 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStemGen: A music generation model that listens
Dec 14, 2023

End-to-end generation of musical audio using deep learning techniques has seen an explosion of activity recently. However, most models concentrate on generating fully mixed music in response to abstract conditioning information. In this work, we present an alternative paradigm for producing music generation models that can listen and respond to musical context. We describe how such a model can be constructed using a non-autoregressive, transformer-based model architecture and present a number of novel architectural and sampling improvements. We train the described architecture on both an open-source and a proprietary dataset. We evaluate the produced models using standard quality metrics and a new approach based on music information retrieval descriptors. The resulting model reaches the audio quality of state-of-the-art text-conditioned models, as well as exhibiting strong musical coherence with its context.
Assessing Algorithmic Biases for Musical Version Identification
Sep 30, 2021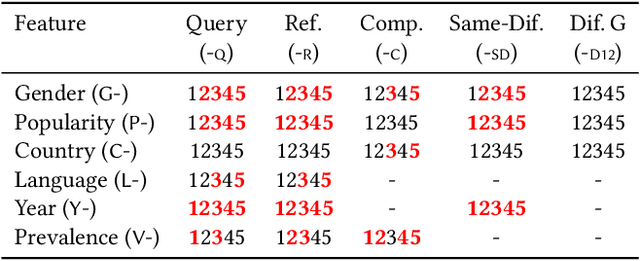
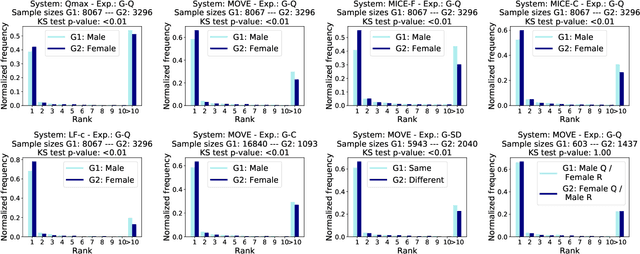
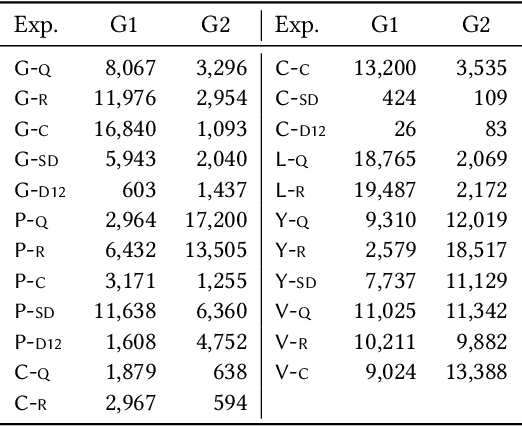
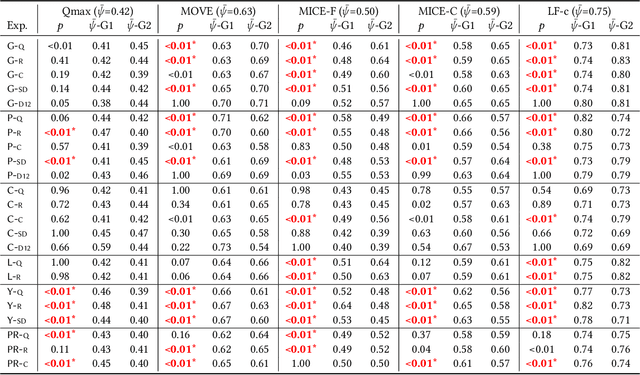
Version identification (VI) systems now offer accurate and scalable solutions for detecting different renditions of a musical composition, allowing the use of these systems in industrial applications and throughout the wider music ecosystem. Such use can have an important impact on various stakeholders regarding recognition and financial benefits, including how royalties are circulated for digital rights management. In this work, we take a step toward acknowledging this impact and consider VI systems as socio-technical systems rather than isolated technologies. We propose a framework for quantifying performance disparities across 5 systems and 6 relevant side attributes: gender, popularity, country, language, year, and prevalence. We also consider 3 main stakeholders for this particular information retrieval use case: the performing artists of query tracks, those of reference (original) tracks, and the composers. By categorizing the recordings in our dataset using such attributes and stakeholders, we analyze whether the considered VI systems show any implicit biases. We find signs of disparities in identification performance for most of the groups we include in our analyses. Moreover, we also find that learning- and rule-based systems behave differently for some attributes, which suggests an additional dimension to consider along with accuracy and scalability when evaluating VI systems. Lastly, we share our dataset with attribute annotations to encourage VI researchers to take these aspects into account while building new systems.
