 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
TacticAI: an AI assistant for football tactics
Oct 17, 2023Identifying key patterns of tactics implemented by rival teams, and developing effective responses, lies at the heart of modern football. However, doing so algorithmically remains an open research challenge. To address this unmet need, we propose TacticAI, an AI football tactics assistant developed and evaluated in close collaboration with domain experts from Liverpool FC. We focus on analysing corner kicks, as they offer coaches the most direct opportunities for interventions and improvements. TacticAI incorporates both a predictive and a generative component, allowing the coaches to effectively sample and explore alternative player setups for each corner kick routine and to select those with the highest predicted likelihood of success. We validate TacticAI on a number of relevant benchmark tasks: predicting receivers and shot attempts and recommending player position adjustments. The utility of TacticAI is validated by a qualitative study conducted with football domain experts at Liverpool FC. We show that TacticAI's model suggestions are not only indistinguishable from real tactics, but also favoured over existing tactics 90% of the time, and that TacticAI offers an effective corner kick retrieval system. TacticAI achieves these results despite the limited availability of gold-standard data, achieving data efficiency through geometric deep learning.
Zorro: the masked multimodal transformer
Jan 23, 2023



Attention-based models are appealing for multimodal processing because inputs from multiple modalities can be concatenated and fed to a single backbone network - thus requiring very little fusion engineering. The resulting representations are however fully entangled throughout the network, which may not always be desirable: in learning, contrastive audio-visual self-supervised learning requires independent audio and visual features to operate, otherwise learning collapses; in inference, evaluation of audio-visual models should be possible on benchmarks having just audio or just video. In this paper, we introduce Zorro, a technique that uses masks to control how inputs from each modality are routed inside Transformers, keeping some parts of the representation modality-pure. We apply this technique to three popular transformer-based architectures (ViT, Swin and HiP) and show that with contrastive pre-training Zorro achieves state-of-the-art results on most relevant benchmarks for multimodal tasks (AudioSet and VGGSound). Furthermore, the resulting models are able to perform unimodal inference on both video and audio benchmarks such as Kinetics-400 or ESC-50.
