 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised MultiModal Versatile Networks
Jun 29, 2020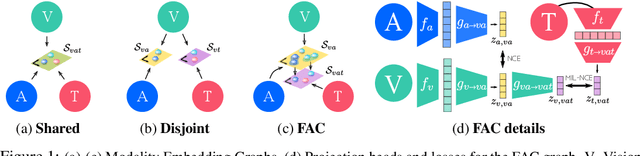
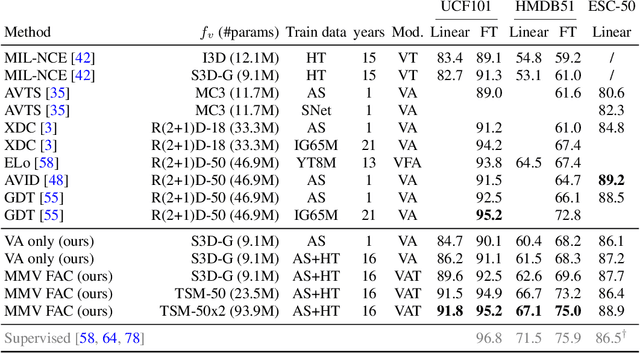
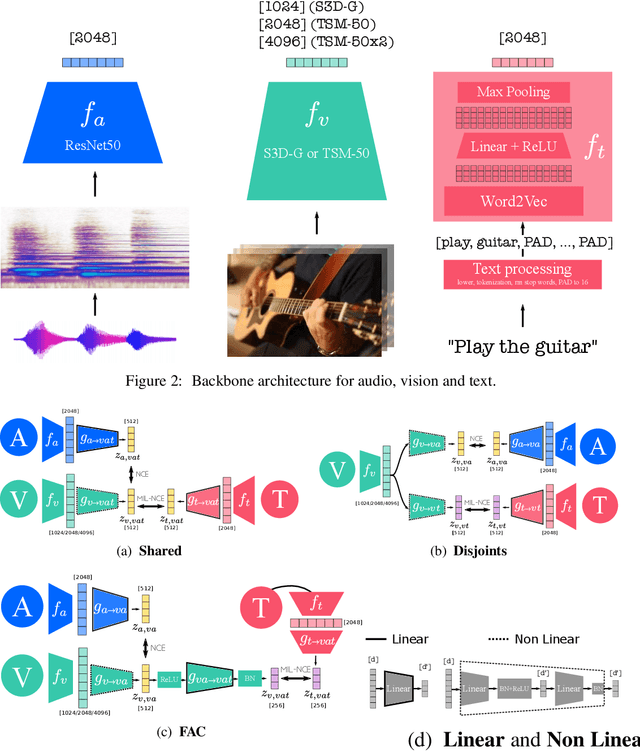
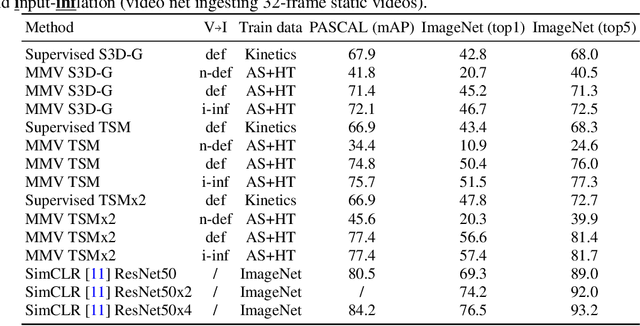
Videos are a rich source of multi-modal supervision. In this work, we learn representations using self-supervision by leveraging three modalities naturally present in videos: vision, audio and language. To this end, we introduce the notion of a multimodal versatile network -- a network that can ingest multiple modalities and whose representations enable downstream tasks in multiple modalities. In particular, we explore how best to combine the modalities, such that fine-grained representations of audio and vision can be maintained, whilst also integrating text into a common embedding. Driven by versatility, we also introduce a novel process of deflation, so that the networks can be effortlessly applied to the visual data in the form of video or a static image. We demonstrate how such networks trained on large collections of unlabelled video data can be applied on video, video-text, image and audio tasks. Equipped with these representations, we obtain state-of-the-art performance on multiple challenging benchmarks including UCF101, HMDB51 and ESC-50 when compared to previous self-supervised work.
