 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantum Circuit Optimization with AlphaTensor
Mar 05, 2024



A key challenge in realizing fault-tolerant quantum computers is circuit optimization. Focusing on the most expensive gates in fault-tolerant quantum computation (namely, the T gates), we address the problem of T-count optimization, i.e., minimizing the number of T gates that are needed to implement a given circuit. To achieve this, we develop AlphaTensor-Quantum, a method based on deep reinforcement learning that exploits the relationship between optimizing T-count and tensor decomposition. Unlike existing methods for T-count optimization, AlphaTensor-Quantum can incorporate domain-specific knowledge about quantum computation and leverage gadgets, which significantly reduces the T-count of the optimized circuits. AlphaTensor-Quantum outperforms the existing methods for T-count optimization on a set of arithmetic benchmarks (even when compared without making use of gadgets). Remarkably, it discovers an efficient algorithm akin to Karatsuba's method for multiplication in finite fields. AlphaTensor-Quantum also finds the best human-designed solutions for relevant arithmetic computations used in Shor's algorithm and for quantum chemistry simulation, thus demonstrating it can save hundreds of hours of research by optimizing relevant quantum circuits in a fully automated way.
A Hierarchical Probabilistic U-Net for Modeling Multi-Scale Ambiguities
May 30, 2019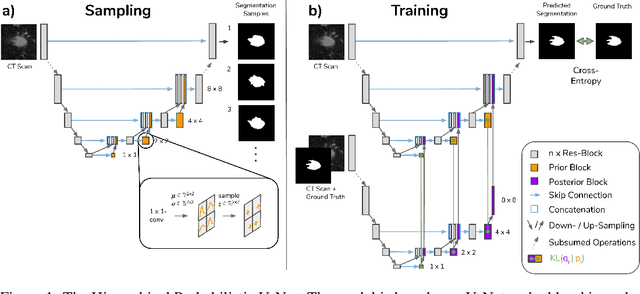
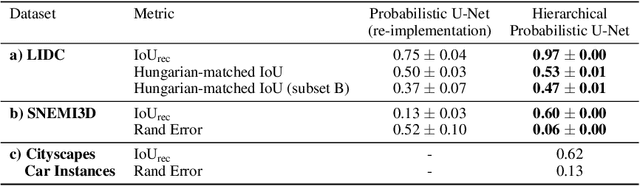
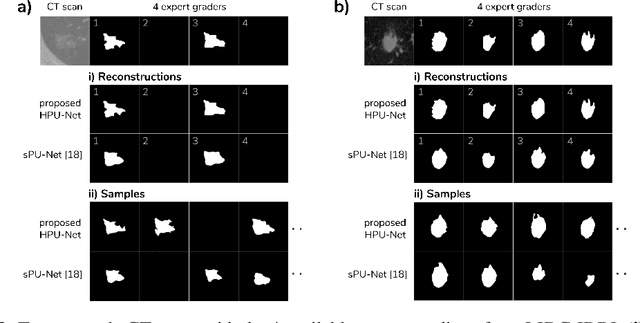

Medical imaging only indirectly measures the molecular identity of the tissue within each voxel, which often produces only ambiguous image evidence for target measures of interest, like semantic segmentation. This diversity and the variations of plausible interpretations are often specific to given image regions and may thus manifest on various scales, spanning all the way from the pixel to the image level. In order to learn a flexible distribution that can account for multiple scales of variations, we propose the Hierarchical Probabilistic U-Net, a segmentation network with a conditional variational auto-encoder (cVAE) that uses a hierarchical latent space decomposition. We show that this model formulation enables sampling and reconstruction of segmenations with high fidelity, i.e. with finely resolved detail, while providing the flexibility to learn complex structured distributions across scales. We demonstrate these abilities on the task of segmenting ambiguous medical scans as well as on instance segmentation of neurobiological and natural images. Our model automatically separates independent factors across scales, an inductive bias that we deem beneficial in structured output prediction tasks beyond segmentation.
