 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzable Chain-of-Musical-Thought Prompting for High-Fidelity Music Generation
Mar 25, 2025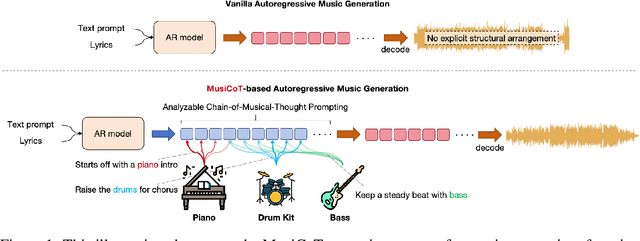
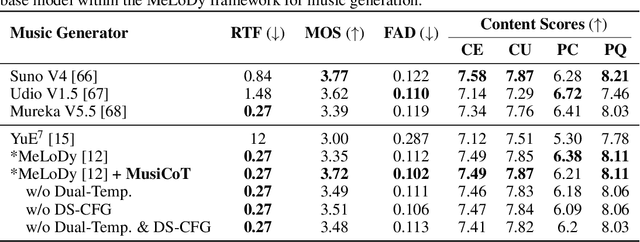
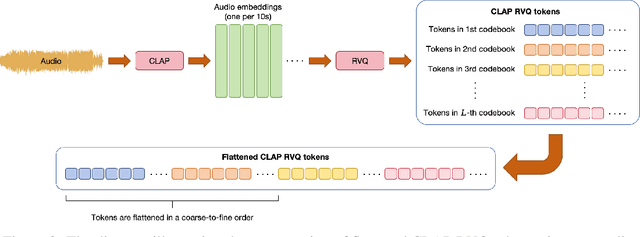
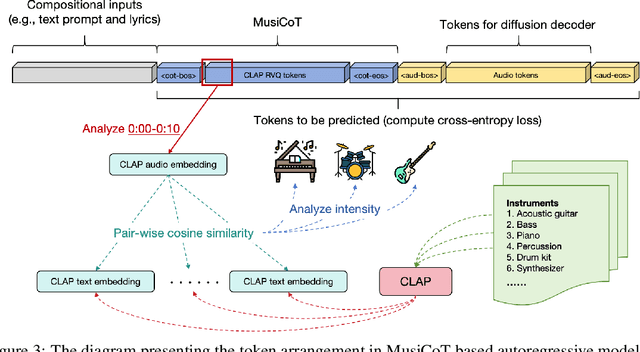
Autoregressive (AR) models have demonstrated impressive capabilities in generating high-fidelity music. However, the conventional next-token prediction paradigm in AR models does not align with the human creative process in music composition, potentially compromising the musicality of generated samples. To overcome this limitation, we introduce MusiCoT, a novel chain-of-thought (CoT) prompting technique tailored for music generation. MusiCoT empowers the AR model to first outline an overall music structure before generating audio tokens, thereby enhancing the coherence and creativity of the resulting compositions. By leveraging the contrastive language-audio pretraining (CLAP) model, we establish a chain of "musical thoughts", making MusiCoT scalable and independent of human-labeled data, in contrast to conventional CoT methods. Moreover, MusiCoT allows for in-depth analysis of music structure, such as instrumental arrangements, and supports music referencing -- accepting variable-length audio inputs as optional style references. This innovative approach effectively addresses copying issues, positioning MusiCoT as a vital practical method for music prompting. Our experimental results indicate that MusiCoT consistently achieves superior performance across both objective and subjective metrics, producing music quality that rivals state-of-the-art generation models. Our samples are available at https://MusiCoT.github.io/.
Seed-Music: A Unified Framework for High Quality and Controlled Music Generation
Sep 13, 2024



We introduce Seed-Music, a suite of music generation systems capable of producing high-quality music with fine-grained style control. Our unified framework leverages both auto-regressive language modeling and diffusion approaches to support two key music creation workflows: \textit{controlled music generation} and \textit{post-production editing}. For controlled music generation, our system enables vocal music generation with performance controls from multi-modal inputs, including style descriptions, audio references, musical scores, and voice prompts. For post-production editing, it offers interactive tools for editing lyrics and vocal melodies directly in the generated audio. We encourage readers to listen to demo audio examples at https://team.doubao.com/seed-music .
