 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvery Image Listens, Every Image Dances: Music-Driven Image Animation
Jan 30, 2025



Image animation has become a promising area in multimodal research, with a focus on generating videos from reference images. While prior work has largely emphasized generic video generation guided by text, music-driven dance video generation remains underexplored. In this paper, we introduce MuseDance, an innovative end-to-end model that animates reference images using both music and text inputs. This dual input enables MuseDance to generate personalized videos that follow text descriptions and synchronize character movements with the music. Unlike existing approaches, MuseDance eliminates the need for complex motion guidance inputs, such as pose or depth sequences, making flexible and creative video generation accessible to users of all expertise levels. To advance research in this field, we present a new multimodal dataset comprising 2,904 dance videos with corresponding background music and text descriptions. Our approach leverages diffusion-based methods to achieve robust generalization, precise control, and temporal consistency, setting a new baseline for the music-driven image animation task.
Seed-Music: A Unified Framework for High Quality and Controlled Music Generation
Sep 13, 2024



We introduce Seed-Music, a suite of music generation systems capable of producing high-quality music with fine-grained style control. Our unified framework leverages both auto-regressive language modeling and diffusion approaches to support two key music creation workflows: \textit{controlled music generation} and \textit{post-production editing}. For controlled music generation, our system enables vocal music generation with performance controls from multi-modal inputs, including style descriptions, audio references, musical scores, and voice prompts. For post-production editing, it offers interactive tools for editing lyrics and vocal melodies directly in the generated audio. We encourage readers to listen to demo audio examples at https://team.doubao.com/seed-music .
Music Era Recognition Using Supervised Contrastive Learning and Artist Information
Jul 07, 2024Does popular music from the 60s sound different than that of the 90s? Prior study has shown that there would exist some variations of patterns and regularities related to instrumentation changes and growing loudness across multi-decadal trends. This indicates that perceiving the era of a song from musical features such as audio and artist information is possible. Music era information can be an important feature for playlist generation and recommendation. However, the release year of a song can be inaccessible in many circumstances. This paper addresses a novel task of music era recognition. We formulate the task as a music classification problem and propose solutions based on supervised contrastive learning. An audio-based model is developed to predict the era from audio. For the case where the artist information is available, we extend the audio-based model to take multimodal inputs and develop a framework, called MultiModal Contrastive (MMC) learning, to enhance the training. Experimental result on Million Song Dataset demonstrates that the audio-based model achieves 54% in accuracy with a tolerance of 3-years range; incorporating the artist information with the MMC framework for training leads to 9% improvement further.
InstructME: An Instruction Guided Music Edit And Remix Framework with Latent Diffusion Models
Sep 06, 2023Music editing primarily entails the modification of instrument tracks or remixing in the whole, which offers a novel reinterpretation of the original piece through a series of operations. These music processing methods hold immense potential across various applications but demand substantial expertise. Prior methodologies, although effective for image and audio modifications, falter when directly applied to music. This is attributed to music's distinctive data nature, where such methods can inadvertently compromise the intrinsic harmony and coherence of music. In this paper, we develop InstructME, an Instruction guided Music Editing and remixing framework based on latent diffusion models. Our framework fortifies the U-Net with multi-scale aggregation in order to maintain consistency before and after editing. In addition, we introduce chord progression matrix as condition information and incorporate it in the semantic space to improve melodic harmony while editing. For accommodating extended musical pieces, InstructME employs a chunk transformer, enabling it to discern long-term temporal dependencies within music sequences. We tested InstructME in instrument-editing, remixing, and multi-round editing. Both subjective and objective evaluations indicate that our proposed method significantly surpasses preceding systems in music quality, text relevance and harmony. Demo samples are available at https://musicedit.github.io/
RECAP: Retrieval Augmented Music Captioner
Dec 21, 2022



With the prevalence of stream media platforms serving music search and recommendation, interpreting music by understanding audio and lyrics interactively has become an important and challenging task. However, many previous works focus on refining individual components of encoder-decoder architecture mapping music to caption tokens, ignoring the potential usage of audio and lyrics correspondence. In this paper, we propose to explicitly learn the multi-modal alignment with retrieval augmentation by contrastive learning. By learning audio-lyrics correspondence, the model is guided to learn better cross-modal attention weights, thus generating high-quality caption words. We provide both theoretical and empirical results that demonstrate the advantage of the proposed method.