A Probabilistic U-Net for Segmentation of Ambiguous Images
Oct 29, 2018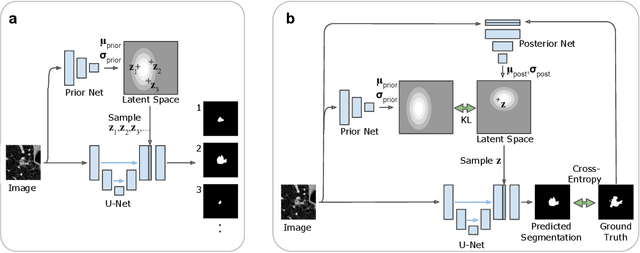

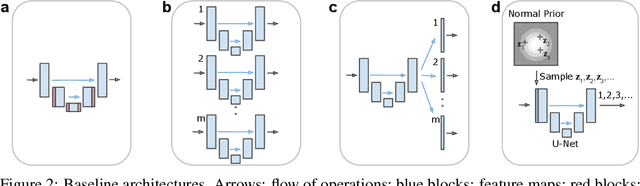

Many real-world vision problems suffer from inherent ambiguities. In clinical applications for example, it might not be clear from a CT scan alone which particular region is cancer tissue. Therefore a group of graders typically produces a set of diverse but plausible segmentations. We consider the task of learning a distribution over segmentations given an input. To this end we propose a generative segmentation model based on a combination of a U-Net with a conditional variational autoencoder that is capable of efficiently producing an unlimited number of plausible hypotheses. We show on a lung abnormalities segmentation task and on a Cityscapes segmentation task that our model reproduces the possible segmentation variants as well as the frequencies with which they occur, doing so significantly better than published approaches. These models could have a high impact in real-world applications, such as being used as clinical decision-making algorithms accounting for multiple plausible semantic segmentation hypotheses to provide possible diagnoses and recommend further actions to resolve the present ambiguities.
Deep learning to achieve clinically applicable segmentation of head and neck anatomy for radiotherapy
Sep 12, 2018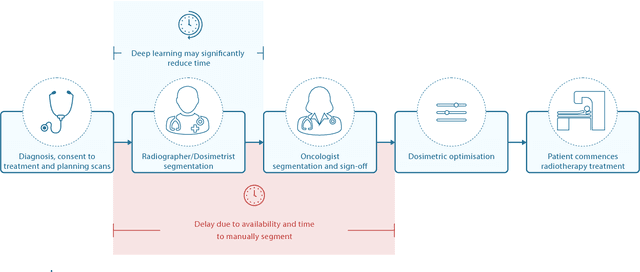
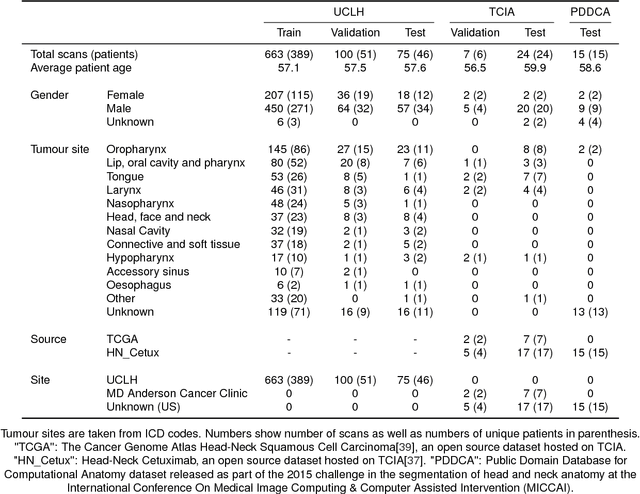
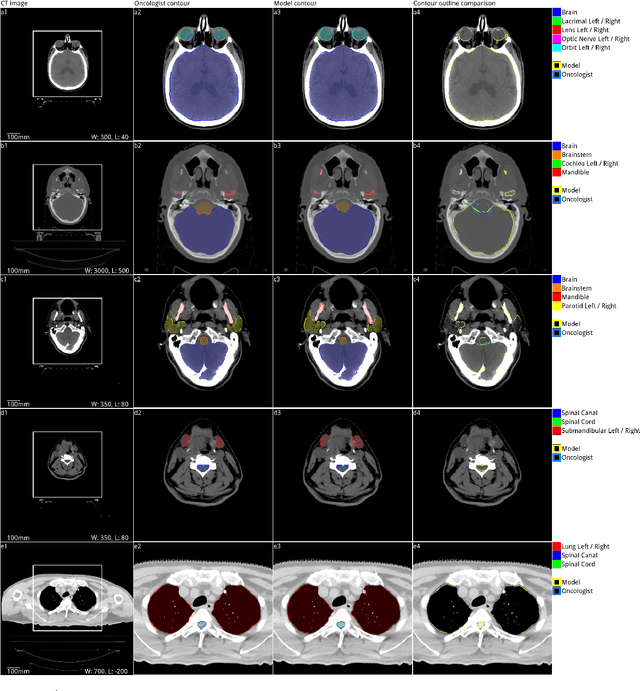
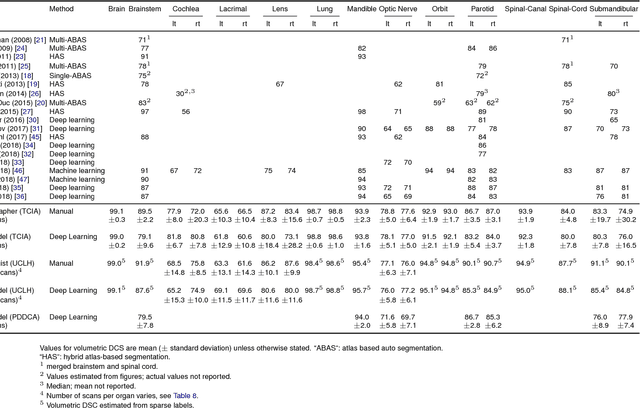
Over half a million individuals are diagnosed with head and neck cancer each year worldwide. Radiotherapy is an important curative treatment for this disease, but it requires manually intensive delineation of radiosensitive organs at risk (OARs). This planning process can delay treatment commencement. While auto-segmentation algorithms offer a potentially time-saving solution, the challenges in defining, quantifying and achieving expert performance remain. Adopting a deep learning