 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Foundation Model for Music Informatics
Nov 06, 2023

This paper investigates foundation models tailored for music informatics, a domain currently challenged by the scarcity of labeled data and generalization issues. To this end, we conduct an in-depth comparative study among various foundation model variants, examining key determinants such as model architectures, tokenization methods, temporal resolution, data, and model scalability. This research aims to bridge the existing knowledge gap by elucidating how these individual factors contribute to the success of foundation models in music informatics. Employing a careful evaluation framework, we assess the performance of these models across diverse downstream tasks in music information retrieval, with a particular focus on token-level and sequence-level classification. Our results reveal that our model demonstrates robust performance, surpassing existing models in specific key metrics. These findings contribute to the understanding of self-supervised learning in music informatics and pave the way for developing more effective and versatile foundation models in the field. A pretrained version of our model is publicly available to foster reproducibility and future research.
Scaling Up Music Information Retrieval Training with Semi-Supervised Learning
Oct 02, 2023In the era of data-driven Music Information Retrieval (MIR), the scarcity of labeled data has been one of the major concerns to the success of an MIR task. In this work, we leverage the semi-supervised teacher-student training approach to improve MIR tasks. For training, we scale up the unlabeled music data to 240k hours, which is much larger than any public MIR datasets. We iteratively create and refine the pseudo-labels in the noisy teacher-student training process. Knowledge expansion is also explored to iteratively scale up the model sizes from as small as less than 3M to almost 100M parameters. We study the performance correlation between data size and model size in the experiments. By scaling up both model size and training data, our models achieve state-of-the-art results on several MIR tasks compared to models that are either trained in a supervised manner or based on a self-supervised pretrained model. To our knowledge, this is the first attempt to study the effects of scaling up both model and training data for a variety of MIR tasks.
Music Source Separation with Band-Split RoPE Transformer
Sep 10, 2023Music source separation (MSS) aims to separate a music recording into multiple musically distinct stems, such as vocals, bass, drums, and more. Recently, deep learning approaches such as convolutional neural networks (CNNs) and recurrent neural networks (RNNs) have been used, but the improvement is still limited. In this paper, we propose a novel frequency-domain approach based on a Band-Split RoPE Transformer (called BS-RoFormer). BS-RoFormer relies on a band-split module to project the input complex spectrogram into subband-level representations, and then arranges a stack of hierarchical Transformers to model the inner-band as well as inter-band sequences for multi-band mask estimation. To facilitate training the model for MSS, we propose to use the Rotary Position Embedding (RoPE). The BS-RoFormer system trained on MUSDB18HQ and 500 extra songs ranked the first place in the MSS track of Sound Demixing Challenge (SDX23). Benchmarking a smaller version of BS-RoFormer on MUSDB18HQ, we achieve state-of-the-art result without extra training data, with 9.80 dB of average SDR.
Multitrack Music Transcription with a Time-Frequency Perceiver
Jun 19, 2023


Multitrack music transcription aims to transcribe a music audio input into the musical notes of multiple instruments simultaneously. It is a very challenging task that typically requires a more complex model to achieve satisfactory result. In addition, prior works mostly focus on transcriptions of regular instruments, however, neglecting vocals, which are usually the most important signal source if present in a piece of music. In this paper, we propose a novel deep neural network architecture, Perceiver TF, to model the time-frequency representation of audio input for multitrack transcription. Perceiver TF augments the Perceiver architecture by introducing a hierarchical expansion with an additional Transformer layer to model temporal coherence. Accordingly, our model inherits the benefits of Perceiver that posses better scalability, allowing it to well handle transcriptions of many instruments in a single model. In experiments, we train a Perceiver TF to model 12 instrument classes as well as vocal in a multi-task learning manner. Our result demonstrates that the proposed system outperforms the state-of-the-art counterparts (e.g., MT3 and SpecTNT) on various public datasets.
