 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedAutoCorrect: Image-Conditioned Autocorrection in Medical Reporting
Dec 04, 2024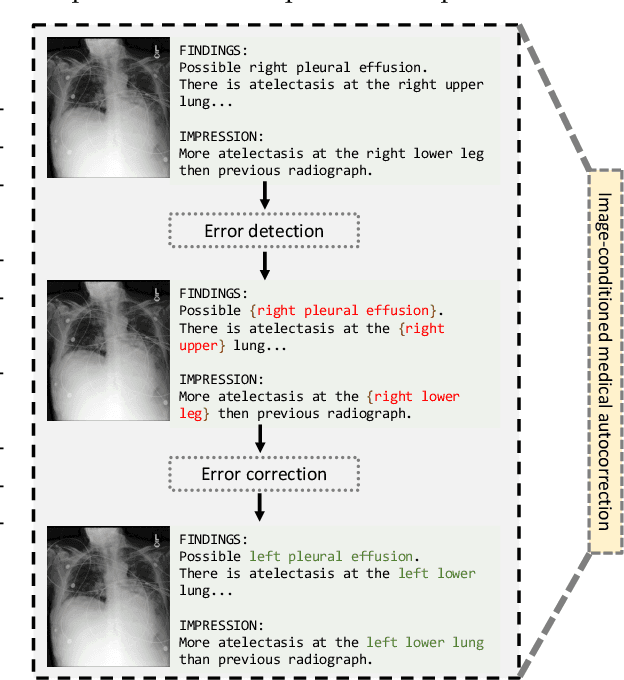
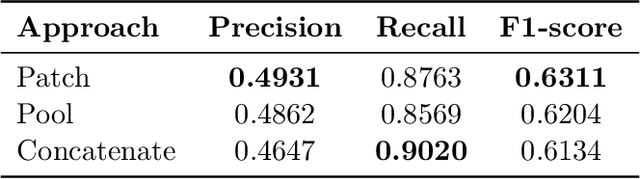
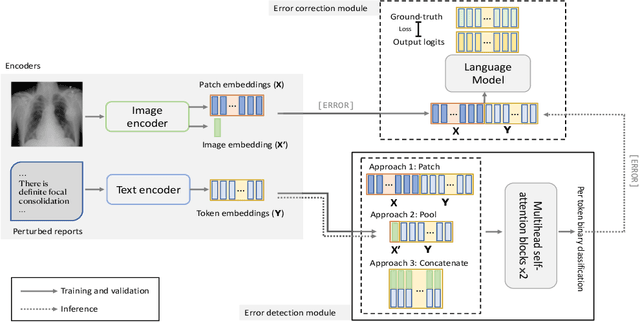

In medical reporting, the accuracy of radiological reports, whether generated by humans or machine learning algorithms, is critical. We tackle a new task in this paper: image-conditioned autocorrection of inaccuracies within these reports. Using the MIMIC-CXR dataset, we first intentionally introduce a diverse range of errors into reports. Subsequently, we propose a two-stage framework capable of pinpointing these errors and then making corrections, simulating an \textit{autocorrection} process. This method aims to address the shortcomings of existing automated medical reporting systems, like factual errors and incorrect conclusions, enhancing report reliability in vital healthcare applications. Importantly, our approach could serve as a guardrail, ensuring the accuracy and trustworthiness of automated report generation. Experiments on established datasets and state of the art report generation models validate this method's potential in correcting medical reporting errors.
pix2gestalt: Amodal Segmentation by Synthesizing Wholes
Jan 25, 2024



We introduce pix2gestalt, a framework for zero-shot amodal segmentation, which learns to estimate the shape and appearance of whole objects that are only partially visible behind occlusions. By capitalizing on large-scale diffusion models and transferring their representations to this task, we learn a conditional diffusion model for reconstructing whole objects in challenging zero-shot cases, including examples that break natural and physical priors, such as art. As training data, we use a synthetically curated dataset containing occluded objects paired with their whole counterparts. Experiments show that our approach outperforms supervised baselines on established benchmarks. Our model can furthermore be used to significantly improve the performance of existing object recognition and 3D reconstruction methods in the presence of occlusions.