Mel-RoFormer for Vocal Separation and Vocal Melody Transcription
Sep 07, 2024



Developing a versatile deep neural network to model music audio is crucial in MIR. This task is challenging due to the intricate spectral variations inherent in music signals, which convey melody, harmonics, and timbres of diverse instruments. In this paper, we introduce Mel-RoFormer, a spectrogram-based model featuring two key designs: a novel Mel-band Projection module at the front-end to enhance the model's capability to capture informative features across multiple frequency bands, and interleaved RoPE Transformers to explicitly model the frequency and time dimensions as two separate sequences. We apply Mel-RoFormer to tackle two essential MIR tasks: vocal separation and vocal melody transcription, aimed at isolating singing voices from audio mixtures and transcribing their lead melodies, respectively. Despite their shared focus on singing signals, these tasks possess distinct optimization objectives. Instead of training a unified model, we adopt a two-step approach. Initially, we train a vocal separation model, which subsequently serves as a foundation model for fine-tuning for vocal melody transcription. Through extensive experiments conducted on benchmark datasets, we showcase that our models achieve state-of-the-art performance in both vocal separation and melody transcription tasks, underscoring the efficacy and versatility of Mel-RoFormer in modeling complex music audio signals.
Music Era Recognition Using Supervised Contrastive Learning and Artist Information
Jul 07, 2024Does popular music from the 60s sound different than that of the 90s? Prior study has shown that there would exist some variations of patterns and regularities related to instrumentation changes and growing loudness across multi-decadal trends. This indicates that perceiving the era of a song from musical features such as audio and artist information is possible. Music era information can be an important feature for playlist generation and recommendation. However, the release year of a song can be inaccessible in many circumstances. This paper addresses a novel task of music era recognition. We formulate the task as a music classification problem and propose solutions based on supervised contrastive learning. An audio-based model is developed to predict the era from audio. For the case where the artist information is available, we extend the audio-based model to take multimodal inputs and develop a framework, called MultiModal Contrastive (MMC) learning, to enhance the training. Experimental result on Million Song Dataset demonstrates that the audio-based model achieves 54% in accuracy with a tolerance of 3-years range; incorporating the artist information with the MMC framework for training leads to 9% improvement further.
Mel-Band RoFormer for Music Source Separation
Oct 03, 2023Recently, multi-band spectrogram-based approaches such as Band-Split RNN (BSRNN) have demonstrated promising results for music source separation. In our recent work, we introduce the BS-RoFormer model which inherits the idea of band-split scheme in BSRNN at the front-end, and then uses the hierarchical Transformer with Rotary Position Embedding (RoPE) to model the inner-band and inter-band sequences for multi-band mask estimation. This model has achieved state-of-the-art performance, but the band-split scheme is defined empirically, without analytic supports from the literature. In this paper, we propose Mel-RoFormer, which adopts the Mel-band scheme that maps the frequency bins into overlapped subbands according to the mel scale. In contract, the band-split mapping in BSRNN and BS-RoFormer is non-overlapping and designed based on heuristics. Using the MUSDB18HQ dataset for experiments, we demonstrate that Mel-RoFormer outperforms BS-RoFormer in the separation tasks of vocals, drums, and other stems.
