 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSymPAC: Scalable Symbolic Music Generation With Prompts And Constraints
Sep 04, 2024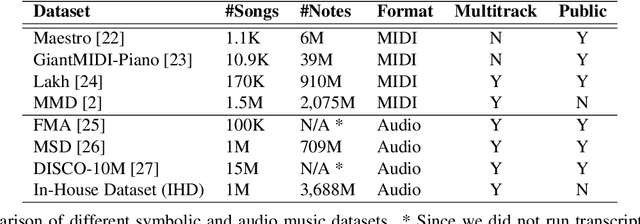


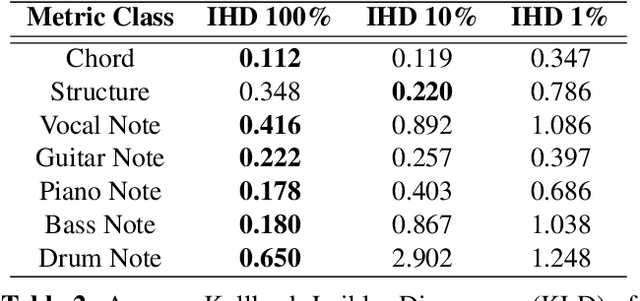
Progress in the task of symbolic music generation may be lagging behind other tasks like audio and text generation, in part because of the scarcity of symbolic training data. In this paper, we leverage the greater scale of audio music data by applying pre-trained MIR models (for transcription, beat tracking, structure analysis, etc.) to extract symbolic events and encode them into token sequences. To the best of our knowledge, this work is the first to demonstrate the feasibility of training symbolic generation models solely from auto-transcribed audio data. Furthermore, to enhance the controllability of the trained model, we introduce SymPAC (Symbolic Music Language Model with Prompting And Constrained Generation), which is distinguished by using (a) prompt bars in encoding and (b) a technique called Constrained Generation via Finite State Machines (FSMs) during inference time. We show the flexibility and controllability of this approach, which may be critical in making music AI useful to creators and users.
Modeling the Rhythm from Lyrics for Melody Generation of Pop Song
Jan 03, 2023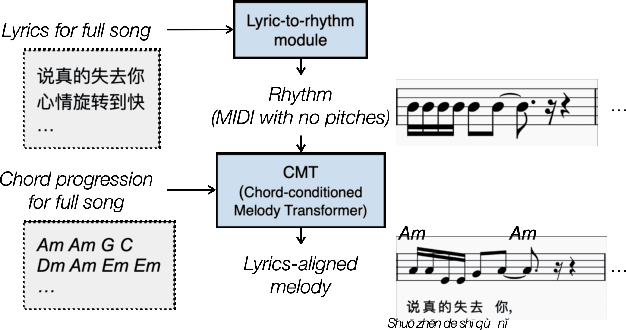

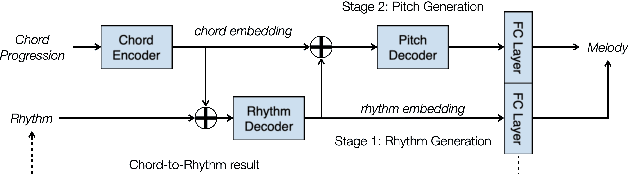
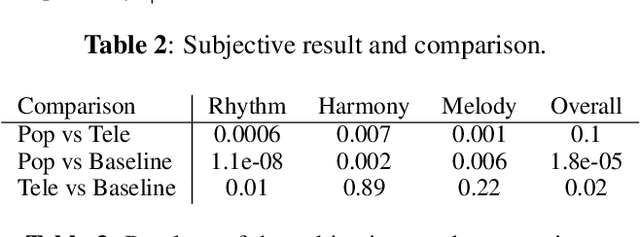
Creating a pop song melody according to pre-written lyrics is a typical practice for composers. A computational model of how lyrics are set as melodies is important for automatic composition systems, but an end-to-end lyric-to-melody model would require enormous amounts of paired training data. To mitigate the data constraints, we adopt a two-stage approach, dividing the task into lyric-to-rhythm and rhythm-to-melody modules. However, the lyric-to-rhythm task is still challenging due to its multimodality. In this paper, we propose a novel lyric-to-rhythm framework that includes part-of-speech tags to achieve better text setting, and a Transformer architecture designed to model long-term syllable-to-note associations. For the rhythm-to-melody task, we adapt a proven chord-conditioned melody Transformer, which has achieved state-of-the-art results. Experiments for Chinese lyric-to-melody generation show that the proposed framework is able to model key characteristics of rhythm and pitch distributions in the dataset, and in a subjective evaluation, the melodies generated by our system were rated as similar to or better than those of a state-of-the-art alternative.