TAP-Vid: A Benchmark for Tracking Any Point in a Video
Nov 07, 2022Generic motion understanding from video involves not only tracking objects, but also perceiving how their surfaces deform and move. This information is useful to make inferences about 3D shape, physical properties and object interactions. While the problem of tracking arbitrary physical points on surfaces over longer video clips has received some attention, no dataset or benchmark for evaluation existed, until now. In this paper, we first formalize the problem, naming it tracking any point (TAP). We introduce a companion benchmark, TAP-Vid, which is composed of both real-world videos with accurate human annotations of point tracks, and synthetic videos with perfect ground-truth point tracks. Central to the construction of our benchmark is a novel semi-automatic crowdsourced pipeline which uses optical flow estimates to compensate for easier, short-term motion like camera shake, allowing annotators to focus on harder sections of video. We validate our pipeline on synthetic data and propose a simple end-to-end point tracking model TAP-Net, showing that it outperforms all prior methods on our benchmark when trained on synthetic data.
Broaden Your Views for Self-Supervised Video Learning
Mar 30, 2021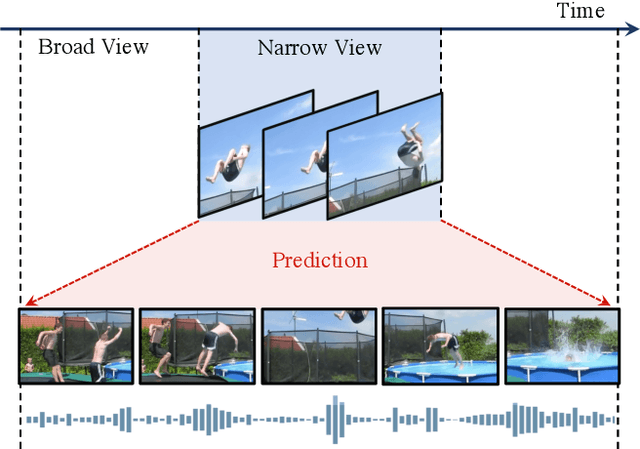
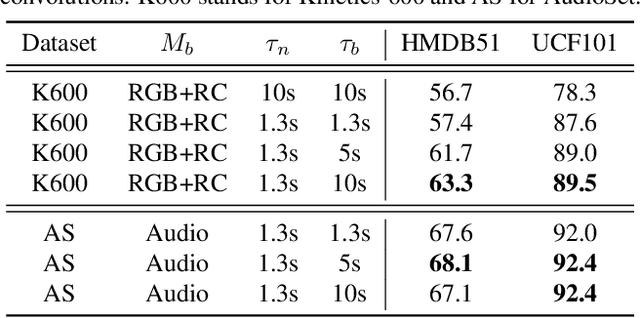
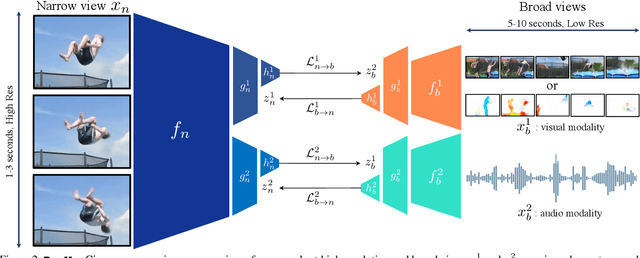
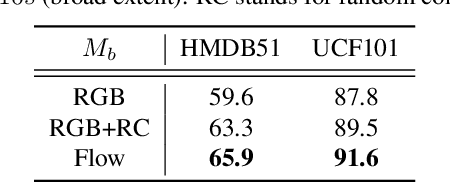
Most successful self-supervised learning methods are trained to align the representations of two independent views from the data. State-of-the-art methods in video are inspired by image techniques, where these two views are similarly extracted by cropping and augmenting the resulting crop. However, these methods miss a crucial element in the video domain: time. We introduce BraVe, a self-supervised learning framework for video. In BraVe, one of the views has access to a narrow temporal window of the video while the other view has a broad access to the video content. Our models learn to generalise from the narrow view to the general content of the video. Furthermore, BraVe processes the views with different backbones, enabling the use of alternative augmentations or modalities into the broad view such as optical flow, randomly convolved RGB frames, audio or their combinations. We demonstrate that BraVe achieves state-of-the-art results in self-supervised representation learning on standard video and audio classification benchmarks including UCF101, HMDB51, Kinetics, ESC-50 and AudioSet.
Self-Supervised MultiModal Versatile Networks