ViperGPT: Visual Inference via Python Execution for Reasoning
Mar 14, 2023
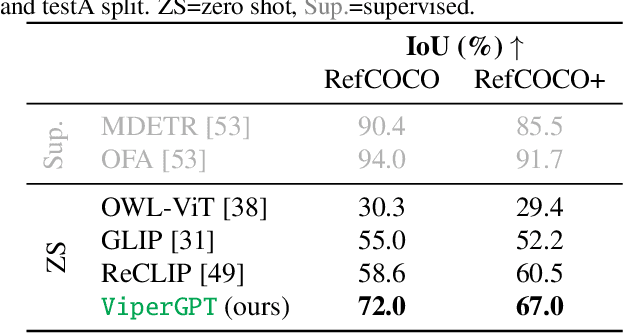
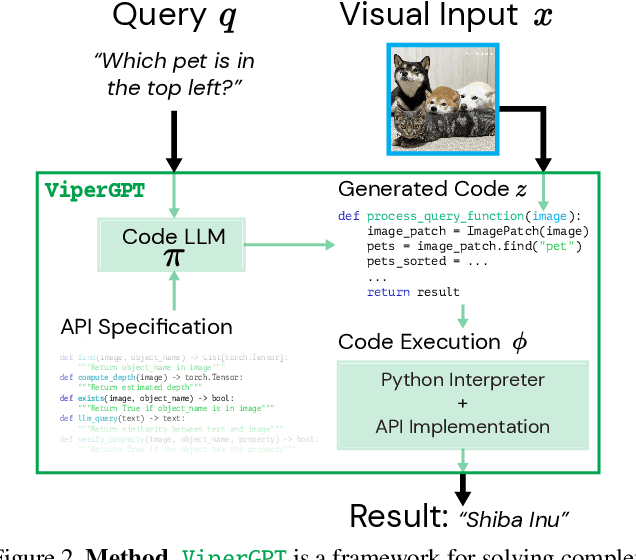

Answering visual queries is a complex task that requires both visual processing and reasoning. End-to-end models, the dominant approach for this task, do not explicitly differentiate between the two, limiting interpretability and generalization. Learning modular programs presents a promising alternative, but has proven challenging due to the difficulty of learning both the programs and modules simultaneously. We introduce ViperGPT, a framework that leverages code-generation models to compose vision-and-language models into subroutines to produce a result for any query. ViperGPT utilizes a provided API to access the available modules, and composes them by generating Python code that is later executed. This simple approach requires no further training, and achieves state-of-the-art results across various complex visual tasks.
FLEX: Full-Body Grasping Without Full-Body Grasps
Nov 21, 2022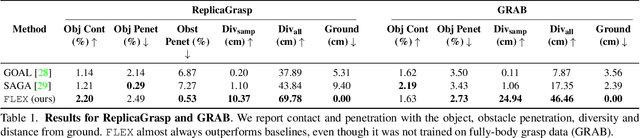
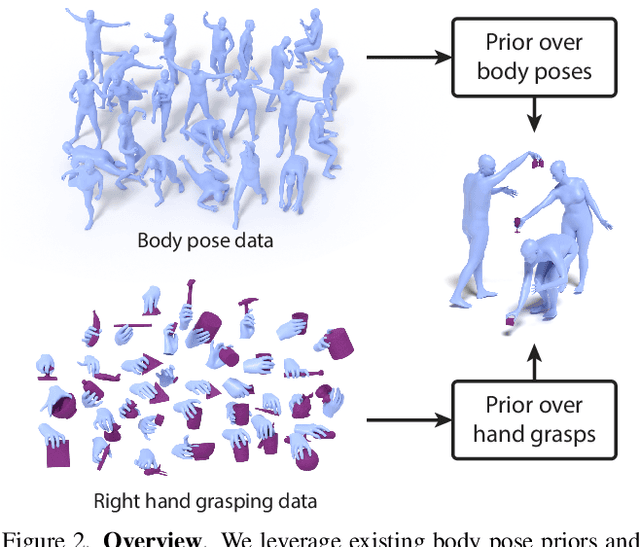
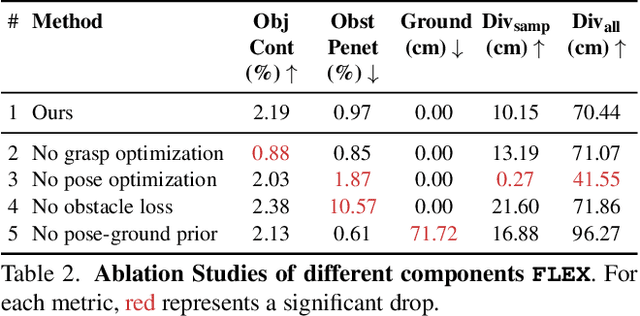
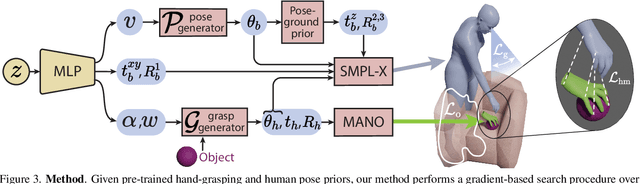
Synthesizing 3D human avatars interacting realistically with a scene is an important problem with applications in AR/VR, video games and robotics. Towards this goal, we address the task of generating a virtual human -- hands and full body -- grasping everyday objects. Existing methods approach this problem by collecting a 3D dataset of humans interacting with objects and training on this