Audio-based Musical Version Identification: Elements and Challenges
Sep 06, 2021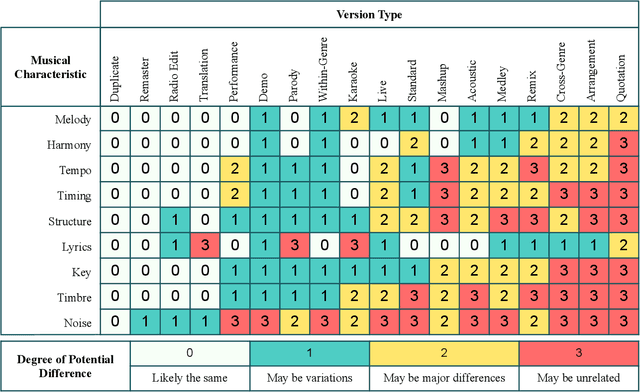
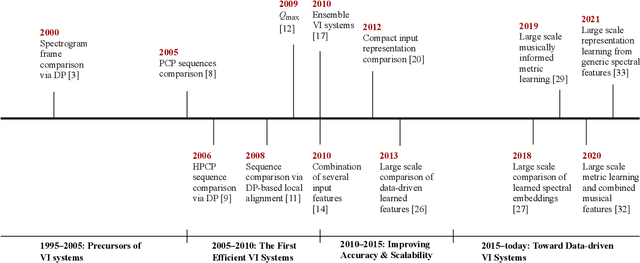
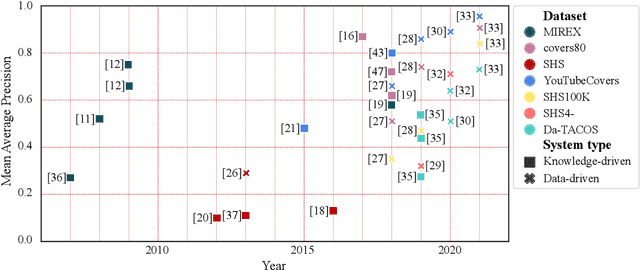
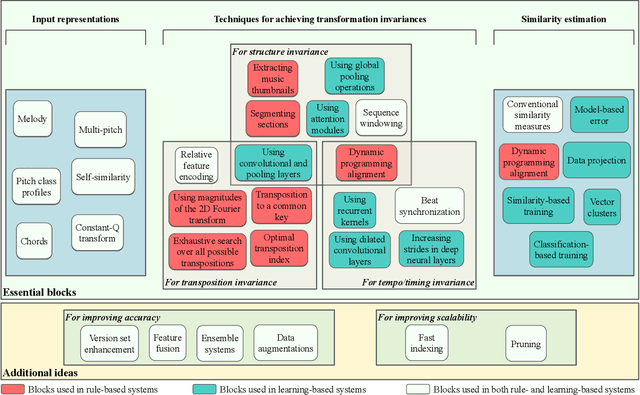
In this article, we aim to provide a review of the key ideas and approaches proposed in 20 years of scientific literature around musical version identification (VI) research and connect them to current practice. For more than a decade, VI systems suffered from the accuracy-scalability trade-off, with attempts to increase accuracy that typically resulted in cumbersome, non-scalable systems. Recent years, however, have witnessed the rise of deep learning-based approaches that take a step toward bridging the accuracy-scalability gap, yielding systems that can realistically be deployed in industrial applications. Although this trend positively influences the number of researchers and institutions working on VI, it may also result in obscuring the literature before the deep learning era. To appreciate two decades of novel ideas in VI research and to facilitate building better systems, we now review some of the successful concepts and applications proposed in the literature and study their evolution throughout the years.
Investigating the efficacy of music version retrieval systems for setlist identification
Jan 06, 2021
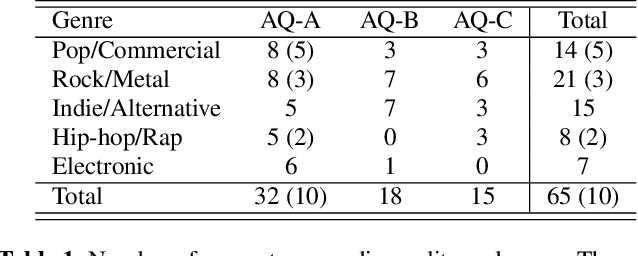

The setlist identification (SLI) task addresses a music recognition use case where the goal is to retrieve the metadata and timestamps for all the tracks played in live music events. Due to various musical and non-musical changes in live performances, developing automatic SLI systems is still a challenging task that, despite its industrial relevance, has been under-explored in the academic literature. In this paper, we propose an end-to-end workflow that identifies relevant metadata and timestamps of live music performances using a version identification system. We compare 3 of such systems to investigate their suitability for this particular task. For developing and evaluating SLI systems, we also contribute a new dataset that contains 99.5h of concerts with annotated metadata and timestamps, along with the corresponding reference set. The dataset is categorized by audio qualities and genres to analyze the performance of SLI systems in different use cases. Our approach can identify 68% of the annotated segments, with values ranging from 35% to 77% based on the genre. Finally, we evaluate our approach against a database of 56.8k songs to illustrate the effect of expanding the reference set, where we can still identify 56% of the annotated segments.