approach, we demonstrate a 3D U-Net architecture that achieves performance similar to experts in delineating a wide range of head and neck OARs. The model was trained on a dataset of 663 deidentified computed tomography (CT) scans acquired in routine clinical practice and segmented according to consensus OAR definitions. We demonstrate its generalisability through application to an independent test set of 24 CT scans available from The Cancer Imaging Archive collected at multiple international sites previously unseen to the model, each segmented by two independent experts and consisting of 21 OARs commonly segmented in clinical practice. With appropriate validation studies and regulatory approvals, this system could improve the effectiveness of radiotherapy pathways.
Prototypical Priors: From Improving Classification to Zero-Shot Learning
Apr 25, 2018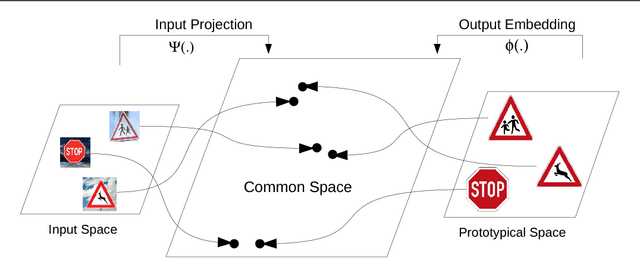
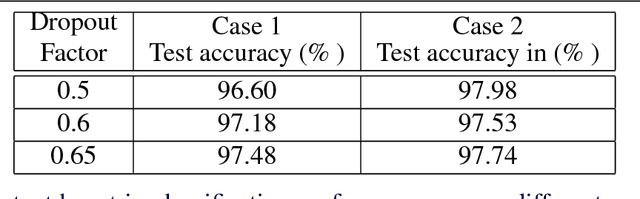
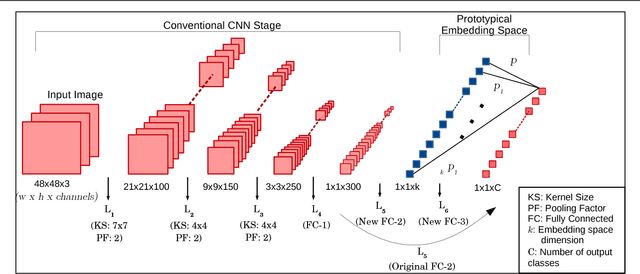
Recent works on zero-shot learning make use of side information such as visual attributes or natural language semantics to define the relations between output visual classes and then use these relationships to draw inference on new unseen classes at test time. In a novel extension to this idea, we propose the use of visual prototypical concepts as side information. For most real-world visual object categories, it may be difficult to establish a unique prototype. However, in cases such as traffic signs, brand logos, flags, and even natural language characters, these prototypical templates are available and can be leveraged for an improved recognition performance. The present work proposes a way to incorporate this prototypical information in a deep learning framework. Using prototypes as prior information, the deepnet pipeline learns the input image projections into the prototypical embedding space subject to minimization of the final classification loss. Based on our experiments with two different datasets of traffic signs and brand