data. However, 1) these methods do not generalize to different object positions and orientations, or to the presence of furniture in the scene, and 2) the diversity of their generated full-body poses is very limited. In this work, we address all the above challenges to generate realistic, diverse full-body grasps in everyday scenes without requiring any 3D full-body grasping data. Our key insight is to leverage the existence of both full-body pose and hand grasping priors, composing them using 3D geometrical constraints to obtain full-body grasps. We empirically validate that these constraints can generate a variety of feasible human grasps that are superior to baselines both quantitatively and qualitatively. See our webpage for more details: https://flex.cs.columbia.edu/.
Representing Spatial Trajectories as Distributions
Oct 04, 2022
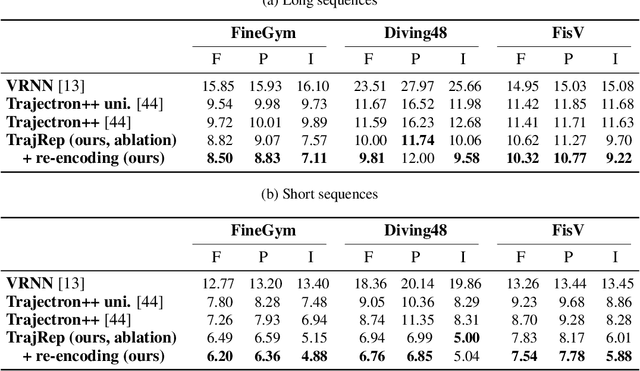
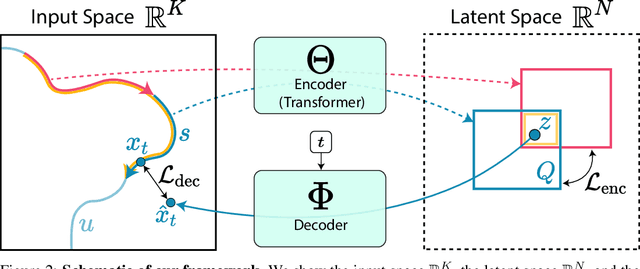
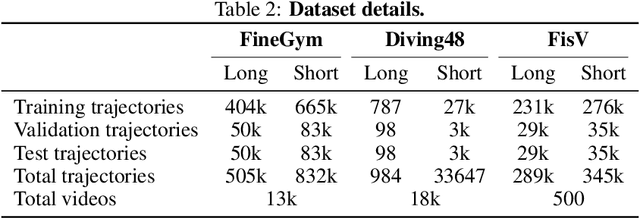
We introduce a representation learning framework for spatial trajectories. We represent partial observations of trajectories as probability distributions in a learned latent space, which characterize the uncertainty about unobserved parts of the trajectory. Our framework allows us to obtain samples from a trajectory for any continuous point in time, both interpolating and extrapolating. Our flexible approach supports directly modifying specific attributes of a trajectory, such as its pace, as well as combining different partial observations into single representations. Experiments show our method's advantage over baselines in prediction tasks.
