 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMusic Era Recognition Using Supervised Contrastive Learning and Artist Information
Jul 07, 2024Does popular music from the 60s sound different than that of the 90s? Prior study has shown that there would exist some variations of patterns and regularities related to instrumentation changes and growing loudness across multi-decadal trends. This indicates that perceiving the era of a song from musical features such as audio and artist information is possible. Music era information can be an important feature for playlist generation and recommendation. However, the release year of a song can be inaccessible in many circumstances. This paper addresses a novel task of music era recognition. We formulate the task as a music classification problem and propose solutions based on supervised contrastive learning. An audio-based model is developed to predict the era from audio. For the case where the artist information is available, we extend the audio-based model to take multimodal inputs and develop a framework, called MultiModal Contrastive (MMC) learning, to enhance the training. Experimental result on Million Song Dataset demonstrates that the audio-based model achieves 54% in accuracy with a tolerance of 3-years range; incorporating the artist information with the MMC framework for training leads to 9% improvement further.
DEEPCHORUS: A Hybrid Model of Multi-scale Convolution and Self-attention for Chorus Detection
Feb 13, 2022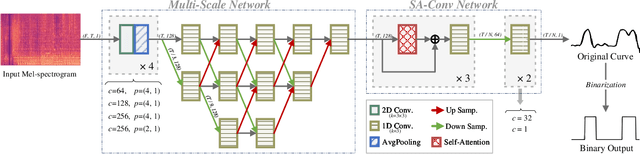
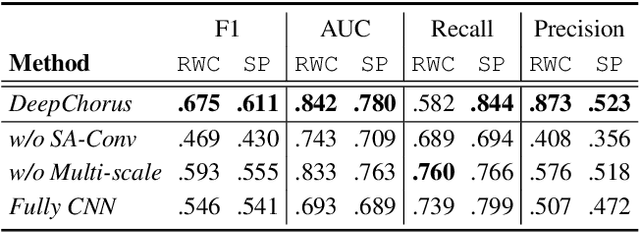
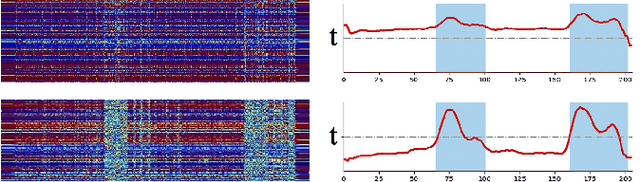

Chorus detection is a challenging problem in musical signal processing as the chorus often repeats more than once in popular songs, usually with rich instruments and complex rhythm forms. Most of the existing works focus on the receptiveness of chorus sections based on some explicit features such as loudness and occurrence frequency. These pre-assumptions for chorus limit the generalization capacity of these methods, causing misdetection on other repeated sections such as verse. To solve the problem, in this paper we propose an end-to-end chorus detection model DeepChorus, reducing the engineering effort and the need for prior knowledge. The proposed model includes two main structures: i) a Multi-Scale Network to derive preliminary representations of chorus segments, and ii) a Self-Attention Convolution Network to further process the features into probability curves representing chorus presence. To obtain the final results, we apply an adaptive threshold to binarize the original curve. The experimental results show that DeepChorus outperforms existing state-of-the-art methods in most cases.
Musical Tempo Estimation Using a Multi-scale Network
Sep 03, 2021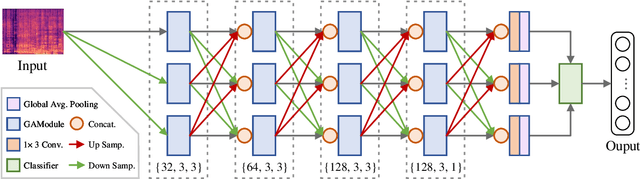

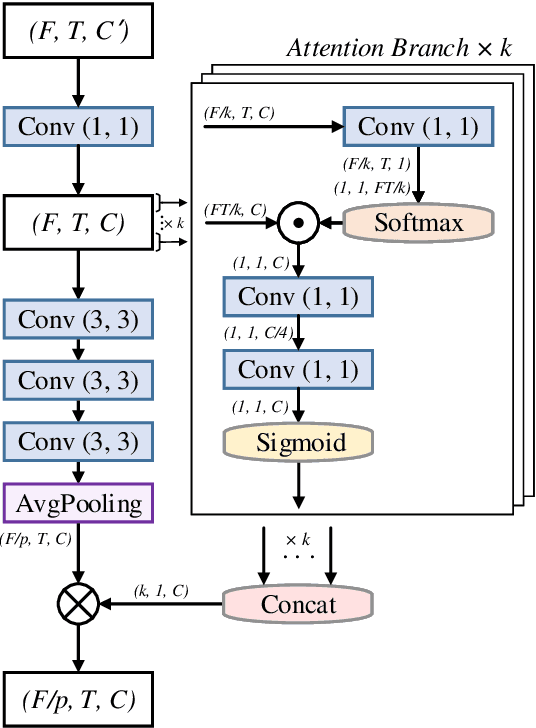
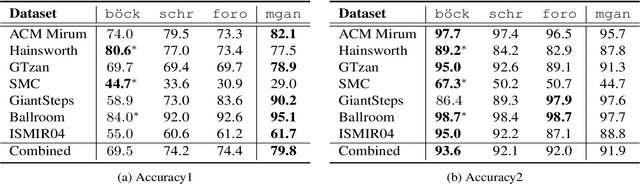
Recently, some single-step systems without onset detection have shown their effectiveness in automatic musical tempo estimation. Following the success of these systems, in this paper we propose a Multi-scale Grouped Attention Network to further explore the potential of such methods. A multi-scale structure is introduced as the overall network architecture where information from different scales is aggregated to strengthen contextual feature learning. Furthermore, we propose a Grouped Attention Module as the key component of the network. The proposed module separates the input feature into several groups along the frequency axis, which makes it capable of capturing long-range dependencies from different frequency positions on the spectrogram. In comparison experiments, the results on public datasets show that the proposed model outperforms existing state-of-the-art methods on Accuracy1.