logos, prototypical embeddings incorporated in a conventional convolutional neural network improve the recognition performance. Recognition accuracy on the Belga logo dataset is especially noteworthy and establishes a new state-of-the-art. In zero-shot learning scenarios, the same system can be directly deployed to draw inference on unseen classes by simply adding the prototypical information for these new classes at test time. Thus, unlike earlier approaches, testing on seen and unseen classes is handled using the same pipeline, and the system can be tuned for a trade-off of seen and unseen class performance as per task requirement. Comparison with one of the latest works in the zero-shot learning domain yields top results on the two datasets mentioned above.
Recurrent Instance Segmentation
Oct 24, 2016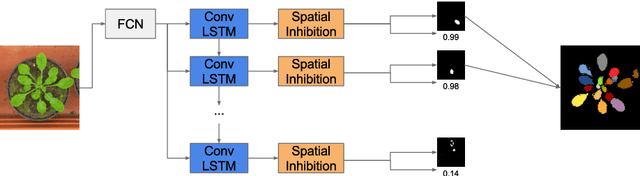
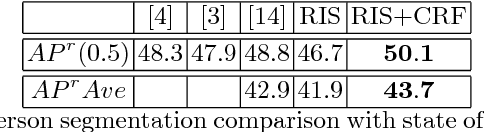
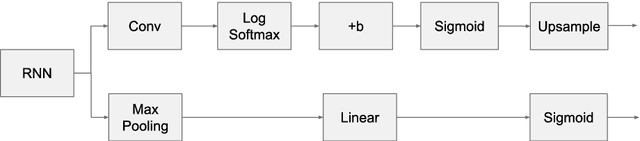
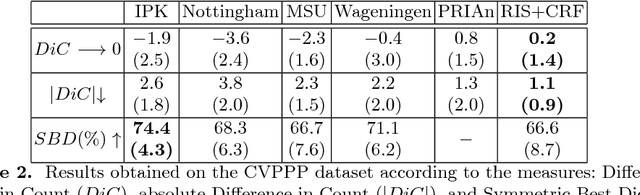
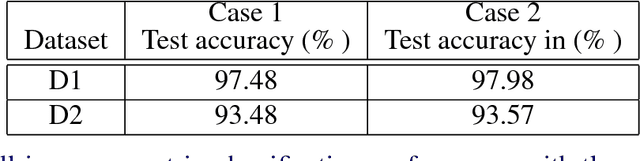
Instance segmentation is the problem of detecting and delineating each distinct object of interest appearing in an image. Current instance segmentation approaches consist of ensembles of modules that are trained independently of each other, thus missing opportunities for joint learning. Here we propose a new instance segmentation paradigm consisting in an end-to-end method that learns how to segment instances sequentially. The model is based on a recurrent neural network that sequentially finds objects and their segmentations one at a time. This net is provided with a spatial memory that keeps track of what pixels have been explained and allows occlusion handling. In order to train the model we designed a principled loss function that accurately represents the properties of the instance segmentation problem. In the experiments carried out, we found that our method outperforms recent approaches on multiple person segmentation, and all state of the art approaches on the Plant Phenotyping dataset for leaf counting.
