 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOvercoming catastrophic forgetting with hard attention to the task
Paper and Code

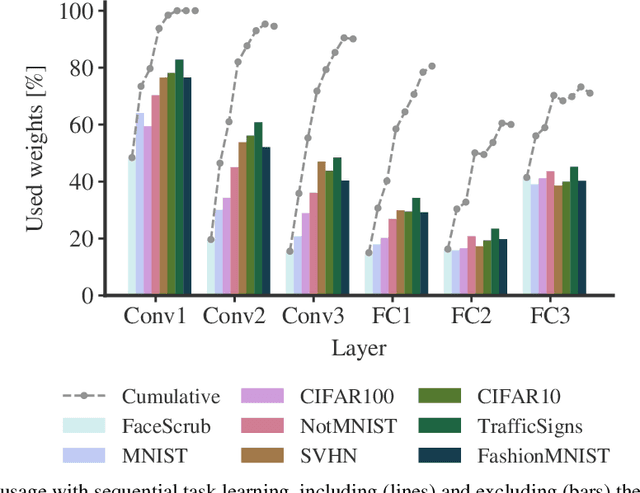
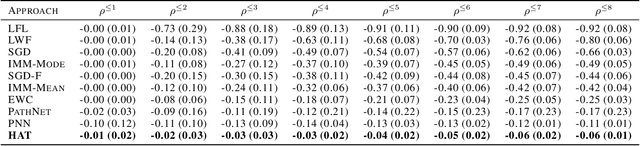
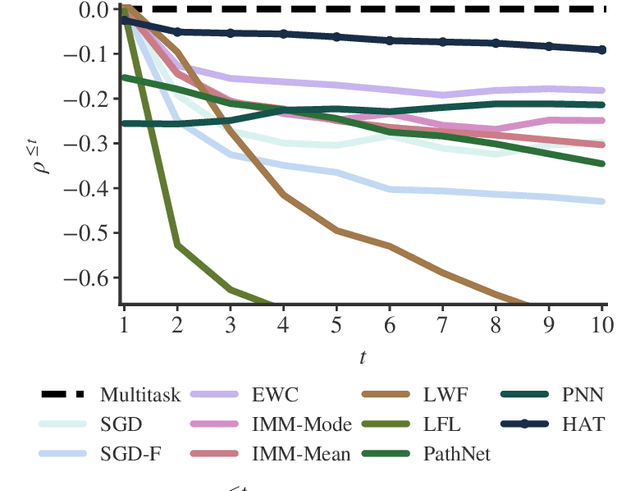
Catastrophic forgetting occurs when a neural network loses the information learned in a previous task after training on subsequent tasks. This problem remains a hurdle for artificial intelligence systems with sequential learning capabilities. In this paper, we propose a task-based hard attention mechanism that preserves previous tasks' information without affecting the current task's learning. A hard attention mask is learned concurrently to every task, through stochastic gradient descent, and previous masks are exploited to condition such learning. We show that the proposed mechanism is effective for reducing catastrophic forgetting, cutting current rates by 45 to 80%. We also show that it is robust to different hyperparameter choices, and that it offers a number of monitoring capabilities. The approach features the possibility to control both the stability and compactness of the learned knowledge, which we believe makes it also attractive for online learning or network compression applications.