Jointist: Simultaneous Improvement of Multi-instrument Transcription and Music Source Separation via Joint Training
Feb 02, 2023



In this paper, we introduce Jointist, an instrument-aware multi-instrument framework that is capable of transcribing, recognizing, and separating multiple musical instruments from an audio clip. Jointist consists of an instrument recognition module that conditions the other two modules: a transcription module that outputs instrument-specific piano rolls, and a source separation module that utilizes instrument information and transcription results. The joint training of the transcription and source separation modules serves to improve the performance of both tasks. The instrument module is optional and can be directly controlled by human users. This makes Jointist a flexible user-controllable framework. Our challenging problem formulation makes the model highly useful in the real world given that modern popular music typically consists of multiple instruments. Its novelty, however, necessitates a new perspective on how to evaluate such a model. In our experiments, we assess the proposed model from various aspects, providing a new evaluation perspective for multi-instrument transcription. Our subjective listening study shows that Jointist achieves state-of-the-art performance on popular music, outperforming existing multi-instrument transcription models such as MT3. We conducted experiments on several downstream tasks and found that the proposed method improved transcription by more than 1 percentage points (ppt.), source separation by 5 SDR, downbeat detection by 1.8 ppt., chord recognition by 1.4 ppt., and key estimation by 1.4 ppt., when utilizing transcription results obtained from Jointist. Demo available at \url{https://jointist.github.io/Demo}.
MuSFA: Improving Music Structural Function Analysis with Partially Labeled Data
Nov 28, 2022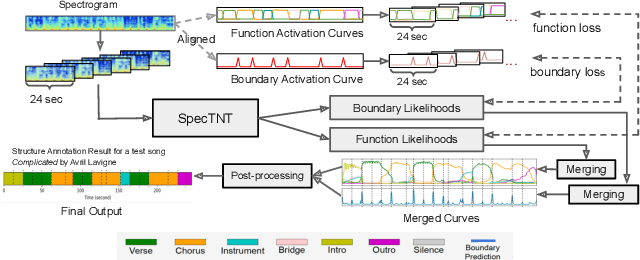

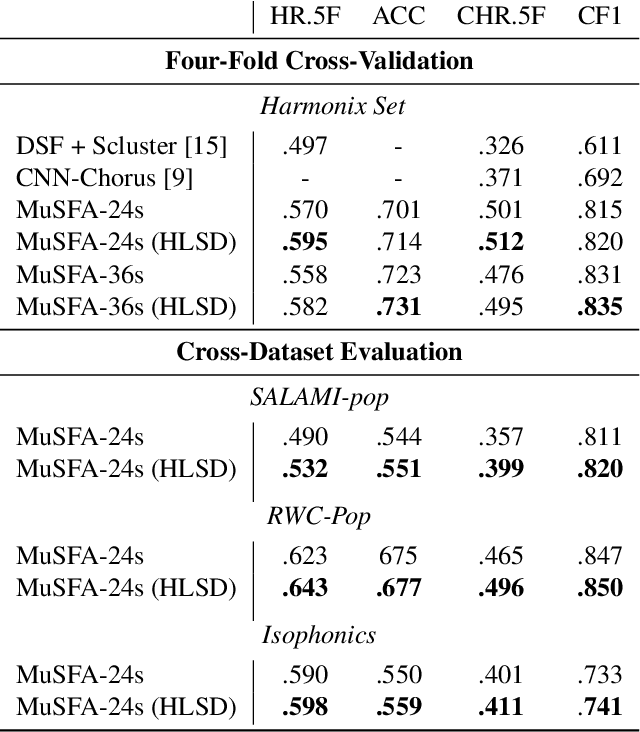
Music structure analysis (MSA) systems aim to segment a song recording into non-overlapping sections with useful labels. Previous MSA systems typically predict abstract labels in a post-processing step and require the full context of the song. By contrast, we recently proposed a supervised framework, called "Music Structural Function Analysis" (MuSFA), that models and predicts meaningful labels like 'verse' and 'chorus' directly from audio, without requiring the full context of a song. However, the performance of this system depends on the amount and quality of training data. In this paper, we propose to repurpose a public dataset, HookTheory Lead Sheet Dataset (HLSD), to improve the performance. HLSD contains over 18K excerpts of music sections originally collected for studying automatic melody harmonization. We treat each excerpt as a partially labeled song and provide a label mapping, so that HLSD can be used together with other public datasets, such as SALAMI, RWC, and Isophonics. In cross-dataset evaluations, we find that including HLSD in training can improve state-of-the-art boundary detection and section labeling scores by ~3% and ~1% respectively.