MuSFA: Improving Music Structural Function Analysis with Partially Labeled Data
Nov 28, 2022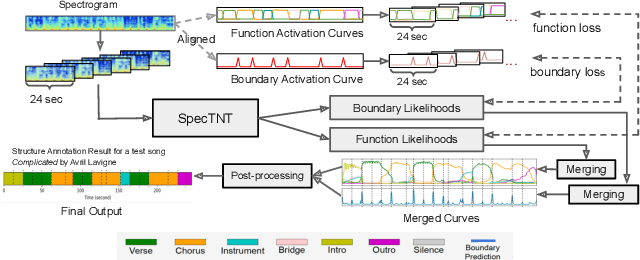

Music structure analysis (MSA) systems aim to segment a song recording into non-overlapping sections with useful labels. Previous MSA systems typically predict abstract labels in a post-processing step and require the full context of the song. By contrast, we recently proposed a supervised framework, called "Music Structural Function Analysis" (MuSFA), that models and predicts meaningful labels like 'verse' and 'chorus' directly from audio, without requiring the full context of a song. However, the performance of this system depends on the amount and quality of training data. In this paper, we propose to repurpose a public dataset, HookTheory Lead Sheet Dataset (HLSD), to improve the performance. HLSD contains over 18K excerpts of music sections originally collected for studying automatic melody harmonization. We treat each excerpt as a partially labeled song and provide a label mapping, so that HLSD can be used together with other public datasets, such as SALAMI, RWC, and Isophonics. In cross-dataset evaluations, we find that including HLSD in training can improve state-of-the-art boundary detection and section labeling scores by ~3% and ~1% respectively.
To catch a chorus, verse, intro, or anything else: Analyzing a song with structural functions
