 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio-to-Image Bird Species Retrieval without Audio-Image Pairs via Text Distillation
Jan 31, 2026Audio-to-image retrieval offers an interpretable alternative to audio-only classification for bioacoustic species recognition, but learning aligned audio-image representations is challenging due to the scarcity of paired audio-image data. We propose a simple and data-efficient approach that enables audio-to-image retrieval without any audio-image supervision. Our proposed method uses text as a semantic intermediary: we distill the text embedding space of a pretrained image-text model (BioCLIP-2), which encodes rich visual and taxonomic structure, into a pretrained audio-text model (BioLingual) by fine-tuning its audio encoder with a contrastive objective. This distillation transfers visually grounded semantics into the audio representation, inducing emergent alignment between audio and image embeddings without using images during training. We evaluate the resulting model on multiple bioacoustic benchmarks. The distilled audio encoder preserves audio discriminative power while substantially improving audio-text alignment on focal recordings and soundscape datasets. Most importantly, on the SSW60 benchmark, the proposed approach achieves strong audio-to-image retrieval performance exceeding baselines based on zero-shot model combinations or learned mappings between text embeddings, despite not training on paired audio-image data. These results demonstrate that indirect semantic transfer through text is sufficient to induce meaningful audio-image alignment, providing a practical solution for visually grounded species recognition in data-scarce bioacoustic settings.
Compact Hypercube Embeddings for Fast Text-based Wildlife Observation Retrieval
Jan 30, 2026Large-scale biodiversity monitoring platforms increasingly rely on multimodal wildlife observations. While recent foundation models enable rich semantic representations across vision, audio, and language, retrieving relevant observations from massive archives remains challenging due to the computational cost of high-dimensional similarity search. In this work, we introduce compact hypercube embeddings for fast text-based wildlife observation retrieval, a framework that enables efficient text-based search over large-scale wildlife image and audio databases using compact binary representations. Building on the cross-view code alignment hashing framework, we extend lightweight hashing beyond a single-modality setup to align natural language descriptions with visual or acoustic observations in a shared Hamming space. Our approach leverages pretrained wildlife foundation models, including BioCLIP and BioLingual, and adapts them efficiently for hashing using parameter-efficient fine-tuning. We evaluate our method on large-scale benchmarks, including iNaturalist2024 for text-to-image retrieval and iNatSounds2024 for text-to-audio retrieval, as well as multiple soundscape datasets to assess robustness under domain shift. Results show that retrieval using discrete hypercube embeddings achieves competitive, and in several cases superior, performance compared to continuous embeddings, while drastically reducing memory and search cost. Moreover, we observe that the hashing objective consistently improves the underlying encoder representations, leading to stronger retrieval and zero-shot generalization. These results demonstrate that binary, language-based retrieval enables scalable and efficient search over large wildlife archives for biodiversity monitoring systems.
Crossing the Species Divide: Transfer Learning from Speech to Animal Sounds
Sep 04, 2025Self-supervised speech models have demonstrated impressive performance in speech processing, but their effectiveness on non-speech data remains underexplored. We study the transfer learning capabilities of such models on bioacoustic detection and classification tasks. We show that models such as HuBERT, WavLM, and XEUS can generate rich latent representations of animal sounds across taxa. We analyze the models properties with linear probing on time-averaged representations. We then extend the approach to account for the effect of time-wise information with other downstream architectures. Finally, we study the implication of frequency range and noise on performance. Notably, our results are competitive with fine-tuned bioacoustic pre-trained models and show the impact of noise-robust pre-training setups. These findings highlight the potential of speech-based self-supervised learning as an efficient framework for advancing bioacoustic research.