Jun 29, 2020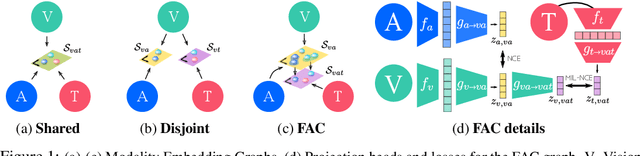
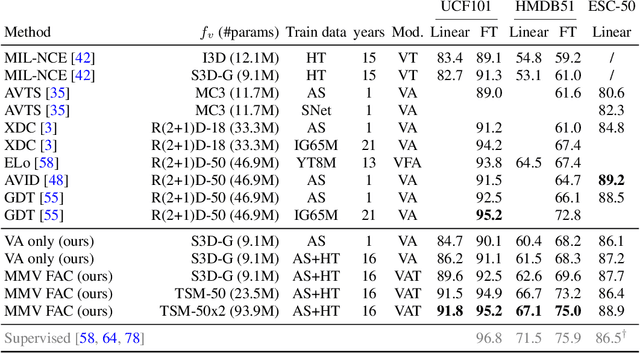
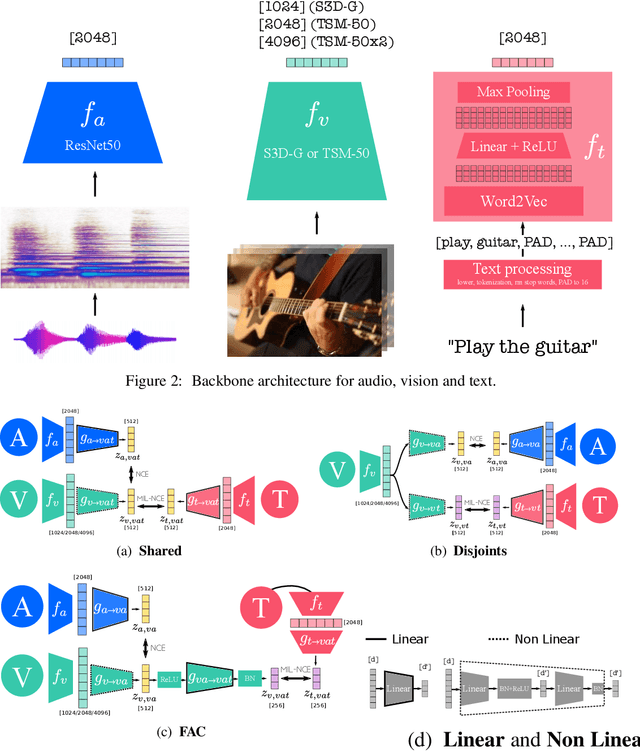
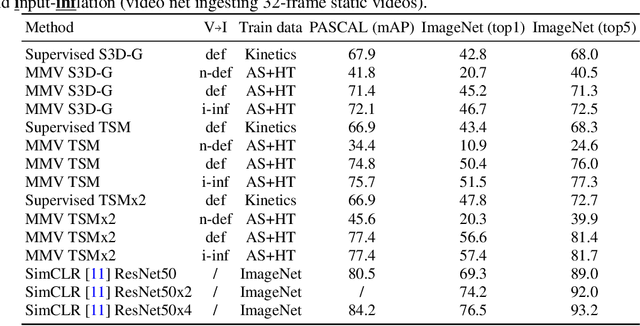
Videos are a rich source of multi-modal supervision. In this work, we learn representations using self-supervision by leveraging three modalities naturally present in videos: vision, audio and language. To this end, we introduce the notion of a multimodal versatile network -- a network that can ingest multiple modalities and whose representations enable downstream tasks in multiple modalities. In particular, we explore how best to combine the modalities, such that fine-grained representations of audio and vision can be maintained, whilst also integrating text into a common embedding. Driven by versatility, we also introduce a novel process of deflation, so that the networks can be effortlessly applied to the visual data in the form of video or a static image. We demonstrate how such networks trained on large collections of unlabelled video data can be applied on video, video-text, image and audio tasks. Equipped with these representations, we obtain state-of-the-art performance on multiple challenging benchmarks including UCF101, HMDB51 and ESC-50 when compared to previous self-supervised work.
Learning to Zoom: a Saliency-Based Sampling Layer for Neural Networks
Sep 10, 2018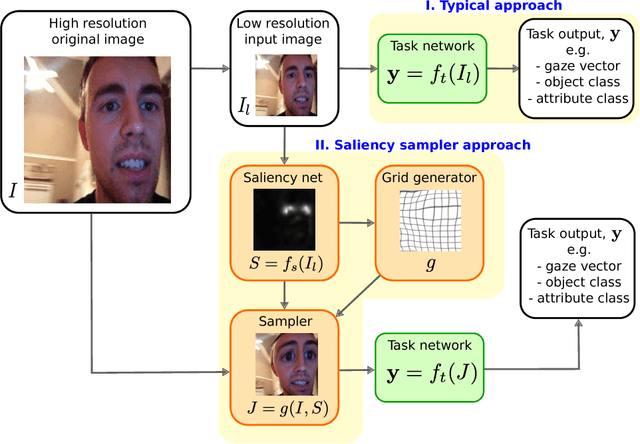
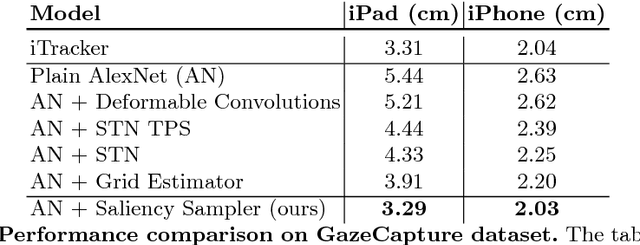

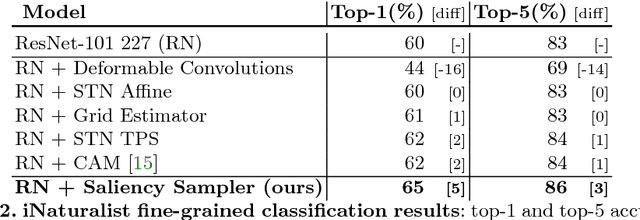
We introduce a saliency-based distortion layer for convolutional neural networks that helps to improve the spatial sampling of input data for a given task. Our differentiable layer can be added as a preprocessing block to existing task networks and trained altogether in an end-to-end fashion. The effect of the layer is to efficiently estimate how to sample from the original data in order to boost task performance. For example, for an image classification task in which the original data might range in size up to several megapixels, but where the desired input images to the task network are much smaller, our layer learns how best to sample from the underlying high resolution data in a manner which preserves task-relevant information better than uniform downsampling. This has the effect of creating distorted, caricature-like intermediate images, in which idiosyncratic elements of the image that improve task performance are zoomed and exaggerated. Unlike alternative approaches such as spatial transformer networks, our proposed layer is inspired by image saliency, computed efficiently from uniformly downsampled data, and degrades gracefully to a uniform sampling strategy under uncertainty. We apply our layer to improve existing networks for the tasks of human gaze estimation and fine-grained object classification. Code for our method is available in: http://github.com/recasens/Saliency-Sampler