Learning the Predictability of the Future
Jan 01, 2021
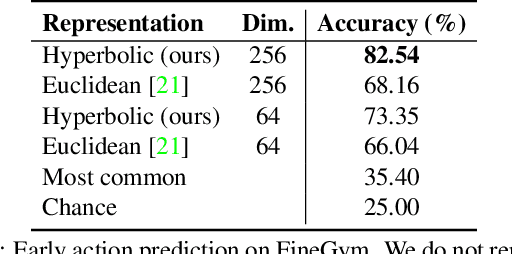
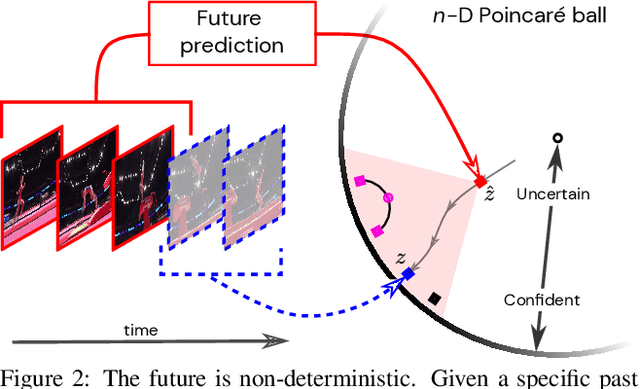
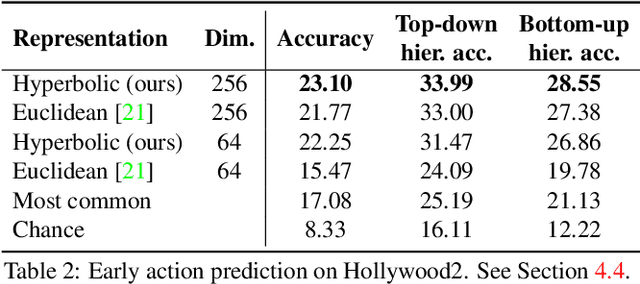
We introduce a framework for learning from unlabeled video what is predictable in the future. Instead of committing up front to features to predict, our approach learns from data which features are predictable. Based on the observation that hyperbolic geometry naturally and compactly encodes hierarchical structure, we propose a predictive model in hyperbolic space. When the model is most confident, it will predict at a concrete level of the hierarchy, but when the model is not confident, it learns to automatically select a higher level of abstraction. Experiments on two established datasets show the key role of hierarchical representations for action prediction. Although our representation is trained with unlabeled video, visualizations show that action hierarchies emerge in the representation.
Globetrotter: Unsupervised Multilingual Translation from Visual Alignment
Dec 08, 2020

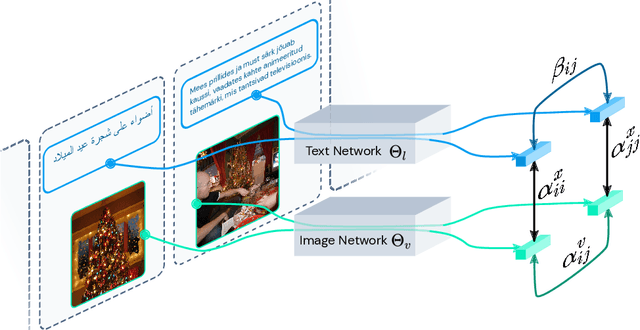

Multi-language machine translation without parallel corpora is challenging because there is no explicit supervision between languages. Existing unsupervised methods typically rely on topological properties of the language representations. We introduce a framework that instead uses the visual modality to align multiple languages, using images as the bridge between them. We estimate the cross-modal alignment between language and images, and use this estimate to guide the learning of cross-lingual representations. Our language representations are trained jointly in one model with a single stage. Experiments with fifty-two languages show that our method outperforms baselines on unsupervised word-level and sentence-level translation using retrieval.
