 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Audio to Semantics: Approaches to end-to-end spoken language understanding
Sep 24, 2018
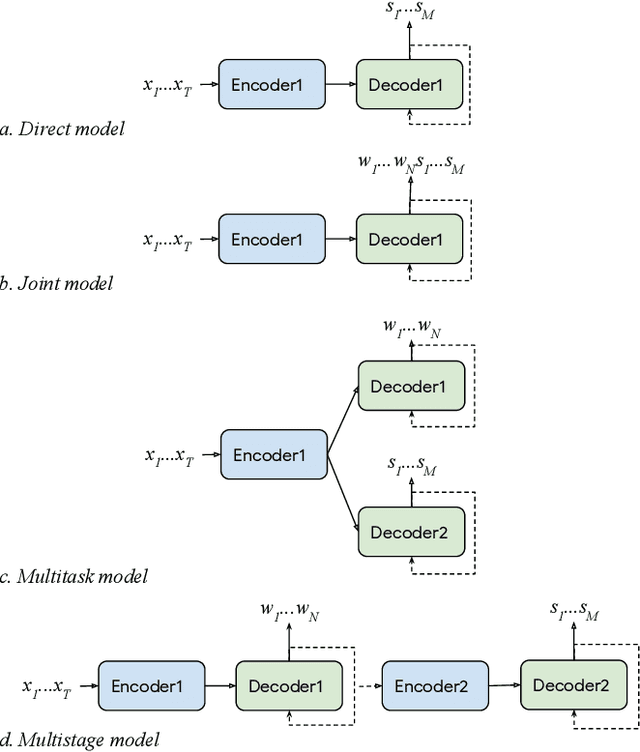
Conventional spoken language understanding systems consist of two main components: an automatic speech recognition module that converts audio to a transcript, and a natural language understanding module that transforms the resulting text (or top N hypotheses) into a set of domains, intents, and arguments. These modules are typically optimized independently. In this paper, we formulate audio to semantic understanding as a sequence-to-sequence problem [1]. We propose and compare various encoder-decoder based approaches that optimize both modules jointly, in an end-to-end manner. Evaluations on a real-world task show that 1) having an intermediate text representation is crucial for the quality of the predicted semantics, especially the intent arguments and 2) jointly optimizing the full system improves overall accuracy of prediction. Compared to independently trained models, our best jointly trained model achieves similar domain and intent prediction F1 scores, but improves argument word error rate by 18% relative.
Vision as an Interlingua: Learning Multilingual Semantic Embeddings of Untranscribed Speech
Apr 09, 2018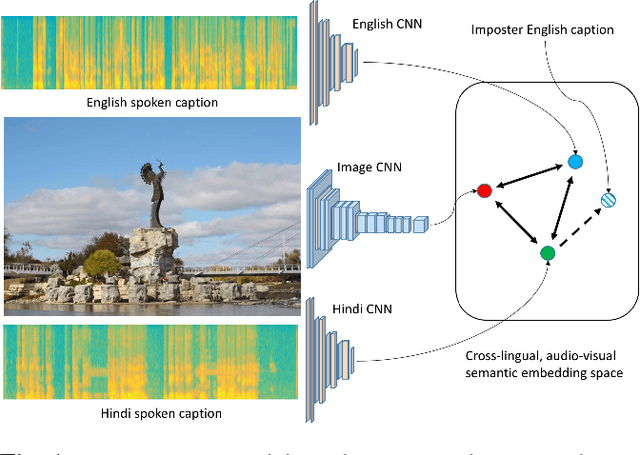

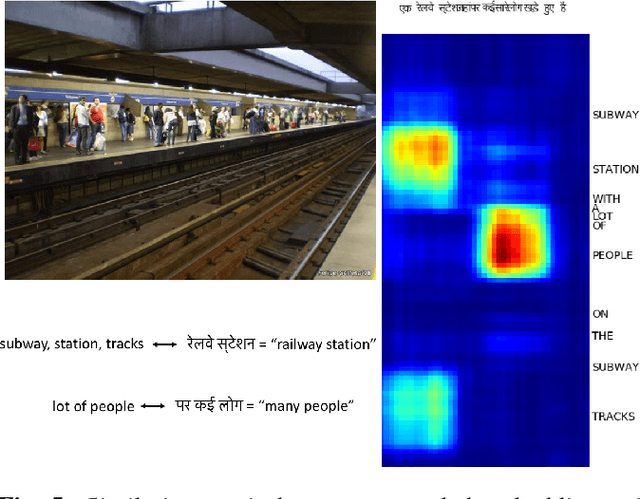
In this paper, we explore the learning of neural network embeddings for natural images and speech waveforms describing the content of those images. These embeddings are learned directly from the waveforms without the use of linguistic transcriptions or conventional speech recognition technology. While prior work has investigated this setting in the monolingual case using English speech data, this work represents the first effort to apply these techniques to languages beyond English. Using spoken captions collected in English and Hindi, we show that the same model architecture can be successfully applied to both languages. Further, we demonstrate that training a multilingual model simultaneously on both languages offers improved performance over the monolingual models. Finally, we show that these models are capable of performing semantic cross-lingual speech-to-speech retrieval.
Jointly Discovering Visual Objects and Spoken Words from Raw Sensory Input
Apr 04, 2018
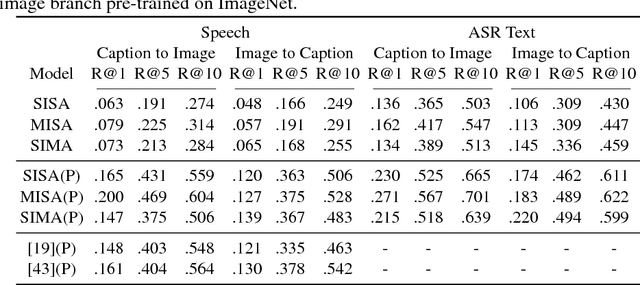
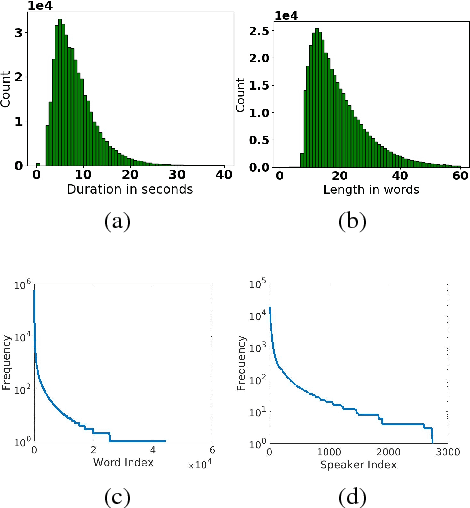
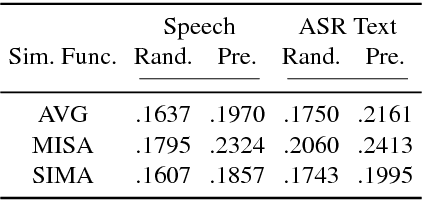
In this paper, we explore neural network models that learn to associate segments of spoken audio captions with the semantically relevant portions of natural images that they refer to. We demonstrate that these audio-visual associative localizations emerge from network-internal representations learned as a by-product of training to perform an image-audio retrieval task. Our models operate directly on the image pixels and speech waveform, and do not rely on any conventional supervision in the form of labels, segmentations, or alignments between the modalities during training. We perform analysis using the Places 205 and ADE20k datasets demonstrating that our models implicitly learn semantically-coupled object and word detectors.