Synthetically Trained Icon Proposals for Parsing and Summarizing Infographics
Jul 27, 2018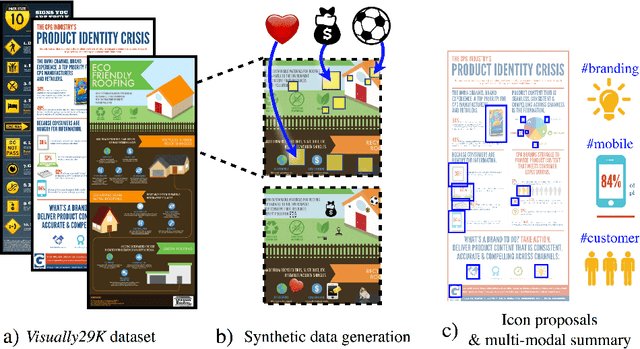
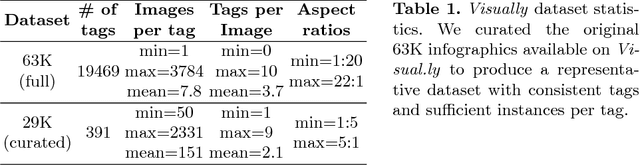

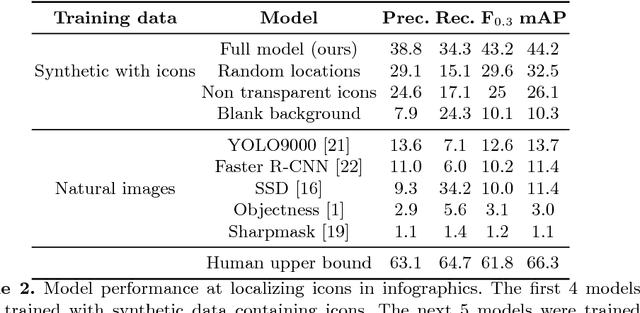
Widely used in news, business, and educational media, infographics are handcrafted to effectively communicate messages about complex and often abstract topics including `ways to conserve the environment' and `understanding the financial crisis'. Composed of stylistically and semantically diverse visual and textual elements, infographics pose new challenges for computer vision. While automatic text extraction works well on infographics, computer vision approaches trained on natural images fail to identify the stand-alone visual elements in infographics, or `icons'. To bridge this representation gap, we propose a synthetic data generation strategy: we augment background patches in infographics from our Visually29K dataset with Internet-scraped icons which we use as training data for an icon proposal mechanism. On a test set of 1K annotated infographics, icons are located with 38% precision and 34% recall (the best model trained with natural images achieves 14% precision and 7% recall). Combining our icon proposals with icon classification and text extraction, we present a multi-modal summarization application. Our application takes an infographic as input and automatically produces text tags and visual hashtags that are textually and visually representative of the infographic's topics respectively.
Jointly Discovering Visual Objects and Spoken Words from Raw Sensory Input
Apr 04, 2018
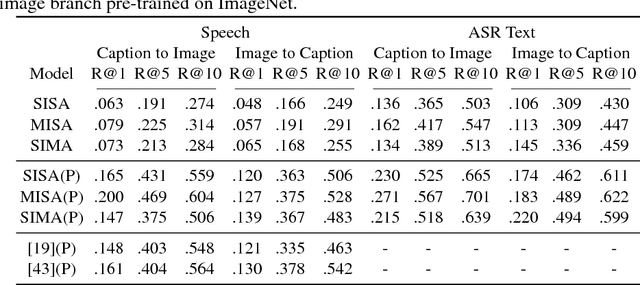
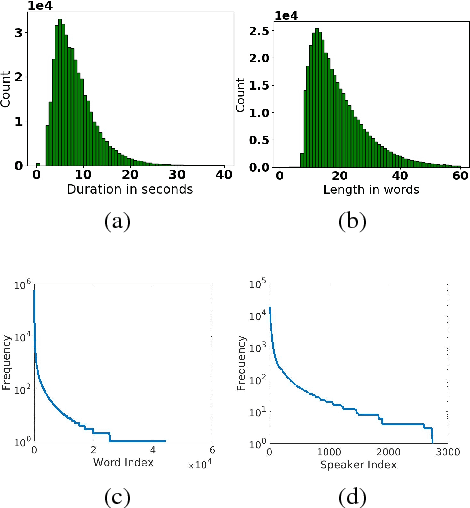
In this paper, we explore neural network models that learn to associate segments of spoken audio captions with the semantically relevant portions of natural images that they refer to. We demonstrate that these audio-visual associative localizations emerge from network-internal representations learned as a by-product of training to perform an image-audio retrieval task. Our models operate directly on the image pixels and speech waveform, and do not rely on any conventional supervision in the form of labels, segmentations, or alignments between the modalities during training. We perform analysis using the Places 205 and ADE20k datasets demonstrating that our models implicitly learn semantically-coupled object and word detectors.