Towards Fair Federated Learning with Zero-Shot Data Augmentation
Apr 27, 2021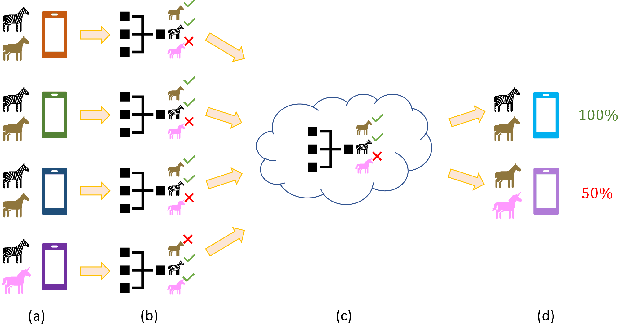
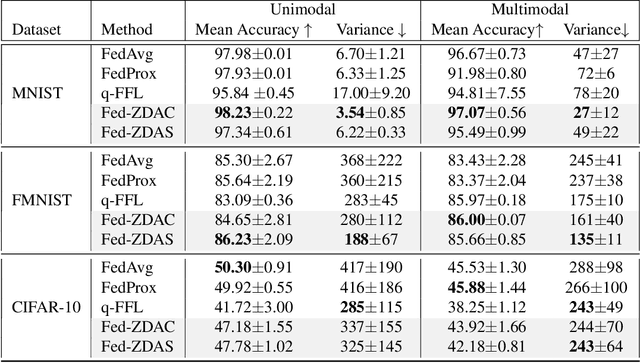
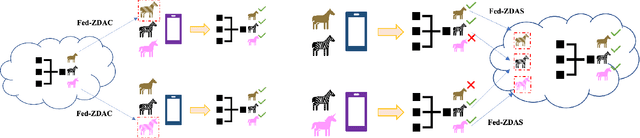
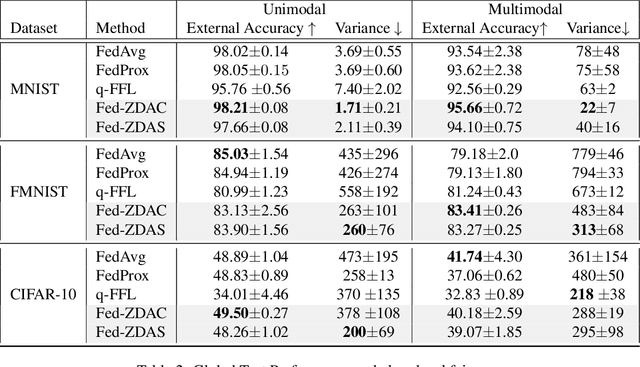
Federated learning has emerged as an important distributed learning paradigm, where a server aggregates a global model from many client-trained models while having no access to the client data. Although it is recognized that statistical heterogeneity of the client local data yields slower global model convergence, it is less commonly recognized that it also yields a biased federated global model with a high variance of accuracy across clients. In this work, we aim to provide federated learning schemes with improved fairness. To tackle this challenge, we propose a novel federated learning system that employs zero-shot data augmentation on under-represented data to mitigate statistical heterogeneity and encourage more uniform accuracy performance across clients in federated networks. We study two variants of this scheme, Fed-ZDAC (federated learning with zero-shot data augmentation at the clients) and Fed-ZDAS (federated learning with zero-shot data augmentation at the server). Empirical results on a suite of datasets demonstrate the effectiveness of our methods on simultaneously improving the test accuracy and fairness.
Improving Zero-shot Voice Style Transfer via Disentangled Representation Learning
Mar 17, 2021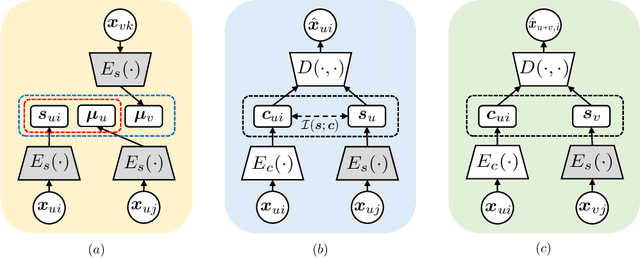


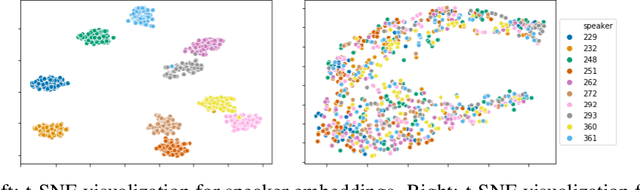
Voice style transfer, also called voice conversion, seeks to modify one speaker's voice to generate speech as if it came from another (target) speaker. Previous works have made progress on voice conversion with parallel training data and pre-known speakers. However, zero-shot voice style transfer, which learns from non-parallel data and generates voices for previously unseen speakers, remains a challenging problem. We propose a novel zero-shot voice transfer method via disentangled representation learning. The proposed method first encodes speaker-related style and voice content of each input voice into separated low-dimensional embedding spaces, and then transfers to a new voice by combining the source content embedding and target style embedding through a decoder. With information-theoretic guidance, the style and content embedding spaces are representative and (ideally) independent of each other. On real-world VCTK datasets, our method outperforms other baselines and obtains state-of-the-art results in terms of transfer accuracy and voice naturalness for voice style transfer experiments under both many-to-many and zero-shot setups.