Less is more: Faster and better music version identification with embedding distillation
Oct 07, 2020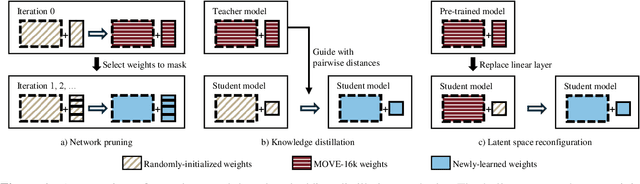
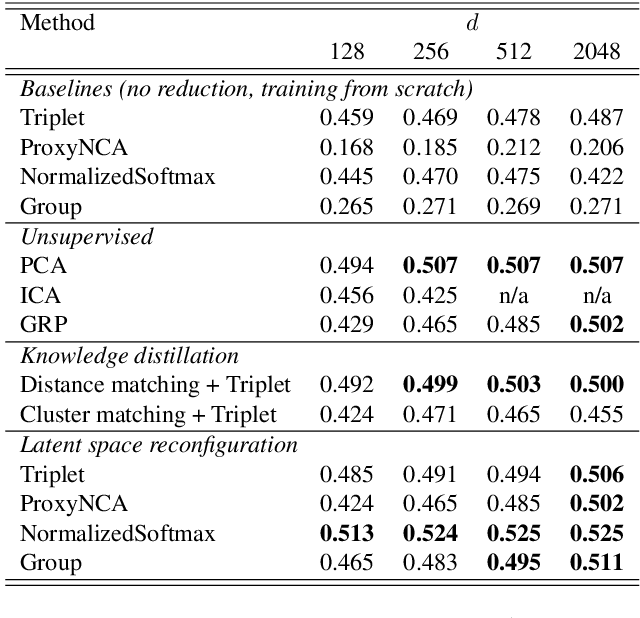
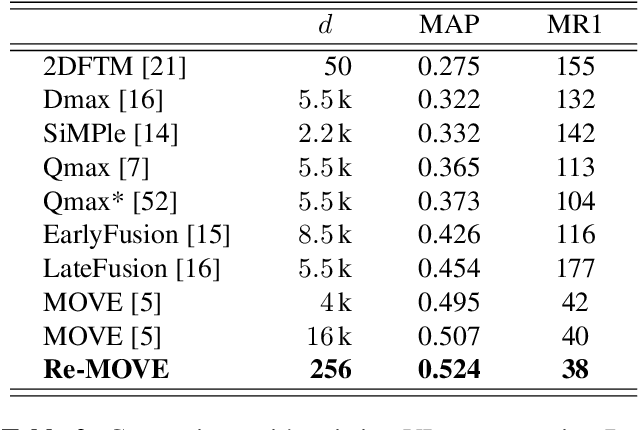
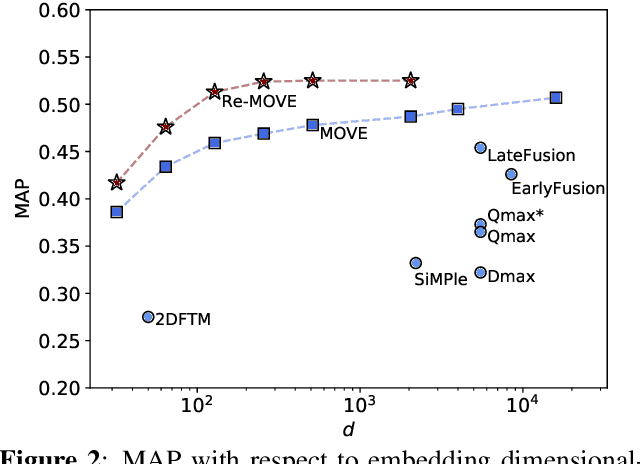
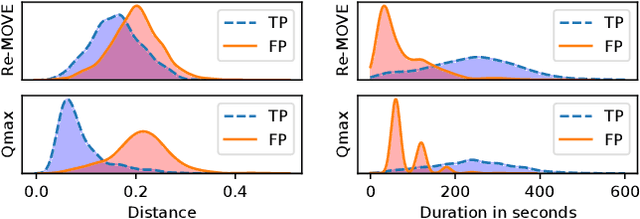
Version identification systems aim to detect different renditions of the same underlying musical composition (loosely called cover songs). By learning to encode entire recordings into plain vector embeddings, recent systems have made significant progress in bridging the gap between accuracy and scalability, which has been a key challenge for nearly two decades. In this work, we propose to further narrow this gap by employing a set of data distillation techniques that reduce the embedding dimensionality of a pre-trained state-of-the-art model. We compare a wide range of techniques and propose new ones, from classical dimensionality reduction to more sophisticated distillation schemes. With those, we obtain 99% smaller embeddings that, moreover, yield up to a 3% accuracy increase. Such small embeddings can have an important impact in retrieval time, up to the point of making a real-world system practical on a standalone laptop.
