 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeed-Music: A Unified Framework for High Quality and Controlled Music Generation
Sep 13, 2024



We introduce Seed-Music, a suite of music generation systems capable of producing high-quality music with fine-grained style control. Our unified framework leverages both auto-regressive language modeling and diffusion approaches to support two key music creation workflows: \textit{controlled music generation} and \textit{post-production editing}. For controlled music generation, our system enables vocal music generation with performance controls from multi-modal inputs, including style descriptions, audio references, musical scores, and voice prompts. For post-production editing, it offers interactive tools for editing lyrics and vocal melodies directly in the generated audio. We encourage readers to listen to demo audio examples at https://team.doubao.com/seed-music .
SymPAC: Scalable Symbolic Music Generation With Prompts And Constraints
Sep 04, 2024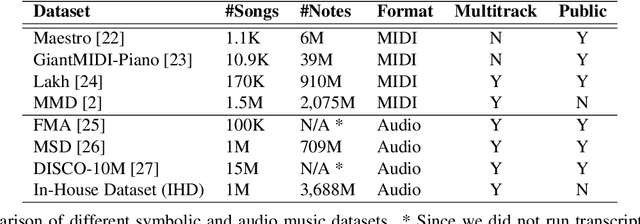


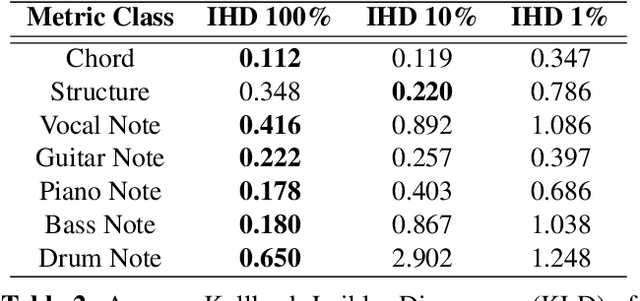
Progress in the task of symbolic music generation may be lagging behind other tasks like audio and text generation, in part because of the scarcity of symbolic training data. In this paper, we leverage the greater scale of audio music data by applying pre-trained MIR models (for transcription, beat tracking, structure analysis, etc.) to extract symbolic events and encode them into token sequences. To the best of our knowledge, this work is the first to demonstrate the feasibility of training symbolic generation models solely from auto-transcribed audio data. Furthermore, to enhance the controllability of the trained model, we introduce SymPAC (Symbolic Music Language Model with Prompting And Constrained Generation), which is distinguished by using (a) prompt bars in encoding and (b) a technique called Constrained Generation via Finite State Machines (FSMs) during inference time. We show the flexibility and controllability of this approach, which may be critical in making music AI useful to creators and users.
Jointist: Simultaneous Improvement of Multi-instrument Transcription and Music Source Separation via Joint Training
Feb 02, 2023



In this paper, we introduce Jointist, an instrument-aware multi-instrument framework that is capable of transcribing, recognizing, and separating multiple musical instruments from an audio clip. Jointist consists of an instrument recognition module that conditions the other two modules: a transcription module that outputs instrument-specific piano rolls, and a source separation module that utilizes instrument information and transcription results. The joint training of the transcription and source separation modules serves to improve the performance of both tasks. The instrument module is optional and can be directly controlled by human users. This makes Jointist a flexible user-controllable framework. Our challenging problem formulation makes the model highly useful in the real world given that modern popular music typically consists of multiple instruments. Its novelty, however, necessitates a new perspective on how to evaluate such a model. In our experiments, we assess the proposed model from various aspects, providing a new evaluation perspective for multi-instrument transcription. Our subjective listening study shows that Jointist achieves state-of-the-art performance on popular music, outperforming existing multi-instrument transcription models such as MT3. We conducted experiments on several downstream tasks and found that the proposed method improved transcription by more than 1 percentage points (ppt.), source separation by 5 SDR, downbeat detection by 1.8 ppt., chord recognition by 1.4 ppt., and key estimation by 1.4 ppt., when utilizing transcription results obtained from Jointist. Demo available at \url{https://jointist.github.io/Demo}.
Jointist: Joint Learning for Multi-instrument Transcription and Its Applications
Jun 28, 2022
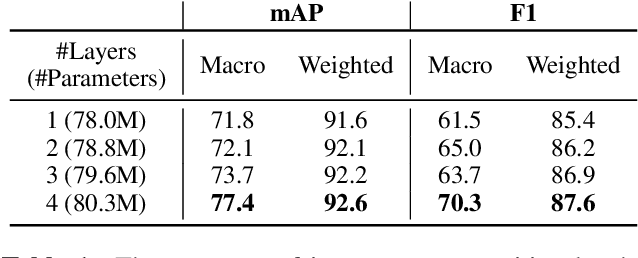
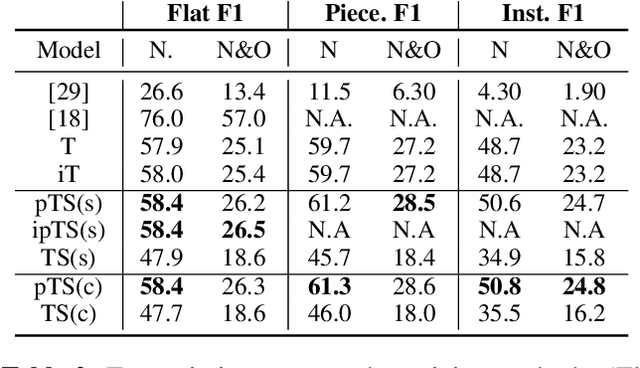