FairFil: Contrastive Neural Debiasing Method for Pretrained Text Encoders
Mar 11, 2021
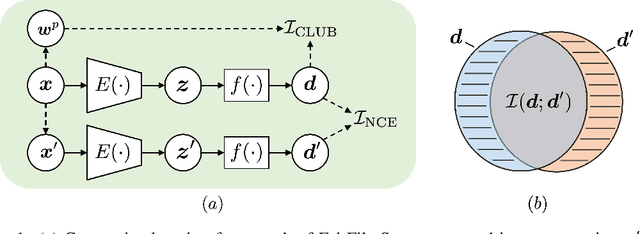
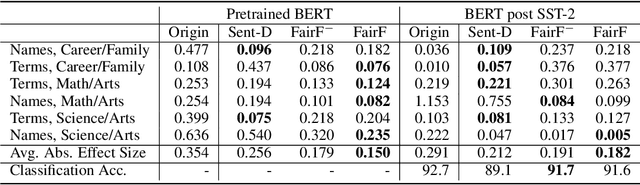
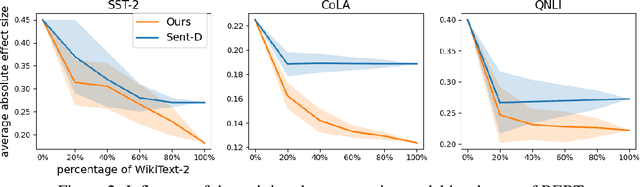
Pretrained text encoders, such as BERT, have been applied increasingly in various natural language processing (NLP) tasks, and have recently demonstrated significant performance gains. However, recent studies have demonstrated the existence of social bias in these pretrained NLP models. Although prior works have made progress on word-level debiasing, improved sentence-level fairness of pretrained encoders still lacks exploration. In this paper, we proposed the first neural debiasing method for a pretrained sentence encoder, which transforms the pretrained encoder outputs into debiased representations via a fair filter (FairFil) network. To learn the FairFil, we introduce a contrastive learning framework that not only minimizes the correlation between filtered embeddings and bias words but also preserves rich semantic information of the original sentences. On real-world datasets, our FairFil effectively reduces the bias degree of pretrained text encoders, while continuously showing desirable performance on downstream tasks. Moreover, our post-hoc method does not require any retraining of the text encoders, further enlarging FairFil's application space.