May 29, 2022
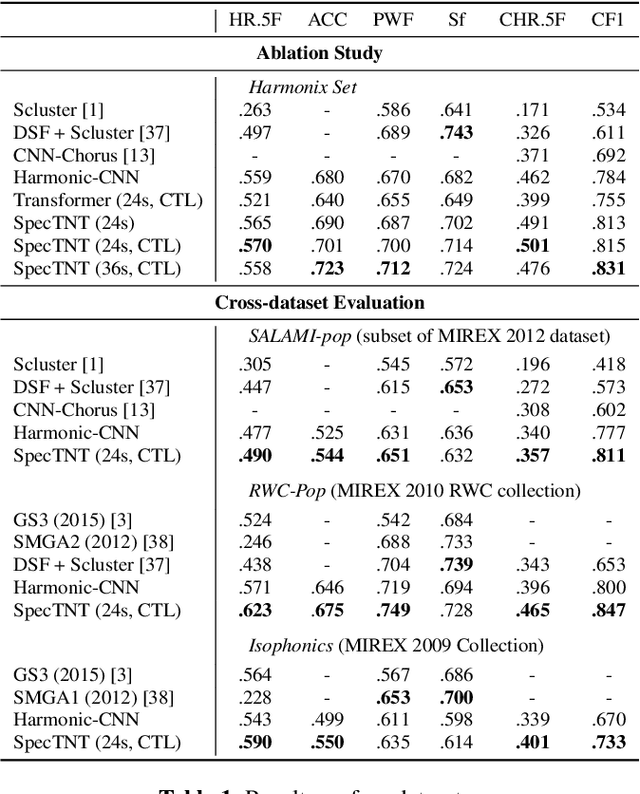
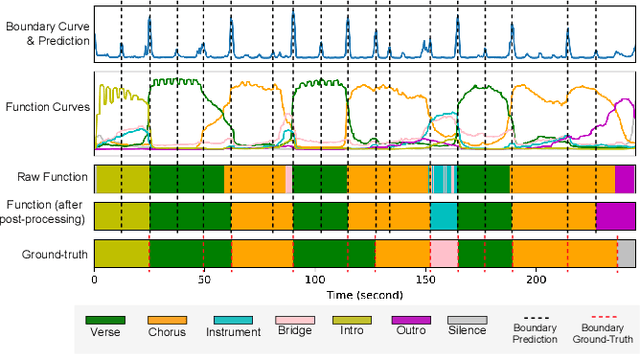
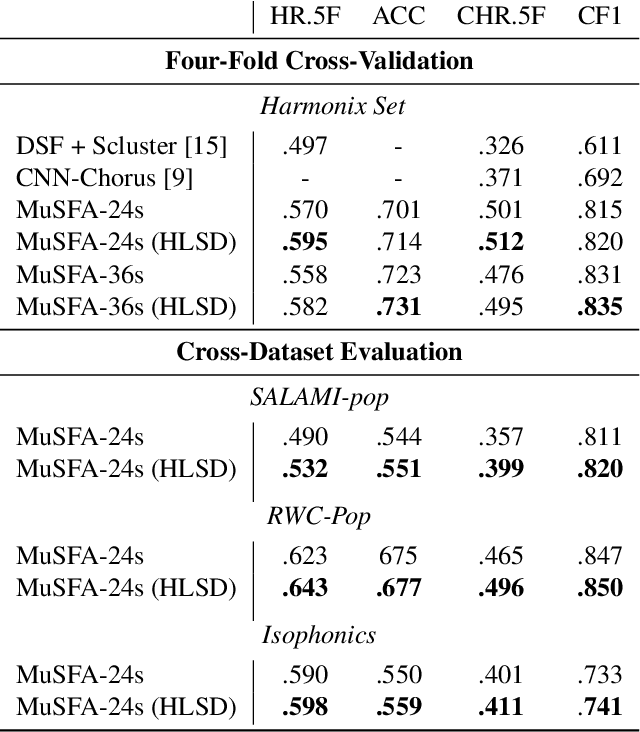
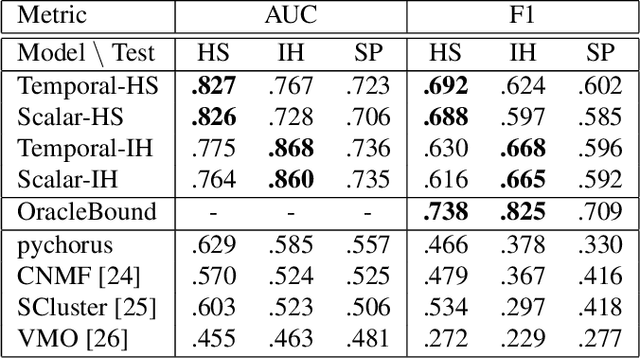
Conventional music structure analysis algorithms aim to divide a song into segments and to group them with abstract labels (e.g., 'A', 'B', and 'C'). However, explicitly identifying the function of each segment (e.g., 'verse' or 'chorus') is rarely attempted, but has many applications. We introduce a multi-task deep learning framework to model these structural semantic labels directly from audio by estimating "verseness," "chorusness," and so forth, as a function of time. We propose a 7-class taxonomy (i.e., intro, verse, chorus, bridge, outro, instrumental, and silence) and provide rules to consolidate annotations from four disparate datasets. We also propose to use a spectral-temporal Transformer-based model, called SpecTNT, which can be trained with an additional connectionist temporal localization (CTL) loss. In cross-dataset evaluations using four public datasets, we demonstrate the effectiveness of the SpecTNT model and CTL loss, and obtain strong results overall: the proposed system outperforms state-of-the-art chorus-detection and boundary-detection methods at detecting choruses and boundaries, respectively.