Learning to Learn Words from Narrated Video
Nov 25, 2019
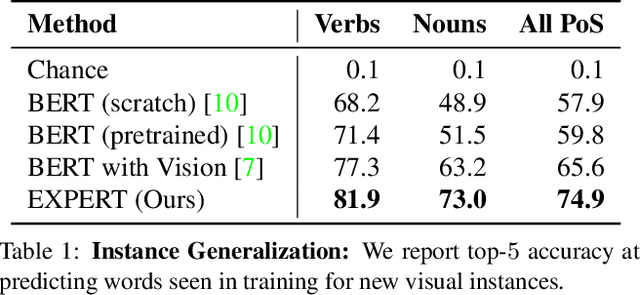

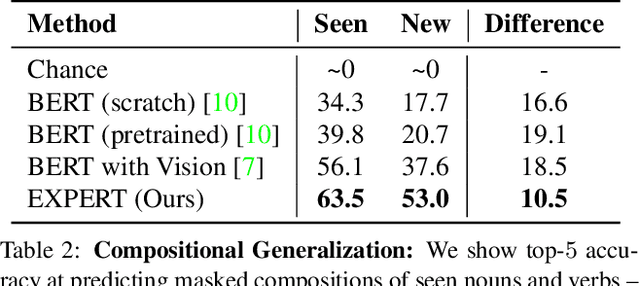
When we travel, we often encounter new scenarios we have never experienced before, with new sights and new words that describe them. We can use our language-learning ability to quickly learn these new words and correlate them with the visual world. In contrast, language models often do not robustly generalize to novel words and compositions. We propose a framework that learns how to learn text representations from visual context. Experiments show that our approach significantly outperforms the state-of-the-art in visual language modeling for acquiring new words and predicting new compositions. Model ablations and visualizations suggest that the visual modality helps our approach more robustly generalize at these tasks. Project webpage is available at https://expert.cs.columbia.edu/
Overcoming catastrophic forgetting with hard attention to the task
May 29, 2018
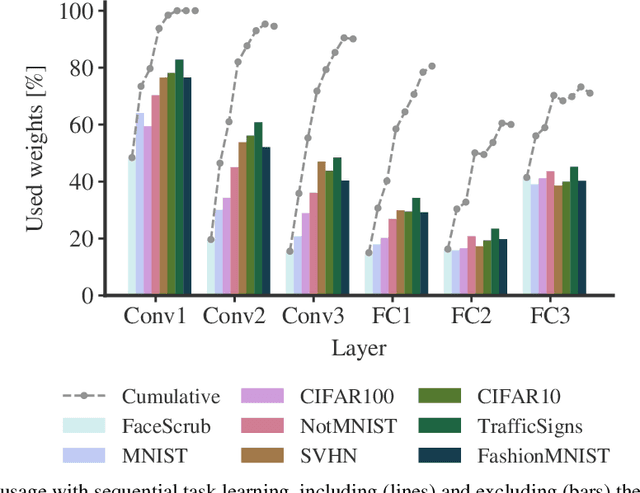
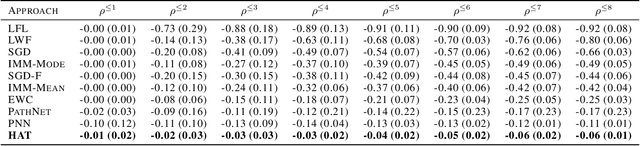
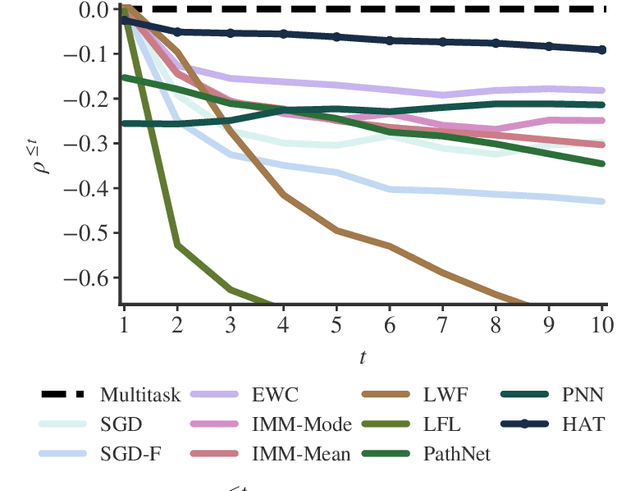
Catastrophic forgetting occurs when a neural network loses the information learned in a previous task after training on subsequent tasks. This problem remains a hurdle for artificial intelligence systems with sequential learning capabilities. In this paper, we propose a task-based hard attention mechanism that preserves previous tasks' information without affecting the current task's learning. A hard attention