 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzable Chain-of-Musical-Thought Prompting for High-Fidelity Music Generation
Mar 25, 2025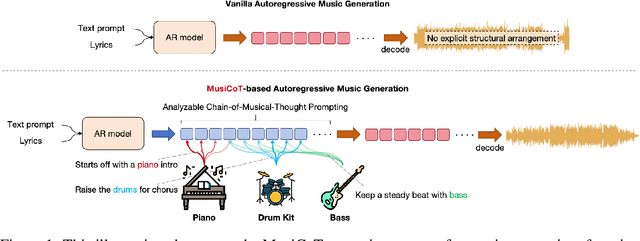
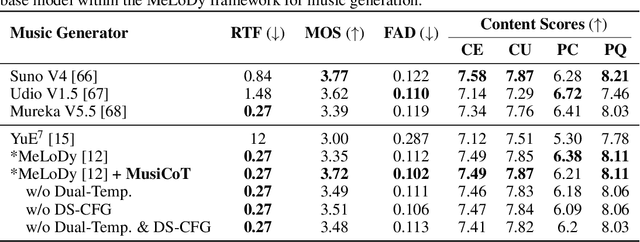
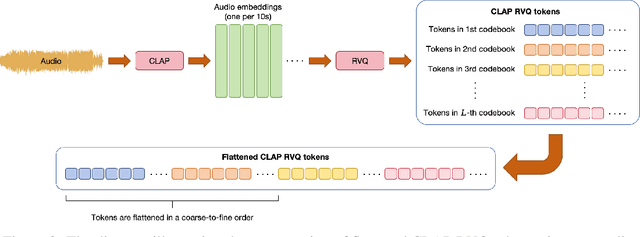
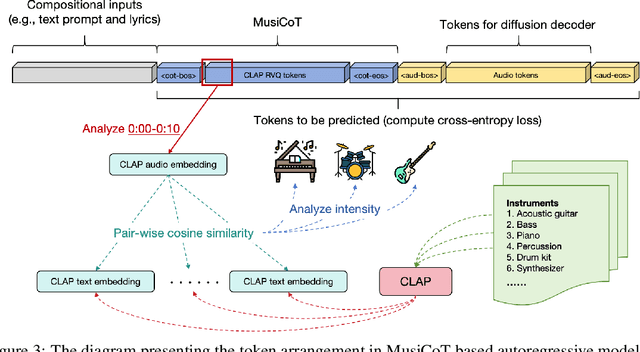
Autoregressive (AR) models have demonstrated impressive capabilities in generating high-fidelity music. However, the conventional next-token prediction paradigm in AR models does not align with the human creative process in music composition, potentially compromising the musicality of generated samples. To overcome this limitation, we introduce MusiCoT, a novel chain-of-thought (CoT) prompting technique tailored for music generation. MusiCoT empowers the AR model to first outline an overall music structure before generating audio tokens, thereby enhancing the coherence and creativity of the resulting compositions. By leveraging the contrastive language-audio pretraining (CLAP) model, we establish a chain of "musical thoughts", making MusiCoT scalable and independent of human-labeled data, in contrast to conventional CoT methods. Moreover, MusiCoT allows for in-depth analysis of music structure, such as instrumental arrangements, and supports music referencing -- accepting variable-length audio inputs as optional style references. This innovative approach effectively addresses copying issues, positioning MusiCoT as a vital practical method for music prompting. Our experimental results indicate that MusiCoT consistently achieves superior performance across both objective and subjective metrics, producing music quality that rivals state-of-the-art generation models. Our samples are available at https://MusiCoT.github.io/.
Fish-Speech: Leveraging Large Language Models for Advanced Multilingual Text-to-Speech Synthesis
Nov 02, 2024



Text-to-Speech (TTS) systems face ongoing challenges in processing complex linguistic features, handling polyphonic expressions, and producing natural-sounding multilingual speech - capabilities that are crucial for future AI applications. In this paper, we present Fish-Speech, a novel framework that implements a serial fast-slow Dual Autoregressive (Dual-AR) architecture to enhance the stability of Grouped Finite Scalar Vector Quantization (GFSQ) in sequence generation tasks. This architecture improves codebook processing efficiency while maintaining high-fidelity outputs, making it particularly effective for AI interactions and voice cloning. Fish-Speech leverages Large Language Models (LLMs) for linguistic feature extraction, eliminating the need for traditional grapheme-to-phoneme (G2P) conversion and thereby streamlining the synthesis pipeline and enhancing multilingual support. Additionally, we developed FF-GAN through GFSQ to achieve superior compression ratios and near 100\% codebook utilization. Our approach addresses key limitations of current TTS systems while providing a foundation for more sophisticated, context-aware speech synthesis. Experimental results show that Fish-Speech significantly outperforms baseline models in handling complex linguistic scenarios and voice cloning tasks, demonstrating its potential to advance TTS technology in AI applications. The implementation is open source at \href{https://github.com/fishaudio/fish-speech}{https://github.com/fishaudio/fish-speech}.