 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature-informed Embedding Space Regularization For Audio Classification
Paper and Code
Jun 10, 2022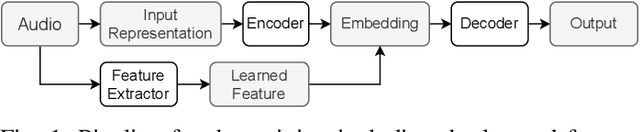
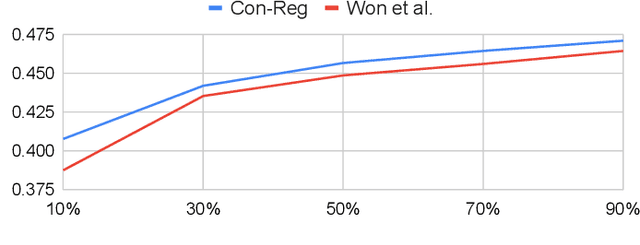
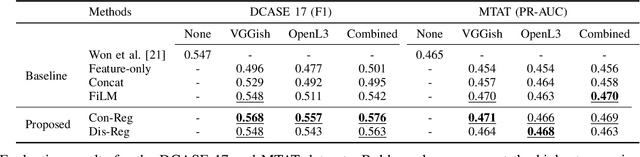
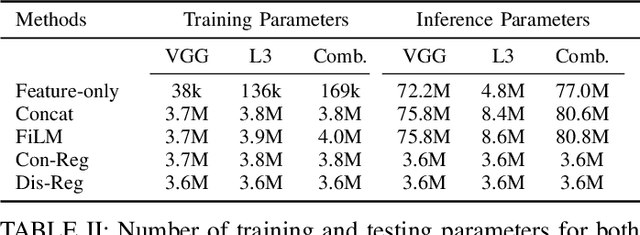
Feature representations derived from models pre-trained on large-scale datasets have shown their generalizability on a variety of audio analysis tasks. Despite this generalizability, however, task-specific features can outperform if sufficient training data is available, as specific task-relevant properties can be learned. Furthermore, the complex pre-trained models bring considerable computational burdens during inference. We propose to leverage both detailed task-specific features from spectrogram input and generic pre-trained features by introducing two regularization methods that integrate the information of both feature classes. The workload is kept low during inference as the pre-trained features are only necessary for training. In experiments with the pre-trained features VGGish, OpenL3, and a combination of both, we show that the proposed methods not only outperform baseline methods, but also can improve state-of-the-art models on several audio classification tasks. The results also suggest that using the mixture of features performs better than using individual features.