In this paper, we introduce Jointist, an instrument-aware multi-instrument framework that is capable of transcribing, recognizing, and separating multiple musical instruments from an audio clip. Jointist consists of the instrument recognition module that conditions the other modules: the transcription module that outputs instrument-specific piano rolls, and the source separation module that utilizes instrument information and transcription results. The instrument conditioning is designed for an explicit multi-instrument functionality while the connection between the transcription and source separation modules is for better transcription performance. Our challenging problem formulation makes the model highly useful in the real world given that modern popular music typically consists of multiple instruments. However, its novelty necessitates a new perspective on how to evaluate such a model. During the experiment, we assess the model from various aspects, providing a new evaluation perspective for multi-instrument transcription. We also argue that transcription models can be utilized as a preprocessing module for other music analysis tasks. In the experiment on several downstream tasks, the symbolic representation provided by our transcription model turned out to be helpful to spectrograms in solving downbeat detection, chord recognition, and key estimation.
Audiovisual Singing Voice Separation
Jul 01, 2021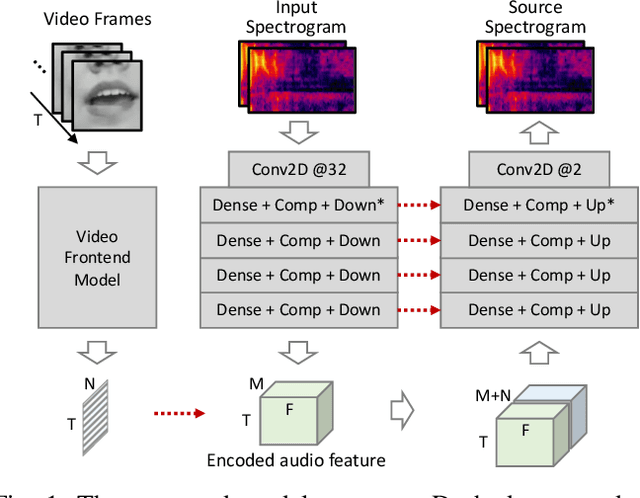
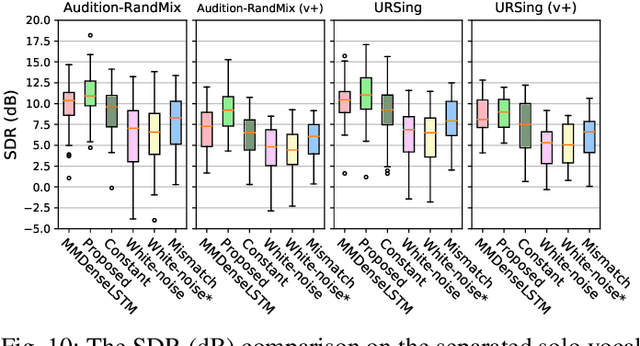
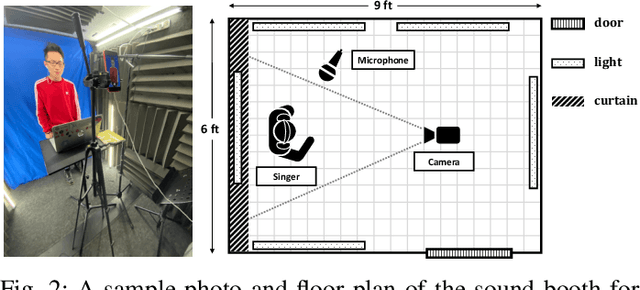