NatureLM-audio: an Audio-Language Foundation Model for Bioacoustics
Nov 11, 2024
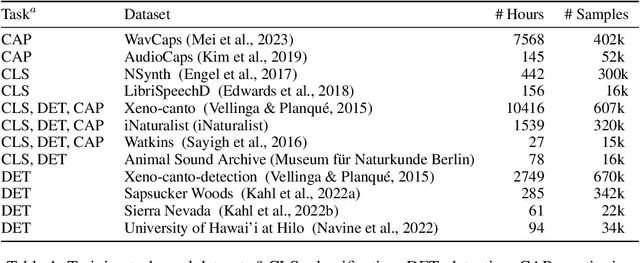

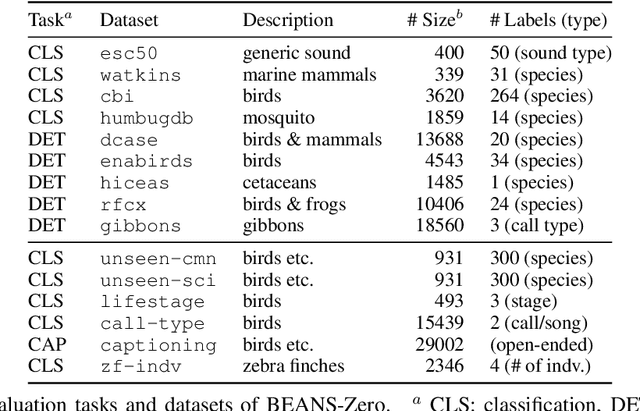
Large language models (LLMs) prompted with text and audio represent the state of the art in various auditory tasks, including speech, music, and general audio, showing emergent abilities on unseen tasks. However, these capabilities have yet to be fully demonstrated in bioacoustics tasks, such as detecting animal vocalizations in large recordings, classifying rare and endangered species, and labeling context and behavior - tasks that are crucial for conservation, biodiversity monitoring, and the study of animal behavior. In this work, we present NatureLM-audio, the first audio-language foundation model specifically designed for bioacoustics. Our carefully curated training dataset comprises text-audio pairs spanning a diverse range of bioacoustics, speech, and music data, designed to address the challenges posed by limited annotated datasets in the field. We demonstrate successful transfer of learned representations from music and speech to bioacoustics, and our model shows promising generalization to unseen taxa and tasks. Importantly, we test NatureLM-audio on a novel benchmark (BEANS-Zero) and it sets the new state of the art (SotA) on several bioacoustics tasks, including zero-shot classification of unseen species. To advance bioacoustics research, we also open-source the code for generating training and benchmark data, as well as for training the model.
Biodenoising: animal vocalization denoising without access to clean data
Oct 04, 2024Animal vocalization denoising is a task similar to human speech enhancement, a well-studied field of research. In contrast to the latter, it is applied to a higher diversity of sound production mechanisms and recording environments, and this higher diversity is a challenge for existing models. Adding to the challenge and in contrast to speech, we lack large and diverse datasets comprising clean vocalizations. As a solution we use as training data pseudo-clean targets, i.e. pre-denoised vocalizations, and segments of background noise without a vocalization. We propose a train set derived from bioacoustics datasets and repositories representing diverse species, acoustic environments, geographic regions. Additionally, we introduce a non-overlapping benchmark set comprising clean vocalizations from different taxa and noise samples. We show that that denoising models (demucs, CleanUNet) trained on pseudo-clean targets obtained with speech enhancement models achieve competitive results on the benchmarking set. We publish data, code, libraries, and demos https://mariusmiron.com/research/biodenoising.
ISPA: Inter-Species Phonetic Alphabet for Transcribing Animal Sounds
Feb 05, 2024Traditionally, bioacoustics has relied on spectrograms and continuous, per-frame audio representations for the analysis of animal sounds, also serving as input to machine learning models. Meanwhile, the International Phonetic Alphabet (IPA) system has provided an interpretable, language-independent method for transcribing human speech sounds. In this paper, we introduce ISPA (Inter-Species Phonetic Alphabet), a precise, concise, and interpretable system designed for transcribing animal sounds into text. We compare acoustics-based and feature-based methods for transcribing and classifying animal sounds, demonstrating their comparable performance with baseline methods utilizing continuous, dense audio representations. By representing animal sounds with text, we effectively treat them as a "foreign language," and we show that established human language ML paradigms and models, such as language models, can be successfully applied to improve performance.