Supervised Metric Learning for Music Structure Feature
Oct 18, 2021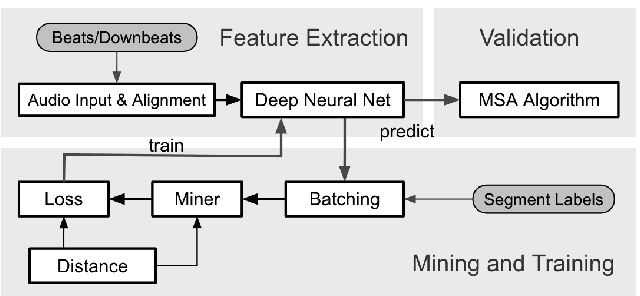
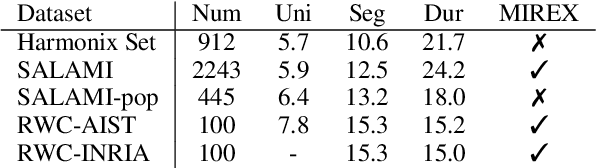
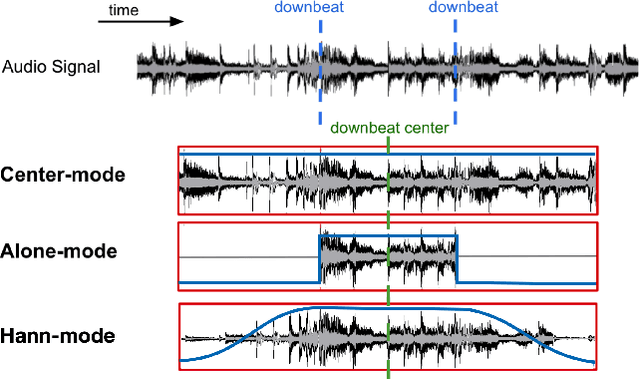
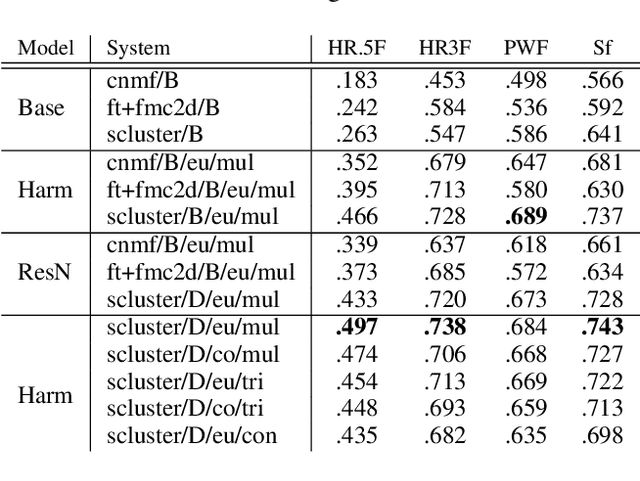
Music structure analysis (MSA) methods traditionally search for musically meaningful patterns in audio: homogeneity, repetition, novelty, and segment-length regularity. Hand-crafted audio features such as MFCCs or chromagrams are often used to elicit these patterns. However, with more annotations of section labels (e.g., verse, chorus, and bridge) becoming available, one can use supervised feature learning to make these patterns even clearer and improve MSA performance. To this end, we take a supervised metric learning approach: we train a deep neural network to output embeddings that are near each other for two spectrogram inputs if both have the same section type (according to an annotation), and otherwise far apart. We propose a batch sampling scheme to ensure the labels in a training pair are interpreted meaningfully. The trained model extracts features that can be used in existing MSA algorithms. In evaluations with three datasets (HarmonixSet, SALAMI, and RWC), we demonstrate that using the proposed features can improve a traditional MSA algorithm significantly in both intra- and cross-dataset scenarios.
Supervised Chorus Detection for Popular Music Using Convolutional Neural Network and Multi-task Learning
Mar 26, 2021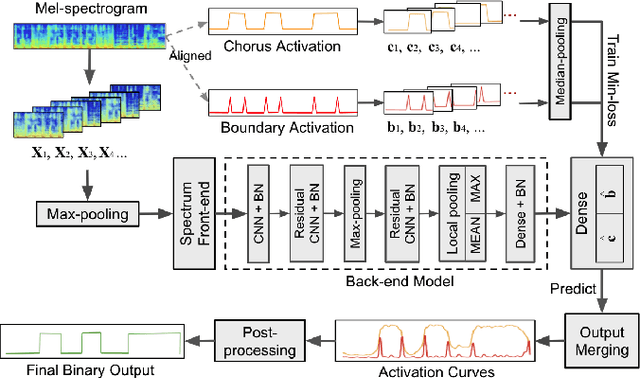
This paper presents a novel supervised approach to detecting the chorus segments in popular music. Traditional approaches to this task are mostly unsupervised, with pipelines designed to target some quality that is assumed to define "chorusness," which usually means seeking the loudest or most frequently repeated sections. We propose to use a convolutional neural network with a multi-task learning objective, which simultaneously fits two temporal activation curves: one indicating "chorusness" as a function of time, and the other the location of the boundaries. We also propose a post-processing method that jointly takes into account the chorus and boundary predictions to produce binary output. In experiments using three datasets, we compare our system to a set of public implementations of other segmentation and chorus-detection algorithms, and find our approach performs significantly better.