Low-Resource Music Genre Classification with Advanced Neural Model Reprogramming
Nov 02, 2022



Transfer learning (TL) approaches have shown promising results when handling tasks with limited training data. However, considerable memory and computational resources are often required for fine-tuning pre-trained neural networks with target domain data. In this work, we introduce a novel method for leveraging pre-trained models for low-resource (music) classification based on the concept of Neural Model Reprogramming (NMR). NMR aims at re-purposing a pre-trained model from a source domain to a target domain by modifying the input of a frozen pre-trained model. In addition to the known, input-independent, reprogramming method, we propose an advanced reprogramming paradigm: Input-dependent NMR, to increase adaptability to complex input data such as musical audio. Experimental results suggest that a neural model pre-trained on large-scale datasets can successfully perform music genre classification by using this reprogramming method. The two proposed Input-dependent NMR TL methods outperform fine-tuning-based TL methods on a small genre classification dataset.
Feature-informed Embedding Space Regularization For Audio Classification
Jun 10, 2022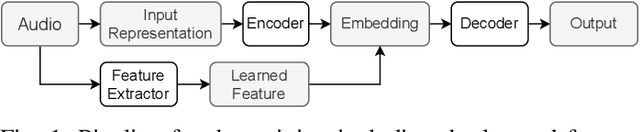
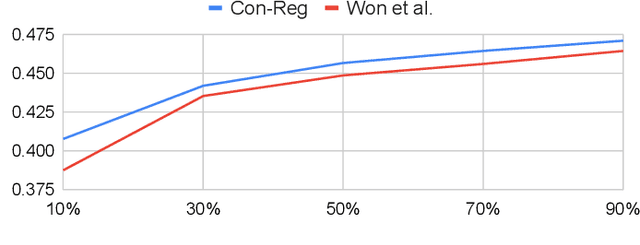
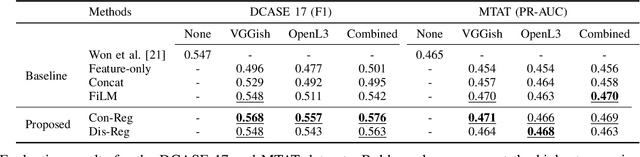
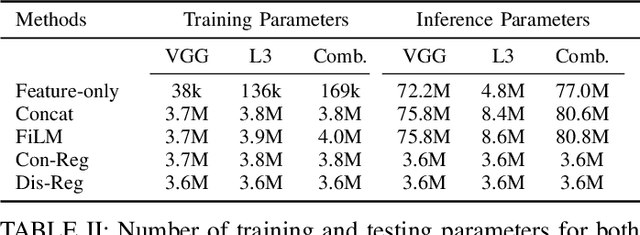
Feature representations derived from models pre-trained on large-scale datasets have shown their generalizability on a variety of audio analysis tasks. Despite this generalizability, however, task-specific features can outperform if sufficient training data is available, as specific task-relevant properties can be learned. Furthermore, the complex pre-trained models bring considerable computational burdens during inference. We propose to leverage both detailed task-specific features from spectrogram input and generic pre-trained features by introducing two regularization methods that integrate the information of both feature classes. The workload is kept low during inference as the pre-trained features are only necessary for training. In experiments with the pre-trained features VGGish, OpenL3, and a combination of both, we show that the proposed methods not only outperform baseline methods, but also can improve state-of-the-art models on several audio classification tasks. The results also suggest that using the mixture of features performs better than using individual features.