* 14 pages (main paper). 24 pages including references and appendix
Conditional Random Fields as Recurrent Neural Networks
Apr 13, 2016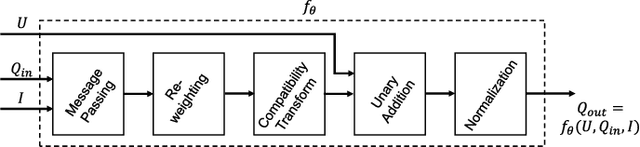

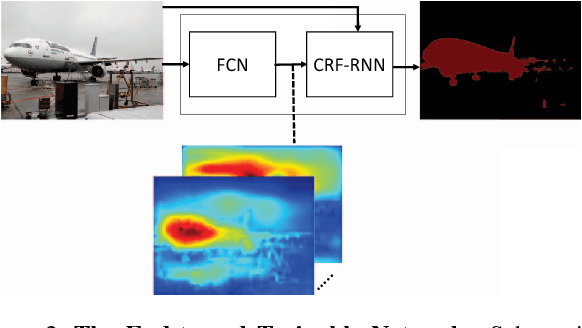
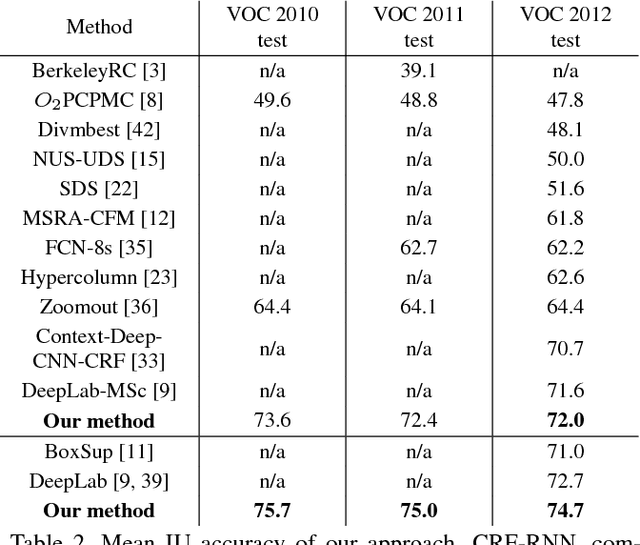
Pixel-level labelling tasks, such as semantic segmentation, play a central role in image understanding. Recent approaches have attempted to harness the capabilities of deep learning techniques for image recognition to tackle pixel-level labelling tasks. One central issue in this methodology is the limited capacity of deep learning techniques to delineate visual objects. To solve this problem, we introduce a new form of convolutional neural network that combines the strengths of Convolutional Neural Networks (CNNs) and Conditional Random Fields (CRFs)-based probabilistic graphical modelling. To this end, we formulate mean-field approximate inference for the Conditional Random Fields with Gaussian pairwise potentials as Recurrent Neural Networks. This network, called CRF-RNN, is then plugged in as a part of a CNN to obtain a deep network that has desirable properties of both CNNs and CRFs. Importantly, our system fully integrates CRF modelling with CNNs, making it possible to train the whole deep network end-to-end with the usual back-propagation algorithm, avoiding offline post-processing methods for object delineation. We apply the proposed method to the problem of semantic image segmentation, obtaining top results on the challenging Pascal VOC 2012 segmentation benchmark.