Combining piano performance dimensions for score difficulty classification
Jun 14, 2023



Predicting the difficulty of playing a musical score is essential for structuring and exploring score collections. Despite its importance for music education, the automatic difficulty classification of piano scores is not yet solved, mainly due to the lack of annotated data and the subjectiveness of the annotations. This paper aims to advance the state-of-the-art in score difficulty classification with two major contributions. To address the lack of data, we present Can I Play It? (CIPI) dataset, a machine-readable piano score dataset with difficulty annotations obtained from the renowned classical music publisher Henle Verlag. The dataset is created by matching public domain scores with difficulty labels from Henle Verlag, then reviewed and corrected by an expert pianist. As a second contribution, we explore various input representations from score information to pre-trained ML models for piano fingering and expressiveness inspired by the musicology definition of performance. We show that combining the outputs of multiple classifiers performs better than the classifiers on their own, pointing to the fact that the representations capture different aspects of difficulty. In addition, we conduct numerous experiments that lay a foundation for score difficulty classification and create a basis for future research. Our best-performing model reports a 39.47% balanced accuracy and 1.13 median square error across the nine difficulty levels proposed in this study. Code, dataset, and models are made available for reproducibility.
Music Rearrangement Using Hierarchical Segmentation
May 12, 2023
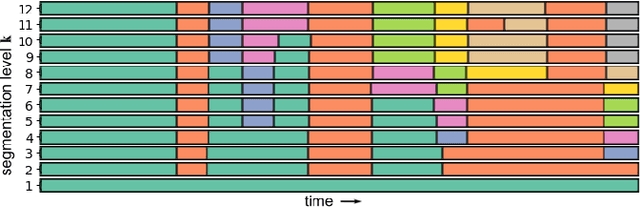
Music rearrangement involves reshuffling, deleting, and repeating sections of a music piece with the goal of producing a standalone version that has a different duration. It is a creative and time-consuming task commonly performed by an expert music engineer. In this paper, we propose a method for automatically rearranging music recordings that takes into account the hierarchical structure of the recording. Previous approaches focus solely on identifying cut-points in the audio that could result in smooth transitions. We instead utilize deep audio representations to hierarchically segment the piece and define a cut-point search subject to the boundaries and musical functions of the segments. We score suitable entry- and exit-point pairs based on their similarity and the segments they belong to, and define an optimal path search. Experimental results demonstrate the selected cut-points are most commonly imperceptible by listeners and result in more consistent musical development with less distracting repetitions.
PodcastMix: A dataset for separating music and speech in podcasts
Jul 15, 2022


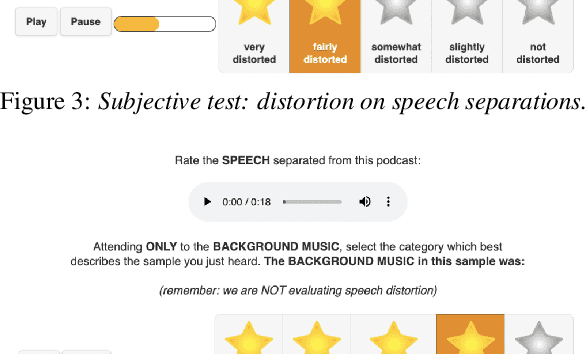
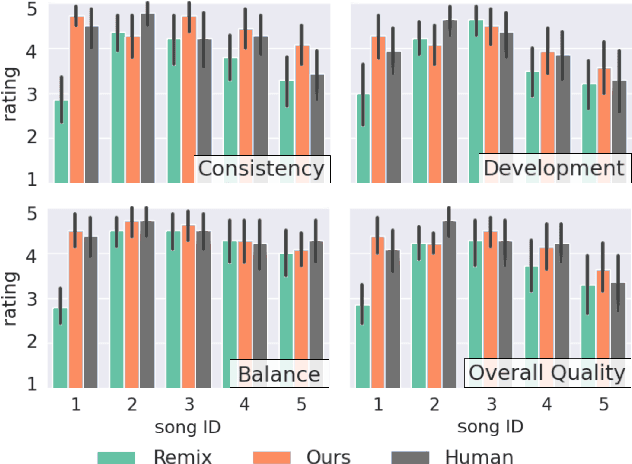
We introduce PodcastMix, a dataset formalizing the task of separating background music and foreground speech in podcasts. We aim at defining a benchmark suitable for training and evaluating (deep learning) source separation models. To that end, we release a large and diverse training dataset based on programatically generated podcasts. However, current (deep learning) models can incur into generalization issues, specially when trained on synthetic data. To target potential generalization issues, we release an evaluation set based on real podcasts for which we design objective and subjective tests. Out of our experiments with real podcasts, we find that current (deep learning) models may have generalization issues. Yet, these can perform competently, e.g., our best baseline separates speech with a mean opinion score of 3.84 (rating "overall separation quality" from 1 to 5). The dataset and baselines are accessible online.