Modeling Beats and Downbeats with a Time-Frequency Transformer
May 29, 2022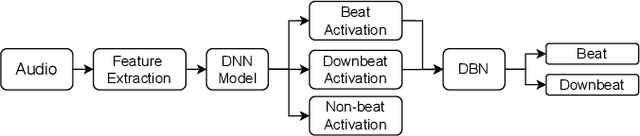
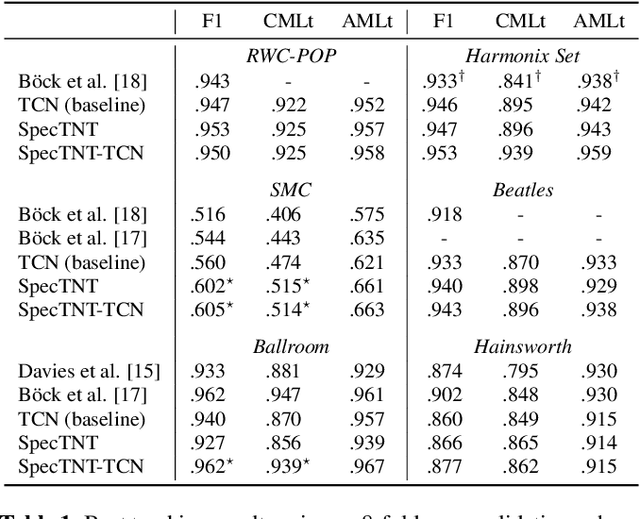
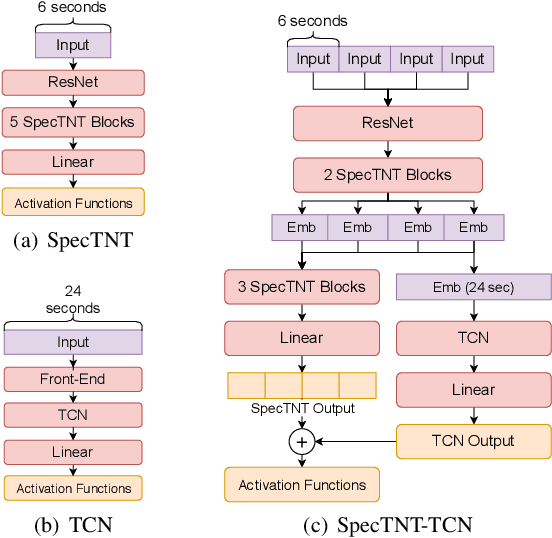
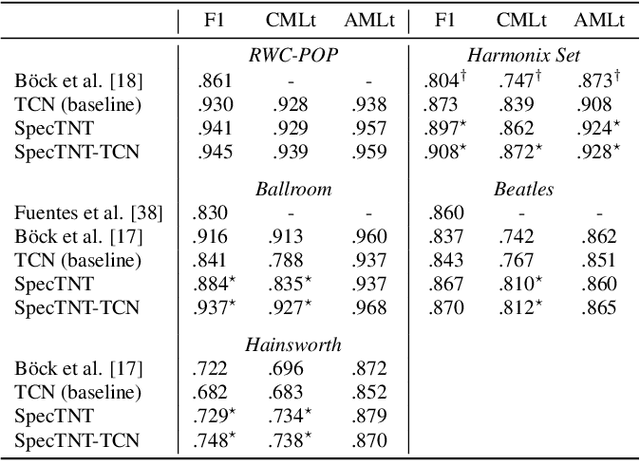
Transformer is a successful deep neural network (DNN) architecture that has shown its versatility not only in natural language processing but also in music information retrieval (MIR). In this paper, we present a novel Transformer-based approach to tackle beat and downbeat tracking. This approach employs SpecTNT (Spectral-Temporal Transformer in Transformer), a variant of Transformer that models both spectral and temporal dimensions of a time-frequency input of music audio. A SpecTNT model uses a stack of blocks, where each consists of two levels of Transformer encoders. The lower-level (or spectral) encoder handles the spectral features and enables the model to pay attention to harmonic components of each frame. Since downbeats indicate bar boundaries and are often accompanied by harmonic changes, this step may help downbeat modeling. The upper-level (or temporal) encoder aggregates useful local spectral information to pay attention to beat/downbeat positions. We also propose an architecture that combines SpecTNT with a state-of-the-art model, Temporal Convolutional Networks (TCN), to further improve the performance. Extensive experiments demonstrate that our approach can significantly outperform TCN in downbeat tracking while maintaining comparable result in beat tracking.
