 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeed-Music: A Unified Framework for High Quality and Controlled Music Generation
Sep 13, 2024



We introduce Seed-Music, a suite of music generation systems capable of producing high-quality music with fine-grained style control. Our unified framework leverages both auto-regressive language modeling and diffusion approaches to support two key music creation workflows: \textit{controlled music generation} and \textit{post-production editing}. For controlled music generation, our system enables vocal music generation with performance controls from multi-modal inputs, including style descriptions, audio references, musical scores, and voice prompts. For post-production editing, it offers interactive tools for editing lyrics and vocal melodies directly in the generated audio. We encourage readers to listen to demo audio examples at https://team.doubao.com/seed-music .
SymPAC: Scalable Symbolic Music Generation With Prompts And Constraints
Sep 04, 2024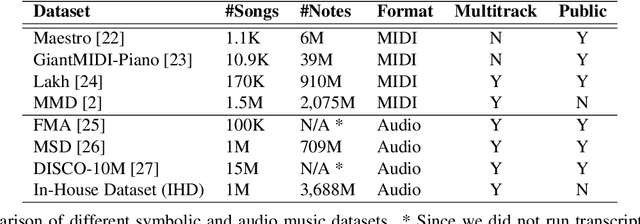


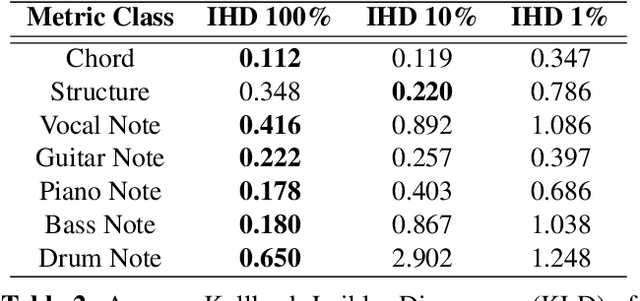
Progress in the task of symbolic music generation may be lagging behind other tasks like audio and text generation, in part because of the scarcity of symbolic training data. In this paper, we leverage the greater scale of audio music data by applying pre-trained MIR models (for transcription, beat tracking, structure analysis, etc.) to extract symbolic events and encode them into token sequences. To the best of our knowledge, this work is the first to demonstrate the feasibility of training symbolic generation models solely from auto-transcribed audio data. Furthermore, to enhance the controllability of the trained model, we introduce SymPAC (Symbolic Music Language Model with Prompting And Constrained Generation), which is distinguished by using (a) prompt bars in encoding and (b) a technique called Constrained Generation via Finite State Machines (FSMs) during inference time. We show the flexibility and controllability of this approach, which may be critical in making music AI useful to creators and users.
StemGen: A music generation model that listens
Dec 14, 2023