Music Source Separation with Band-Split RoPE Transformer
Sep 10, 2023Music source separation (MSS) aims to separate a music recording into multiple musically distinct stems, such as vocals, bass, drums, and more. Recently, deep learning approaches such as convolutional neural networks (CNNs) and recurrent neural networks (RNNs) have been used, but the improvement is still limited. In this paper, we propose a novel frequency-domain approach based on a Band-Split RoPE Transformer (called BS-RoFormer). BS-RoFormer relies on a band-split module to project the input complex spectrogram into subband-level representations, and then arranges a stack of hierarchical Transformers to model the inner-band as well as inter-band sequences for multi-band mask estimation. To facilitate training the model for MSS, we propose to use the Rotary Position Embedding (RoPE). The BS-RoFormer system trained on MUSDB18HQ and 500 extra songs ranked the first place in the MSS track of Sound Demixing Challenge (SDX23). Benchmarking a smaller version of BS-RoFormer on MUSDB18HQ, we achieve state-of-the-art result without extra training data, with 9.80 dB of average SDR.
Multitrack Music Transcription with a Time-Frequency Perceiver
Jun 19, 2023


Multitrack music transcription aims to transcribe a music audio input into the musical notes of multiple instruments simultaneously. It is a very challenging task that typically requires a more complex model to achieve satisfactory result. In addition, prior works mostly focus on transcriptions of regular instruments, however, neglecting vocals, which are usually the most important signal source if present in a piece of music. In this paper, we propose a novel deep neural network architecture, Perceiver TF, to model the time-frequency representation of audio input for multitrack transcription. Perceiver TF augments the Perceiver architecture by introducing a hierarchical expansion with an additional Transformer layer to model temporal coherence. Accordingly, our model inherits the benefits of Perceiver that posses better scalability, allowing it to well handle transcriptions of many instruments in a single model. In experiments, we train a Perceiver TF to model 12 instrument classes as well as vocal in a multi-task learning manner. Our result demonstrates that the proposed system outperforms the state-of-the-art counterparts (e.g., MT3 and SpecTNT) on various public datasets.