Modeling the Compatibility of Stem Tracks to Generate Music Mashups
Mar 26, 2021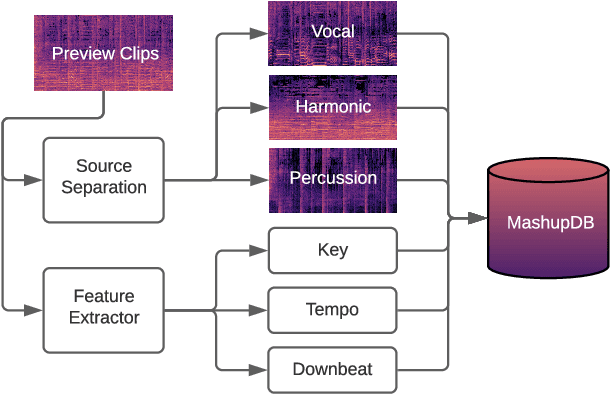
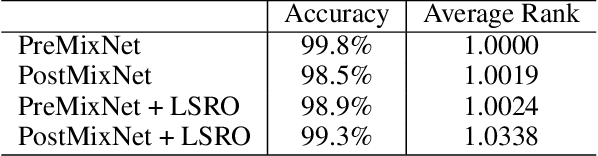
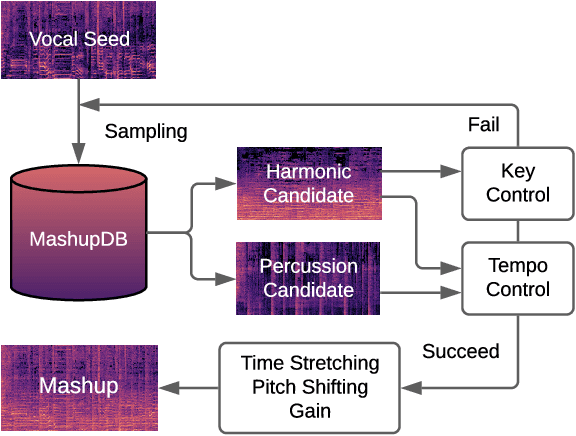
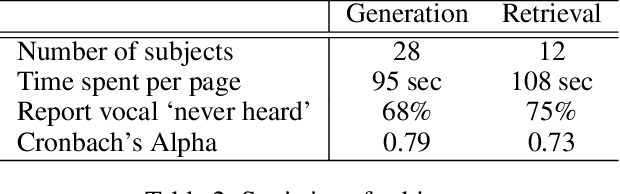
A music mashup combines audio elements from two or more songs to create a new work. To reduce the time and effort required to make them, researchers have developed algorithms that predict the compatibility of audio elements. Prior work has focused on mixing unaltered excerpts, but advances in source separation enable the creation of mashups from isolated stems (e.g., vocals, drums, bass, etc.). In this work, we take advantage of separated stems not just for creating mashups, but for training a model that predicts the mutual compatibility of groups of excerpts, using self-supervised and semi-supervised methods. Specifically, we first produce a random mashup creation pipeline that combines stem tracks obtained via source separation, with key and tempo automatically adjusted to match, since these are prerequisites for high-quality mashups. To train a model to predict compatibility, we use stem tracks obtained from the same song as positive examples, and random combinations of stems with key and/or tempo unadjusted as negative examples. To improve the model and use more data, we also train on "average" examples: random combinations with matching key and tempo, where we treat them as unlabeled data as their true compatibility is unknown. To determine whether the combined signal or the set of stem signals is more indicative of the quality of the result, we experiment on two model architectures and train them using semi-supervised learning technique. Finally, we conduct objective and subjective evaluations of the system, comparing them to a standard rule-based system.