The Benefit of Multitask Representation Learning
Mar 25, 2016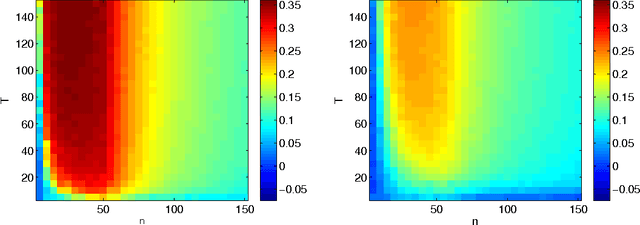
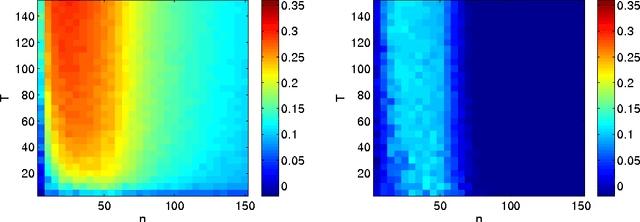
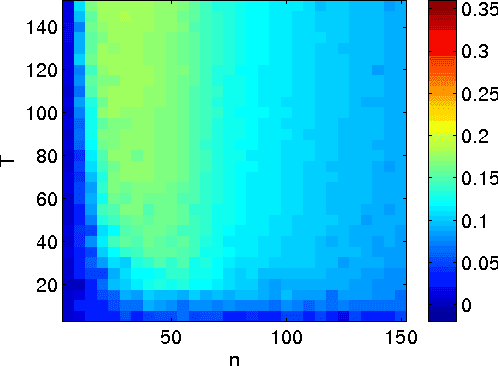
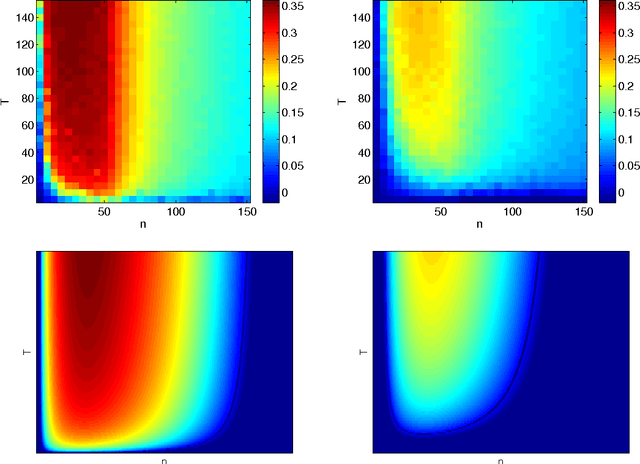
We discuss a general method to learn data representations from multiple tasks. We provide a justification for this method in both settings of multitask learning and learning-to-learn. The method is illustrated in detail in the special case of linear feature learning. Conditions on the theoretical advantage offered by multitask representation learning over independent task learning are established. In particular, focusing on the important example of half-space learning, we derive the regime in which multitask representation learning is beneficial over independent task learning, as a function of the sample size, the number of tasks and the intrinsic data dimensionality. Other potential applications of our results include multitask feature learning in reproducing kernel Hilbert spaces and multilayer, deep networks.
Sparse coding for multitask and transfer learning
Jun 16, 2014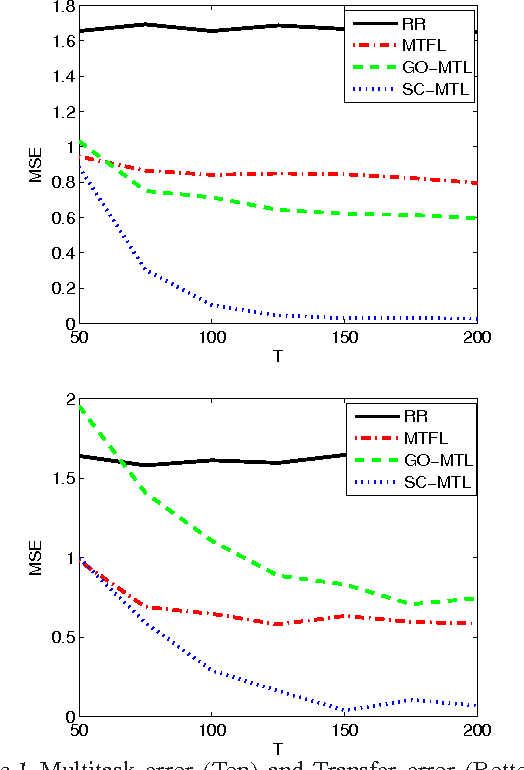
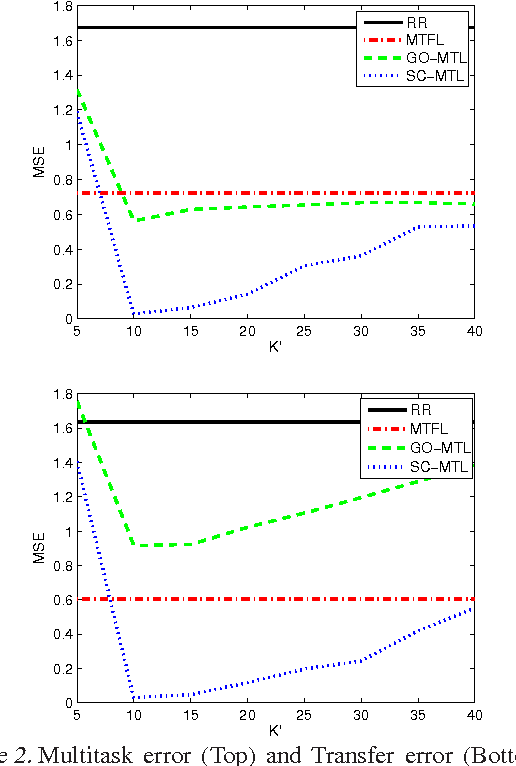
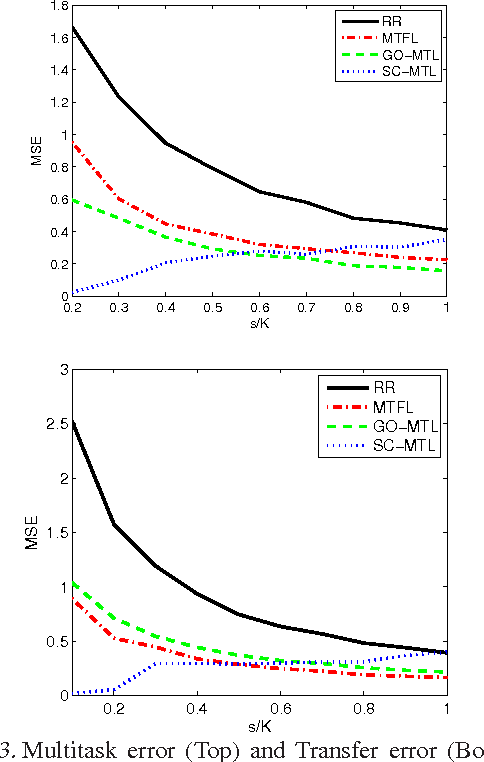
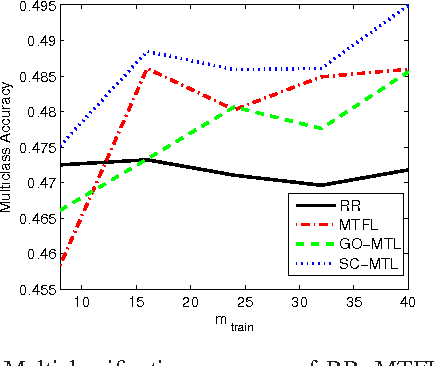
We investigate the use of sparse coding and dictionary learning in the context of multitask and transfer learning. The central assumption of our learning method is that the tasks parameters are well approximated by sparse linear combinations of the atoms of a dictionary on a high or infinite dimensional space. This assumption, together with the large quantity of available data in the multitask and transfer learning settings, allows a principled choice of the dictionary. We provide bounds on the generalization error of this approach, for both settings. Numerical experiments on one synthetic and two real datasets show the advantage of our method over single task learning, a previous method based on orthogonal and dense representation of the tasks and a related method learning task grouping.
An Inequality with Applications to Structured Sparsity and Multitask Dictionary Learning
Jun 07, 2014From concentration inequalities for the suprema of Gaussian or Rademacher processes an inequality is derived. It is applied to sharpen existing and to derive novel bounds on the empirical Rademacher complexities of unit balls in various norms appearing in the context of structured sparsity and multitask dictionary learning or matrix factorization. A key role is played by the largest eigenvalue of the data covariance matrix.