 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio-Visual Event Localization in Unconstrained Videos
Paper and Code
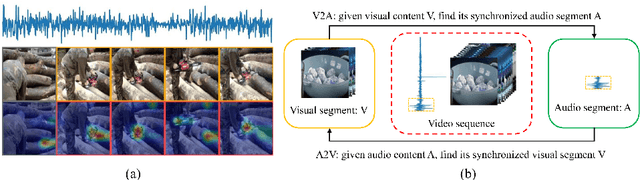



In this paper, we introduce a novel problem of audio-visual event localization in unconstrained videos. We define an audio-visual event as an event that is both visible and audible in a video segment. We collect an Audio-Visual Event(AVE) dataset to systemically investigate three temporal localization tasks: supervised and weakly-supervised audio-visual event localization, and cross-modality localization. We develop an audio-guided visual attention mechanism to explore audio-visual correlations, propose a dual multimodal residual network (DMRN) to fuse information over the two modalities, and introduce an audio-visual distance learning network to handle the cross-modality localization. Our experiments support the following findings: joint modeling of auditory and visual modalities outperforms independent modeling, the learned attention can capture semantics of sounding objects, temporal alignment is important for audio-visual fusion, the proposed DMRN is effective in fusing audio-visual features, and strong correlations between the two modalities enable cross-modality localization.