Hierarchical Autoregressive Image Models with Auxiliary Decoders
Mar 06, 2019

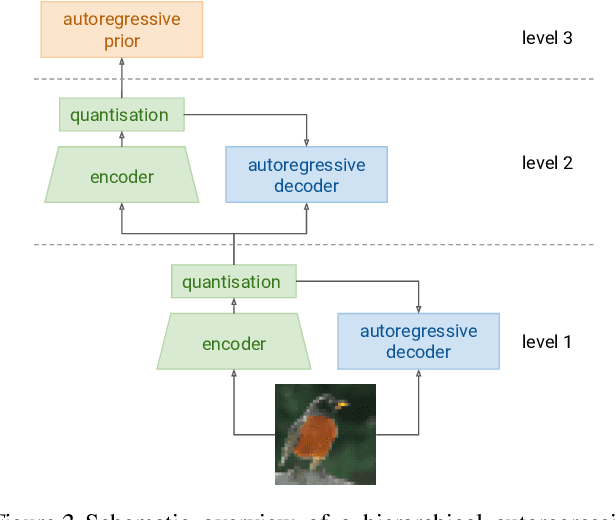
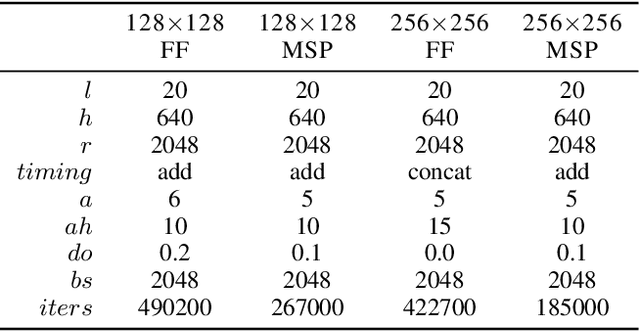
Autoregressive generative models of images tend to be biased towards capturing local structure, and as a result they often produce samples which are lacking in terms of large-scale coherence. To address this, we propose two methods to learn discrete representations of images which abstract away local detail. We show that autoregressive models conditioned on these representations can produce high-fidelity reconstructions of images, and that we can train autoregressive priors on these representations that produce samples with large-scale coherence. We can recursively apply the learning procedure, yielding a hierarchy of progressively more abstract image representations. We train hierarchical class-conditional autoregressive models on the ImageNet dataset and demonstrate that they are able to generate realistic images at resolutions of 128$\times$128 and 256$\times$256 pixels.
A Probabilistic U-Net for Segmentation of Ambiguous Images
Oct 29, 2018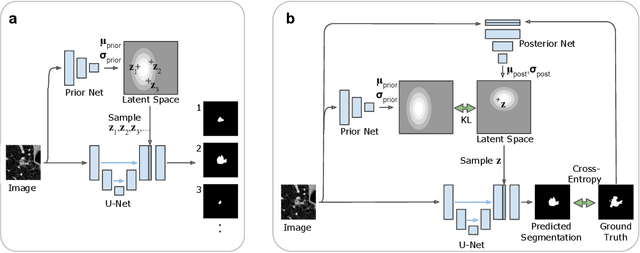


Many real-world vision problems suffer from inherent ambiguities. In clinical applications for example, it might not be clear from a CT scan alone which particular region is cancer tissue. Therefore a group of graders typically produces a set of diverse but plausible segmentations. We consider the task of learning a distribution over segmentations given an input. To this end we propose a generative segmentation model based on a combination of a U-Net with a conditional variational autoencoder that is capable of efficiently producing an unlimited number of plausible hypotheses. We show on a lung abnormalities segmentation task and on a Cityscapes segmentation task that our model reproduces the possible segmentation variants as well as the frequencies with which they occur, doing so significantly better than published approaches. These models could have a high impact in real-world applications, such as being used as clinical decision-making algorithms accounting for multiple plausible semantic segmentation hypotheses to provide possible diagnoses and recommend further actions to resolve the present ambiguities.