Accurate and Scalable Version Identification Using Musically-Motivated Embeddings
Oct 28, 2019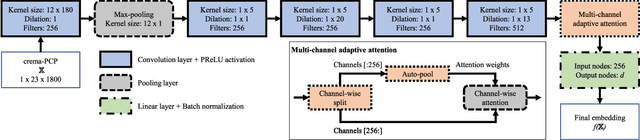
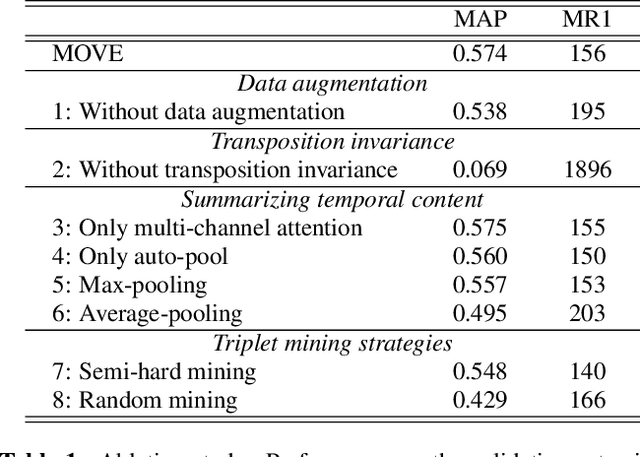
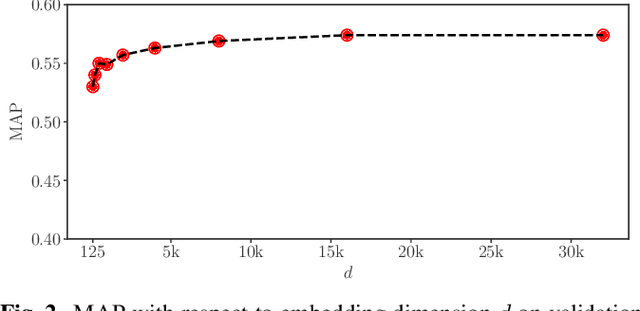
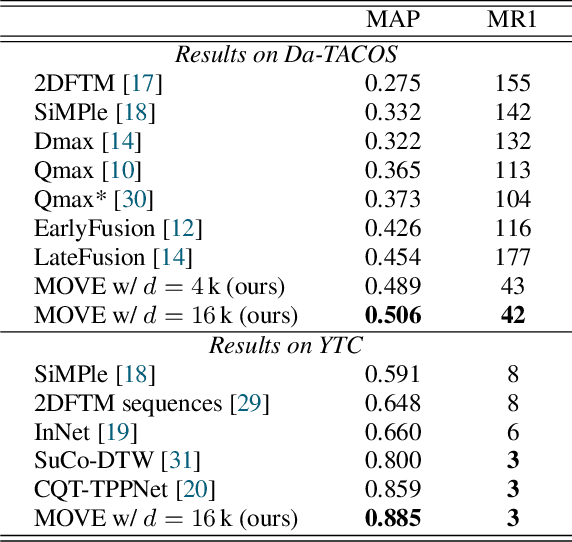
The version identification (VI) task deals with the automatic detection of recordings that correspond to the same underlying musical piece. Despite many efforts, VI is still an open problem, with much room for improvement, specially with regard to combining accuracy and scalability. In this paper, we present MOVE, a musically-motivated method for accurate and scalable version identification. MOVE achieves state-of-the-art performance on two publicly-available benchmark sets by learning scalable embeddings in an Euclidean distance space, using a triplet loss and a hard triplet mining strategy. It improves over previous work by employing an alternative input representation, and introducing a novel technique for temporal content summarization, a standardized latent space, and a data augmentation strategy specifically designed for VI. In addition to the main results, we perform an ablation study to highlight the importance of our design choices, and study the relation between embedding dimensionality and model performance.