 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing Algorithmic Biases for Musical Version Identification
Paper and Code
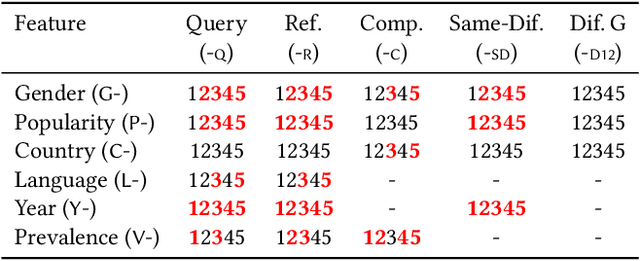
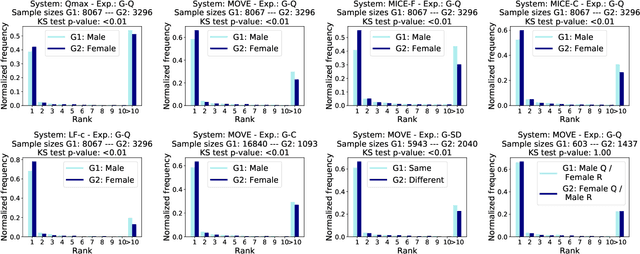
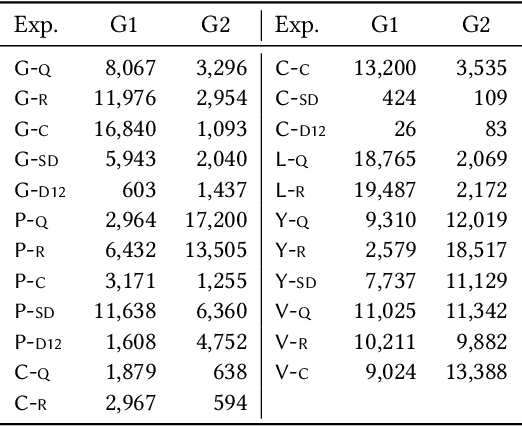
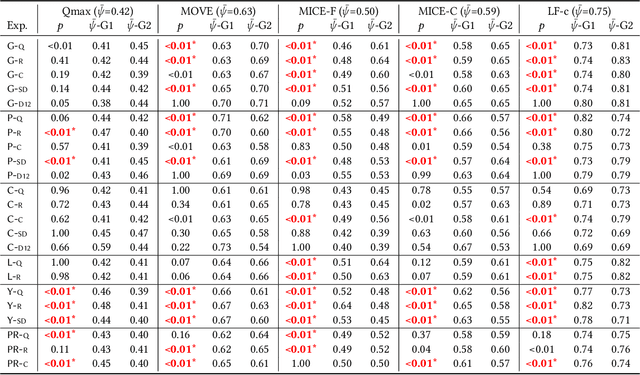
Version identification (VI) systems now offer accurate and scalable solutions for detecting different renditions of a musical composition, allowing the use of these systems in industrial applications and throughout the wider music ecosystem. Such use can have an important impact on various stakeholders regarding recognition and financial benefits, including how royalties are circulated for digital rights management. In this work, we take a step toward acknowledging this impact and consider VI systems as socio-technical systems rather than isolated technologies. We propose a framework for quantifying performance disparities across 5 systems and 6 relevant side attributes: gender, popularity, country, language, year, and prevalence. We also consider 3 main stakeholders for this particular information retrieval use case: the performing artists of query tracks, those of reference (original) tracks, and the composers. By categorizing the recordings in our dataset using such attributes and stakeholders, we analyze whether the considered VI systems show any implicit biases. We find signs of disparities in identification performance for most of the groups we include in our analyses. Moreover, we also find that learning- and rule-based systems behave differently for some attributes, which suggests an additional dimension to consider along with accuracy and scalability when evaluating VI systems. Lastly, we share our dataset with attribute annotations to encourage VI researchers to take these aspects into account while building new systems.