Modeling Beats and Downbeats with a Time-Frequency Transformer
May 29, 2022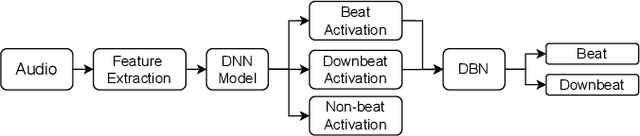
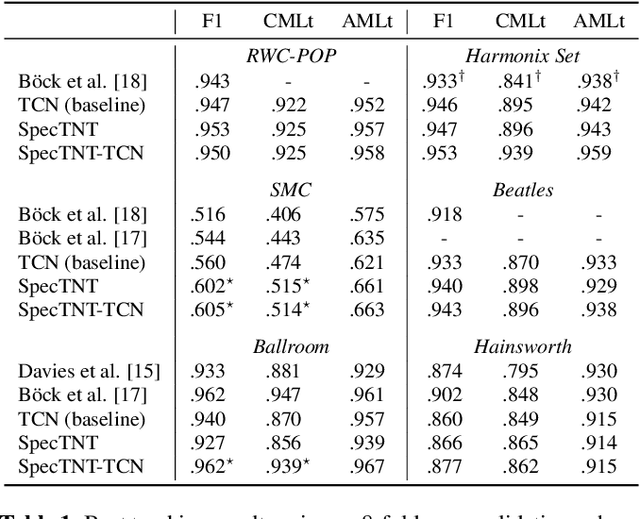
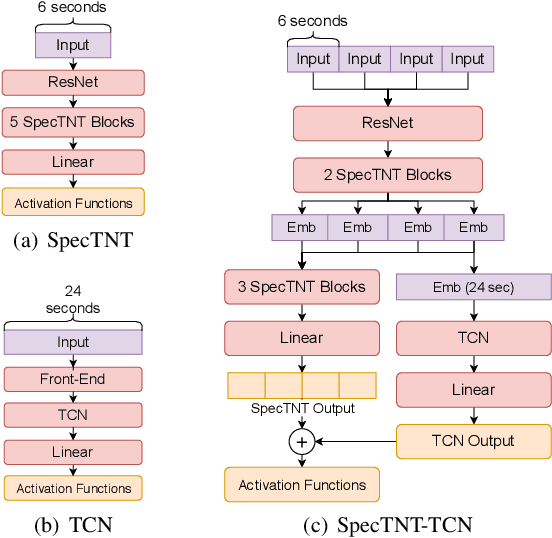
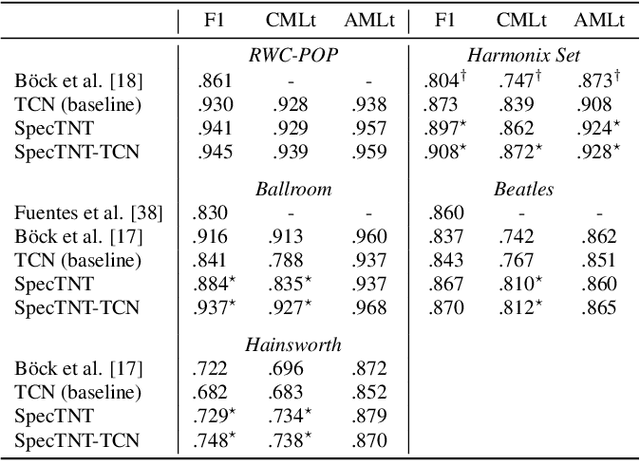
Transformer is a successful deep neural network (DNN) architecture that has shown its versatility not only in natural language processing but also in music information retrieval (MIR). In this paper, we present a novel Transformer-based approach to tackle beat and downbeat tracking. This approach employs SpecTNT (Spectral-Temporal Transformer in Transformer), a variant of Transformer that models both spectral and temporal dimensions of a time-frequency input of music audio. A SpecTNT model uses a stack of blocks, where each consists of two levels of Transformer encoders. The lower-level (or spectral) encoder handles the spectral features and enables the model to pay attention to harmonic components of each frame. Since downbeats indicate bar boundaries and are often accompanied by harmonic changes, this step may help downbeat modeling. The upper-level (or temporal) encoder aggregates useful local spectral information to pay attention to beat/downbeat positions. We also propose an architecture that combines SpecTNT with a state-of-the-art model, Temporal Convolutional Networks (TCN), to further improve the performance. Extensive experiments demonstrate that our approach can significantly outperform TCN in downbeat tracking while maintaining comparable result in beat tracking.
Actions Speak Louder than Listening: Evaluating Music Style Transfer based on Editing Experience
Oct 25, 2021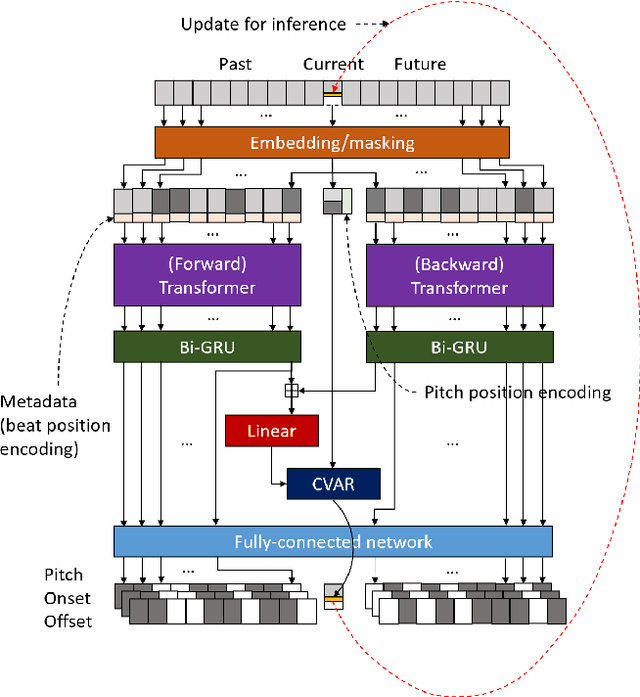

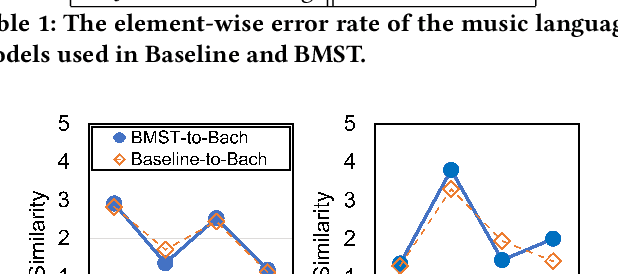
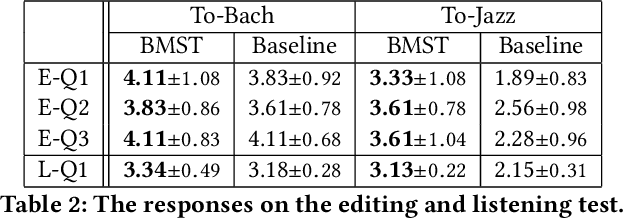
The subjective evaluation of music generation techniques has been mostly done with questionnaire-based listening tests while ignoring the perspectives from music composition, arrangement, and soundtrack editing. In this paper, we propose an editing test to evaluate users' editing experience of music generation models in a systematic way. To do this, we design a new music style transfer model combining the non-chronological inference architecture, autoregressive