Deep learning to achieve clinically applicable segmentation of head and neck anatomy for radiotherapy
Sep 12, 2018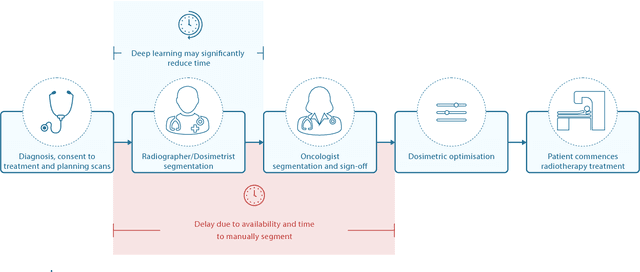
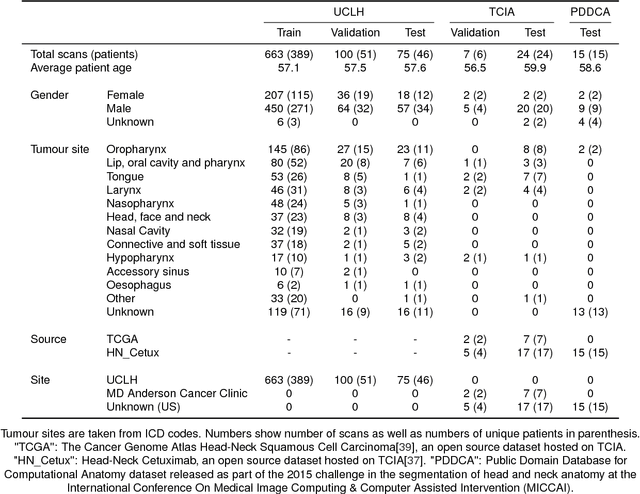
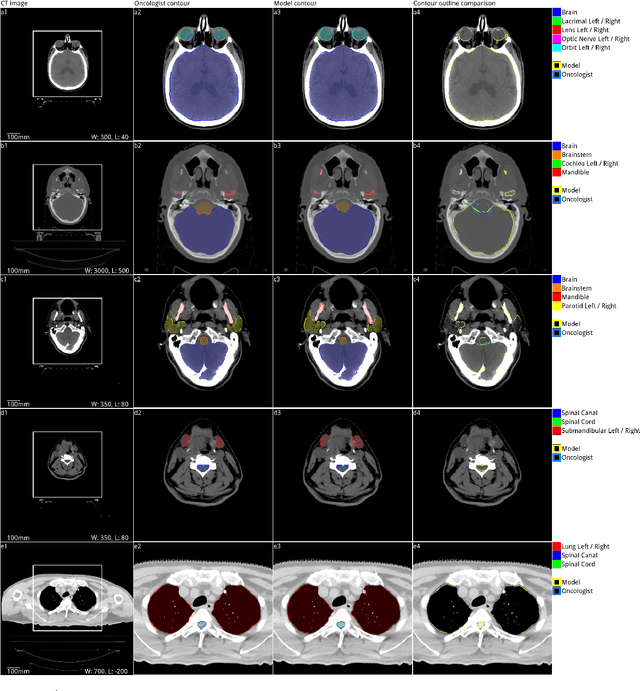
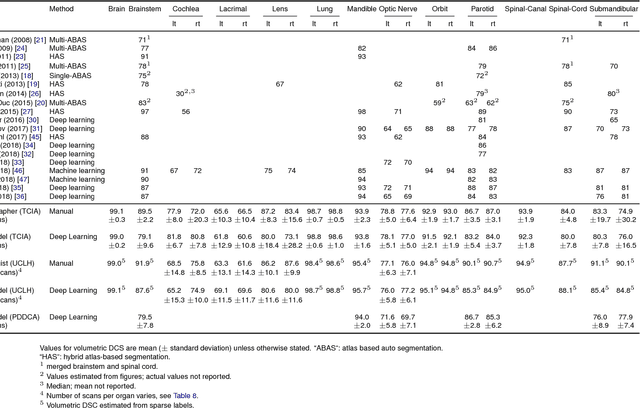
Over half a million individuals are diagnosed with head and neck cancer each year worldwide. Radiotherapy is an important curative treatment for this disease, but it requires manually intensive delineation of radiosensitive organs at risk (OARs). This planning process can delay treatment commencement. While auto-segmentation algorithms offer a potentially time-saving solution, the challenges in defining, quantifying and achieving expert performance remain. Adopting a deep learning approach, we demonstrate a 3D U-Net architecture that achieves performance similar to experts in delineating a wide range of head and neck OARs. The model was trained on a dataset of 663 deidentified computed tomography (CT) scans acquired in routine clinical practice and segmented according to consensus OAR definitions. We demonstrate its generalisability through application to an independent test set of 24 CT scans available from The Cancer Imaging Archive collected at multiple international sites previously unseen to the model, each segmented