End-to-end generation of musical audio using deep learning techniques has seen an explosion of activity recently. However, most models concentrate on generating fully mixed music in response to abstract conditioning information. In this work, we present an alternative paradigm for producing music generation models that can listen and respond to musical context. We describe how such a model can be constructed using a non-autoregressive, transformer-based model architecture and present a number of novel architectural and sampling improvements. We train the described architecture on both an open-source and a proprietary dataset. We evaluate the produced models using standard quality metrics and a new approach based on music information retrieval descriptors. The resulting model reaches the audio quality of state-of-the-art text-conditioned models, as well as exhibiting strong musical coherence with its context.
Music Classification: Beyond Supervised Learning, Towards Real-world Applications
Dec 03, 2021Music classification is a music information retrieval (MIR) task to classify music items to labels such as genre, mood, and instruments. It is also closely related to other concepts such as music similarity and musical preference. In this tutorial, we put our focus on two directions - the recent training schemes beyond supervised learning and the successful application of music classification models. The target audience for this web book is researchers and practitioners who are interested in state-of-the-art music classification research and building real-world applications. We assume the audience is familiar with the basic machine learning concepts. In this book, we present three lectures as follows: 1. Music classification overview: Task definition, applications, existing approaches, datasets, 2. Beyond supervised learning: Semi- and self-supervised learning for music classification, 3. Towards real-world applications: Less-discussed, yet important research issues in practice.
Contrastive Learning of Musical Representations
Mar 17, 2021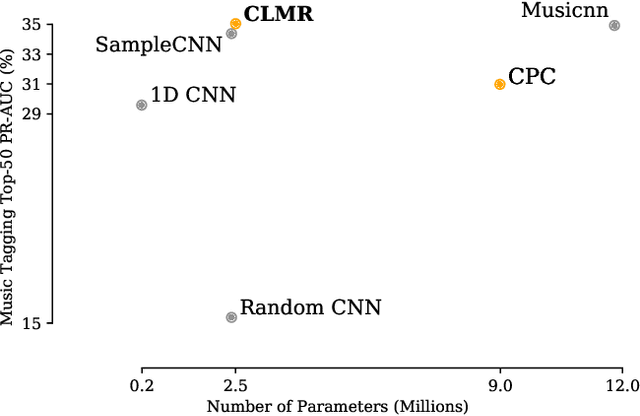
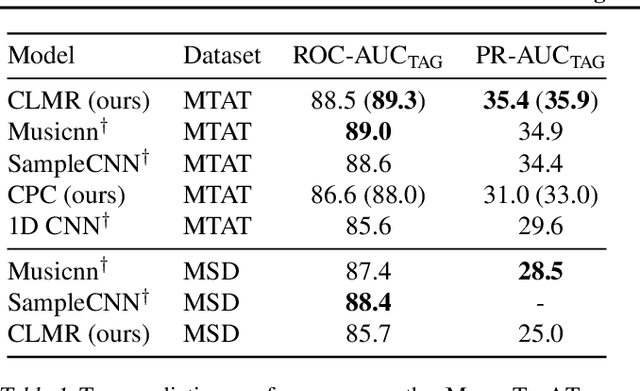
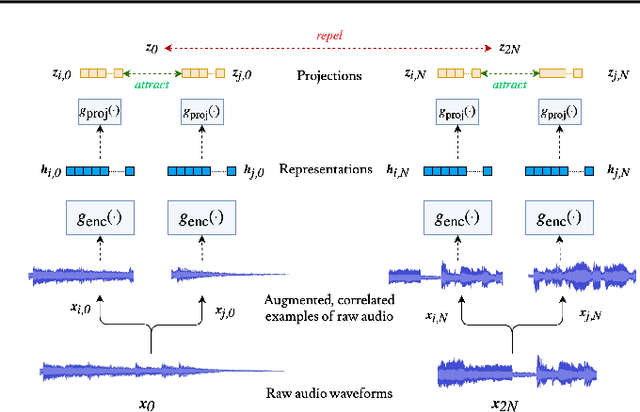
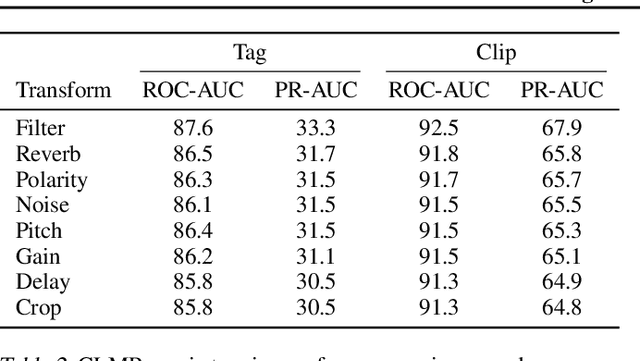
While supervised learning has enabled great advances in many areas of music, labeled music datasets remain especially hard, expensive and time-consuming to create. In this work, we introduce SimCLR to the music domain and contribute a large chain of audio data augmentations, to form a simple framework for self-supervised learning of raw waveforms of music: CLMR. This approach requires no manual labeling and no preprocessing of music to learn useful representations. We evaluate CLMR in the downstream task of music classification on the MagnaTagATune and Million Song datasets. A linear classifier fine-tuned on representations from a pre-trained CLMR model achieves an average precision of 35.4% on the MagnaTagATune dataset, superseding fully supervised models that currently achieve a score of 34.9%. Moreover, we show that CLMR's representations are transferable using out-of-domain datasets, indicating that they capture important musical knowledge. Lastly, we show that self-supervised pre-training allows us to learn efficiently on smaller labeled datasets: we still achieve a score of 33.1% despite using only 259 labeled songs during fine-tuning. To foster reproducibility and future research on self-supervised learning in music, we publicly release the pre-trained models and the source code of all experiments of this paper on GitHub.