To catch a chorus, verse, intro, or anything else: Analyzing a song with structural functions
May 29, 2022
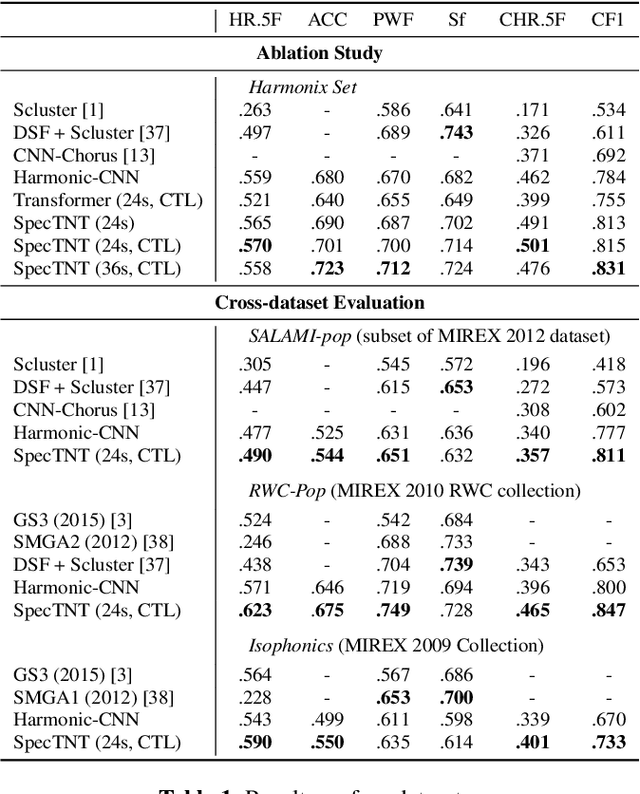
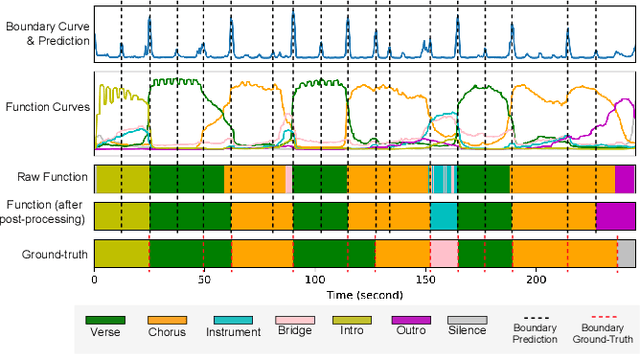
Conventional music structure analysis algorithms aim to divide a song into segments and to group them with abstract labels (e.g., 'A', 'B', and 'C'). However, explicitly identifying the function of each segment (e.g., 'verse' or 'chorus') is rarely attempted, but has many applications. We introduce a multi-task deep learning framework to model these structural semantic labels directly from audio by estimating "verseness," "chorusness," and so forth, as a function of time. We propose a 7-class taxonomy (i.e., intro, verse, chorus, bridge, outro, instrumental, and silence) and provide rules to consolidate annotations from four disparate datasets. We also propose to use a spectral-temporal Transformer-based model, called SpecTNT, which can be trained with an additional connectionist temporal localization (CTL) loss. In cross-dataset evaluations using four public datasets, we demonstrate the effectiveness of the SpecTNT model and CTL loss, and obtain strong results overall: the proposed system outperforms state-of-the-art chorus-detection and boundary-detection methods at detecting choruses and boundaries, respectively.