Separating a song into vocal and accompaniment components is an active research topic, and recent years witnessed an increased performance from supervised training using deep learning techniques. We propose to apply the visual information corresponding to the singers' vocal activities to further improve the quality of the separated vocal signals. The video frontend model takes the input of mouth movement and fuses it into the feature embeddings of an audio-based separation framework. To facilitate the network to learn audiovisual correlation of singing activities, we add extra vocal signals irrelevant to the mouth movement to the audio mixture during training. We create two audiovisual singing performance datasets for training and evaluation, respectively, one curated from audition recordings on the Internet, and the other recorded in house. The proposed method outperforms audio-based methods in terms of separation quality on most test recordings. This advantage is especially pronounced when there are backing vocals in the accompaniment, which poses a great challenge for audio-only methods.
High-resolution Piano Transcription with Pedals by Regressing Onsets and Offsets Times
Oct 05, 2020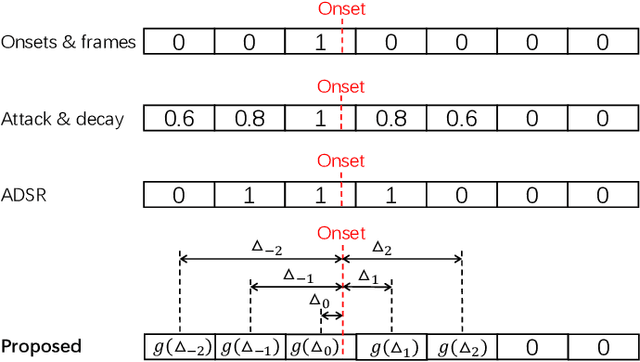
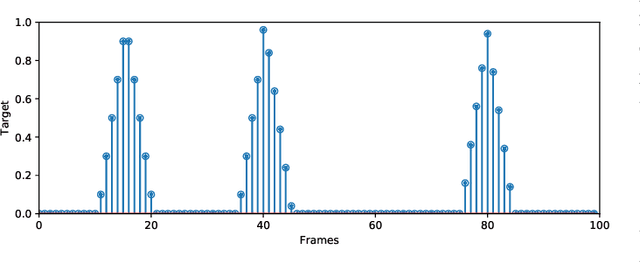
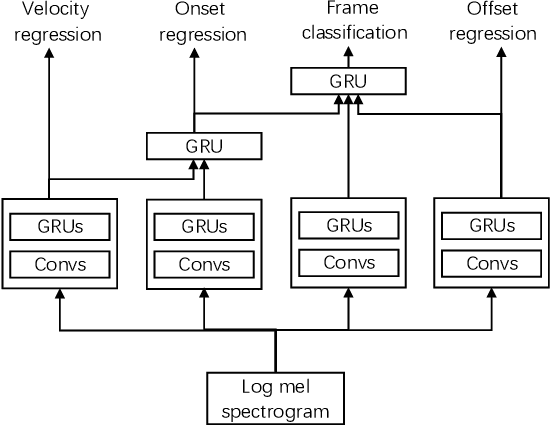

Automatic music transcription (AMT) is the task of transcribing audio recordings into symbolic representations such as Musical Instrument Digital Interface (MIDI). Recently, neural networks based methods have been applied to AMT, and have achieved state-of-the-art result. However, most of previous AMT systems predict the presence or absence of notes in the frames of audio recordings. The transcription resolution of those systems are limited to the hop size time between adjacent frames. In addition, previous AMT systems are sensitive to the misaligned onsets and offsets labels of audio recordings. For high-resolution evaluation, previous works have not investigated AMT systems evaluated with different onsets and offsets tolerances. For piano transcription, there is a lack of research on building AMT systems with both note and pedal transcription. In this article, we propose a high-resolution AMT system trained by regressing precise times of onsets and offsets. In inference, we propose an algorithm to analytically calculate the precise onsets and offsets times of note and pedal events. We build both note and pedal transcription systems with our high-resolution AMT system. We show that our AMT system is robust to misaligned onsets and offsets labels compared to previous systems. Our proposed system achieves an onset F1 of 96.72% on the MAESTRO dataset, outperforming the onsets and frames system from Google of 94.80%. Our system achieves a pedal onset F1 score of 91.86%, and is the first benchmark result on the MAESTRO dataset. We release the source code of our work at https://github.com/bytedance/piano\_transcription.
Audio-Visual Event Localization in Unconstrained Videos
Mar 23, 2018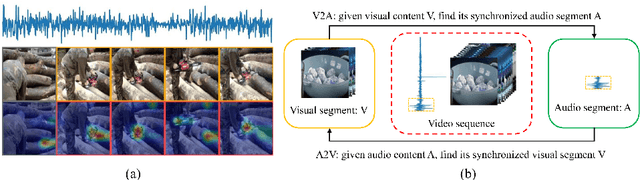



In this paper, we introduce a novel problem of audio-visual event localization in unconstrained videos. We define an audio-visual event as an event that is both visible and audible in a video segment. We collect an Audio-Visual Event(AVE) dataset to systemically investigate three temporal localization tasks: supervised and weakly-supervised audio-visual event localization, and cross-modality localization. We develop an audio-guided visual attention mechanism to explore audio-visual correlations, propose a dual multimodal residual network (DMRN) to fuse information over the two modalities, and introduce an audio-visual distance learning network to handle the cross-modality localization. Our experiments support the following findings: joint modeling of auditory and visual modalities outperforms independent modeling, the learned attention can capture semantics of sounding objects, temporal alignment is important for audio-visual fusion, the proposed DMRN is effective in fusing audio-visual features, and strong correlations between the two modalities enable cross-modality localization.