mask is learned concurrently to every task, through stochastic gradient descent, and previous masks are exploited to condition such learning. We show that the proposed mechanism is effective for reducing catastrophic forgetting, cutting current rates by 45 to 80%. We also show that it is robust to different hyperparameter choices, and that it offers a number of monitoring capabilities. The approach features the possibility to control both the stability and compactness of the learned knowledge, which we believe makes it also attractive for online learning or network compression applications.
Jointly Discovering Visual Objects and Spoken Words from Raw Sensory Input
Apr 04, 2018
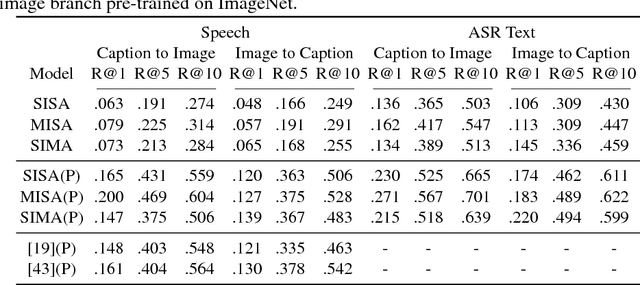
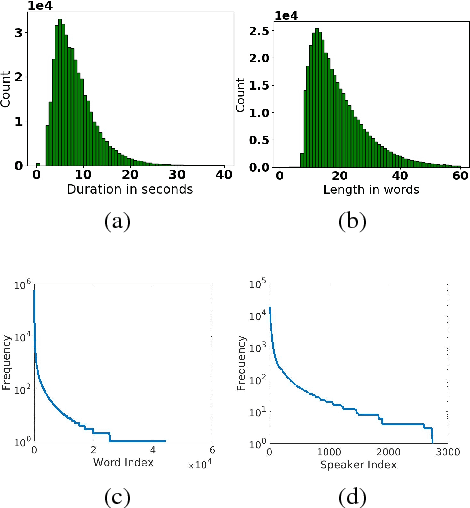
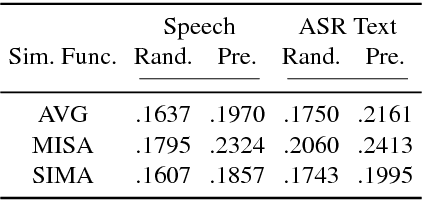
In this paper, we explore neural network models that learn to associate segments of spoken audio captions with the semantically relevant portions of natural images that they refer to. We demonstrate that these audio-visual associative localizations emerge from network-internal representations learned as a by-product of training to perform an image-audio retrieval task. Our models operate directly on the image pixels and speech waveform, and do not rely on any conventional supervision in the form of labels, segmentations, or alignments between the modalities during training. We perform analysis using the Places 205 and ADE20k datasets demonstrating that our models implicitly learn semantically-coupled object and word detectors.