Neural Loop Combiner: Neural Network Models for Assessing the Compatibility of Loops
Aug 05, 2020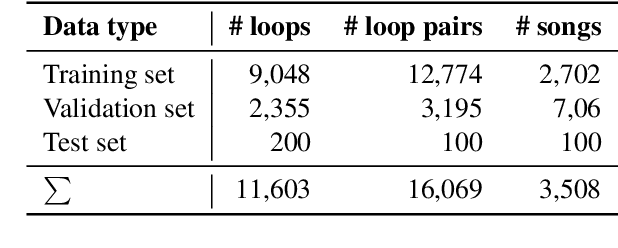
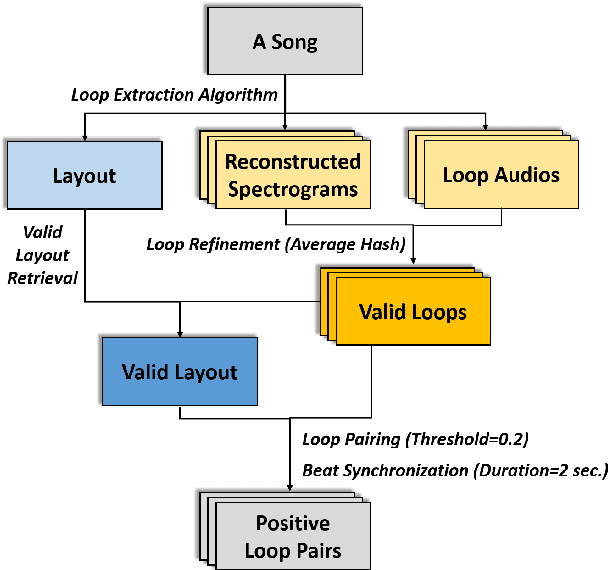
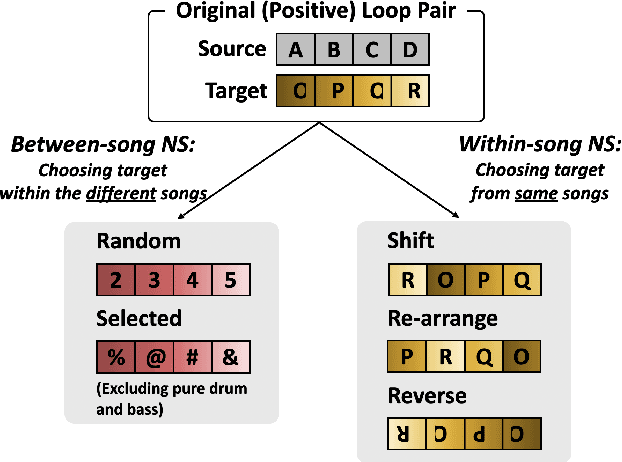
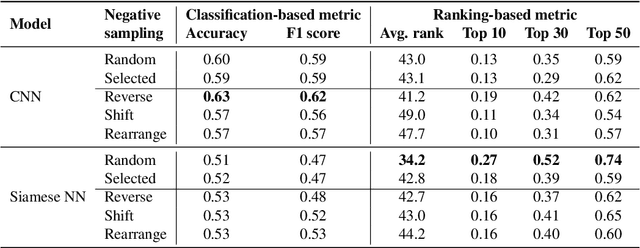
Music producers who use loops may have access to thousands in loop libraries, but finding ones that are compatible is a time-consuming process; we hope to reduce this burden with automation. State-of-the-art systems for estimating compatibility, such as AutoMashUpper, are mostly rule-based and could be improved on with machine learning. To train a model, we need a large set of loops with ground truth compatibility values. No such dataset exists, so we extract loops from existing music to obtain positive examples of compatible loops, and propose and compare various strategies for choosing negative examples. For reproducibility, we curate data from the Free Music Archive. Using this data, we investigate two types of model architectures for estimating the compatibility of loops: one based on a Siamese network, and the other a pure convolutional neural network (CNN). We conducted a user study in which participants rated the quality of the combinations suggested by each model, and found the CNN to outperform the Siamese network. Both model-based approaches outperformed the rule-based one. We have opened source the code for building the models and the dataset.