models and the Transformer, which serves as an improvement from the baseline model on the same style transfer task. Then, we compare the performance of the two models with a conventional listening test and the proposed editing test, in which the quality of generated samples is assessed by the amount of effort (e.g., the number of required keyboard and mouse actions) spent by users to polish a music clip. Results on two target styles indicate that the improvement over the baseline model can be reflected by the editing test quantitatively. Also, the editing test provides profound insights which are not accessible from usual listening tests. The major contribution of this paper is the systematic presentation of the editing test and the corresponding insights, while the proposed music style transfer model based on state-of-the-art neural networks represents another contribution.
SpecTNT: a Time-Frequency Transformer for Music Audio
Oct 18, 2021

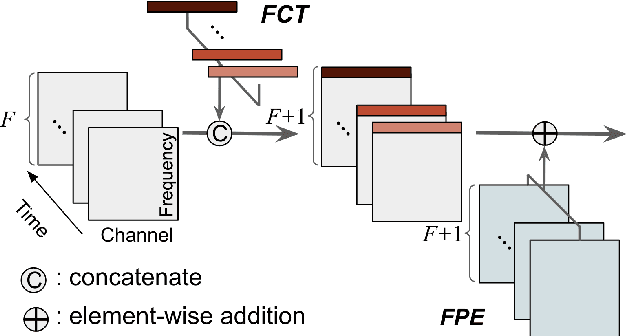
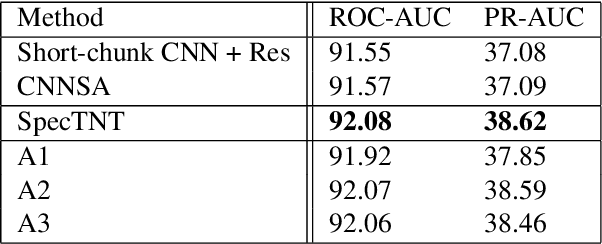
Transformers have drawn attention in the MIR field for their remarkable performance shown in natural language processing and computer vision. However, prior works in the audio processing domain mostly use Transformer as a temporal feature aggregator that acts similar to RNNs. In this paper, we propose SpecTNT, a Transformer-based architecture to model both spectral and temporal sequences of an input time-frequency representation. Specifically, we introduce a novel variant of the Transformer-in-Transformer (TNT) architecture. In each SpecTNT block, a spectral Transformer extracts frequency-related features into the frequency class token (FCT) for each frame. Later, the FCTs are linearly projected and added to the temporal embeddings (TEs), which aggregate useful information from the FCTs. Then, a temporal Transformer processes the TEs to exchange information across the time axis. By stacking the SpecTNT blocks, we build the SpecTNT model to learn the representation for music signals. In experiments, SpecTNT demonstrates state-of-the-art performance in music tagging and vocal melody extraction, and shows competitive performance for chord recognition. The effectiveness of SpecTNT and other design choices are further examined through ablation studies.
* 6 pages