saliency Mapping via Probability Distribution Prediction
Apr 05, 2018

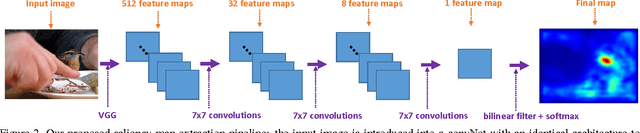
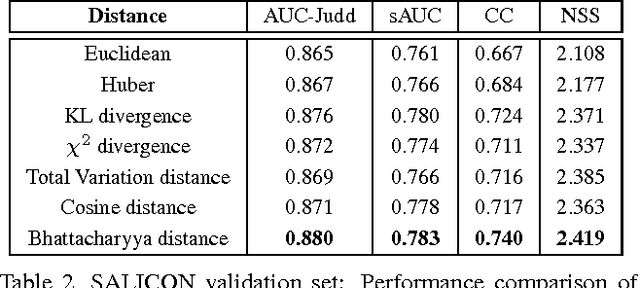
Most saliency estimation methods aim to explicitly model low-level conspicuity cues such as edges or blobs and may additionally incorporate top-down cues using face or text detection. Data-driven methods for training saliency models using eye-fixation data are increasingly popular, particularly with the introduction of large-scale datasets and deep architectures. However, current methods in this latter paradigm use loss functions designed for classification or regression tasks whereas saliency estimation is evaluated on topographical maps. In this work, we introduce a new saliency map model which formulates a map as a generalized Bernoulli distribution. We then train a deep architecture to predict such maps using novel loss functions which pair the softmax activation function with measures designed to compute distances between probability distributions. We show in extensive experiments the effectiveness of such loss functions over standard ones on four public benchmark datasets, and demonstrate improved performance over state-of-the-art saliency methods.
Straight to Shapes: Real-time Detection of Encoded Shapes
Jul 05, 2017


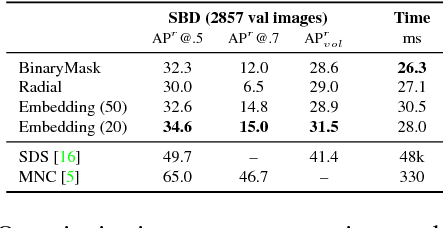
Current object detection approaches predict bounding boxes, but these provide little instance-specific information beyond location, scale and aspect ratio. In this work, we propose to directly regress to objects' shapes in addition to their bounding boxes and categories. It is crucial to find an appropriate shape representation that is compact and decodable, and in which objects can be compared for higher-order concepts such as view similarity, pose variation and occlusion. To achieve this, we use a denoising convolutional auto-encoder to establish an embedding space, and place the decoder after a fast end-to-end network trained to regress directly to the encoded shape vectors. This yields what to the best of our knowledge is the first real-time shape prediction network, running at ~35 FPS on a high-end desktop. With higher-order shape reasoning well-integrated into the network pipeline, the network shows the useful practical quality of generalising to unseen categories similar to the ones in the training set, something that most existing approaches fail to handle.