Score difficulty analysis for piano performance education based on fingering
Mar 24, 2022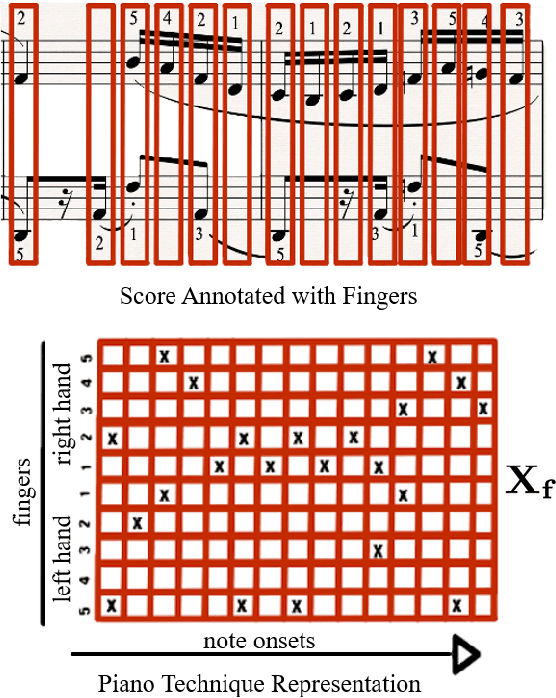

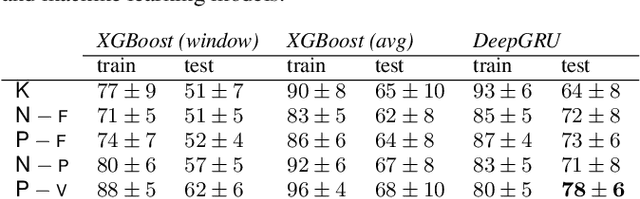
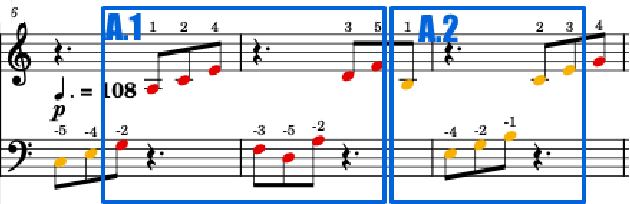
In this paper, we introduce score difficulty classification as a sub-task of music information retrieval (MIR), which may be used in music education technologies, for personalised curriculum generation, and score retrieval. We introduce a novel dataset for our task, Mikrokosmos-difficulty, containing 147 piano pieces in symbolic representation and the corresponding difficulty labels derived by its composer B\'ela Bart\'ok and the publishers. As part of our methodology, we propose piano technique feature representations based on different piano fingering algorithms. We use these features as input for two classifiers: a Gated Recurrent Unit neural network (GRU) with attention mechanism and gradient-boosted trees trained on score segments. We show that for our dataset fingering based features perform better than a simple baseline considering solely the notes in the score. Furthermore, the GRU with attention mechanism classifier surpasses the gradient-boosted trees. Our proposed models are interpretable and are capable of generating difficulty feedback both locally, on short term segments, and globally, for whole pieces. Code, datasets, models, and an online demo are made available for reproducibility