by two independent experts and consisting of 21 OARs commonly segmented in clinical practice. With appropriate validation studies and regulatory approvals, this system could improve the effectiveness of radiotherapy pathways.
Exploiting Cyclic Symmetry in Convolutional Neural Networks
May 26, 2016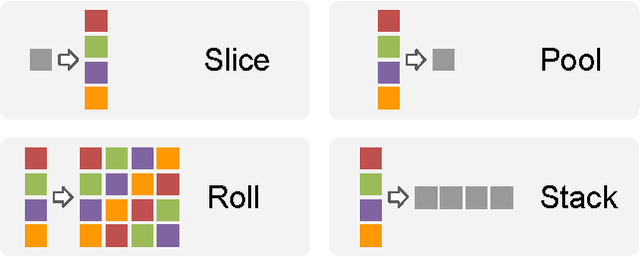

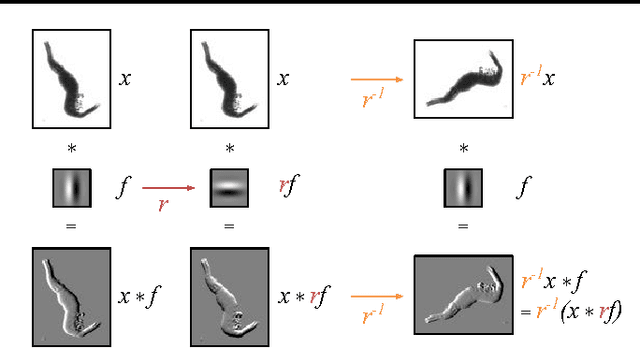
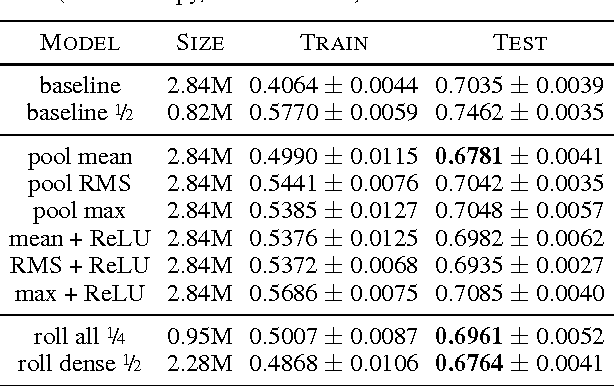
Many classes of images exhibit rotational symmetry. Convolutional neural networks are sometimes trained using data augmentation to exploit this, but they are still required to learn the rotation equivariance properties from the data. Encoding these properties into the network architecture, as we are already used to doing for translation equivariance by using convolutional layers, could result in a more efficient use of the parameter budget by relieving the model from learning them. We introduce four operations which can be inserted into neural network models as layers, and which can be combined to make these models partially equivariant to rotations. They also enable parameter sharing across different orientations. We evaluate the effect of these architectural modifications on three datasets which exhibit rotational symmetry and demonstrate improved performance with smaller models.