FLOP: Federated Learning on Medical Datasets using Partial Networks
Feb 10, 2021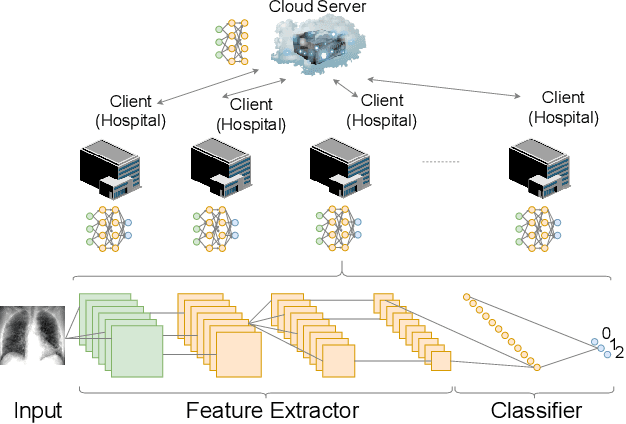
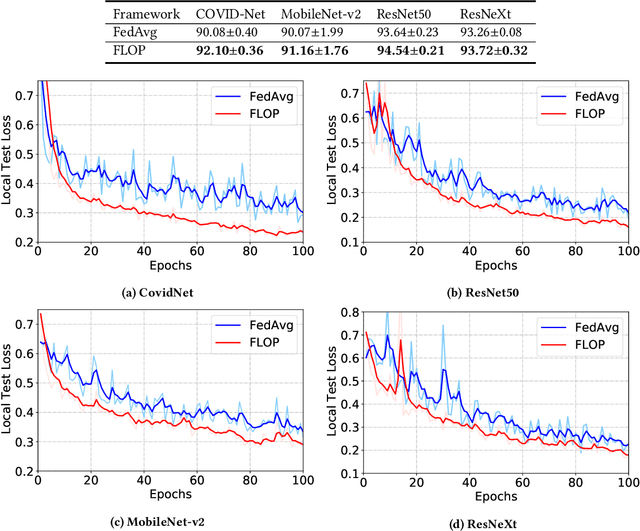
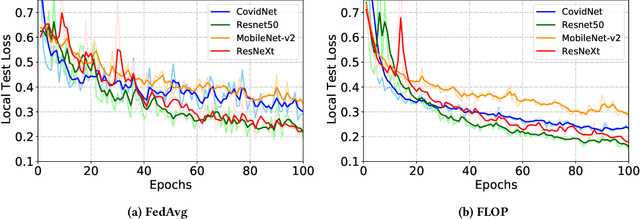

The outbreak of COVID-19 Disease due to the novel coronavirus has caused a shortage of medical resources. To aid and accelerate the diagnosis process, automatic diagnosis of COVID-19 via deep learning models has recently been explored by researchers across the world. While different data-driven deep learning models have been developed to mitigate the diagnosis of COVID-19, the data itself is still scarce due to patient privacy concerns. Federated Learning (FL) is a natural solution because it allows different organizations to cooperatively learn an effective deep learning model without sharing raw data. However, recent studies show that FL still lacks privacy protection and may cause data leakage. We investigate this challenging problem by proposing a simple yet effective algorithm, named \textbf{F}ederated \textbf{L}earning \textbf{o}n Medical Datasets using \textbf{P}artial Networks (FLOP), that shares only a partial model between the server and clients. Extensive experiments on benchmark data and real-world healthcare tasks show that our approach achieves comparable or better performance while reducing the privacy and security risks. Of particular interest, we conduct experiments on the COVID-19 dataset and find that our FLOP algorithm can allow different hospitals to collaboratively and effectively train a partially shared model without sharing local patients' data.
MixKD: Towards Efficient Distillation of Large-scale Language Models
Nov 01, 2020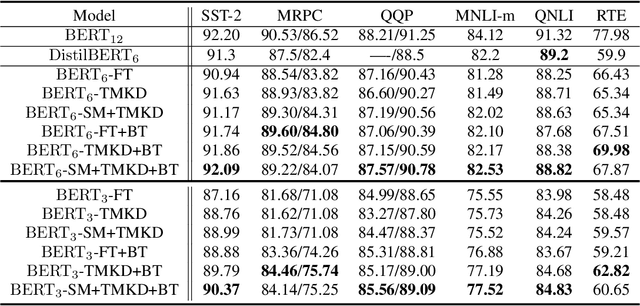
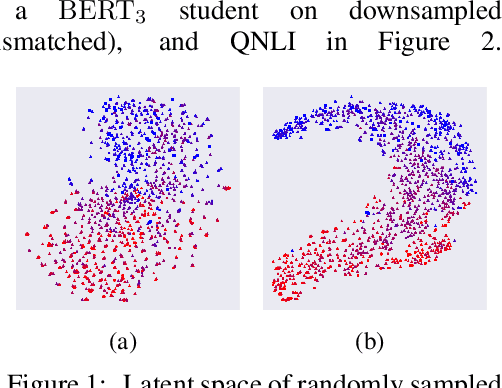
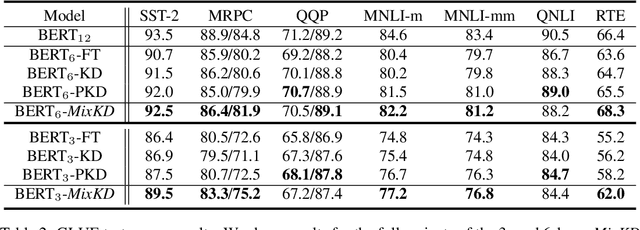
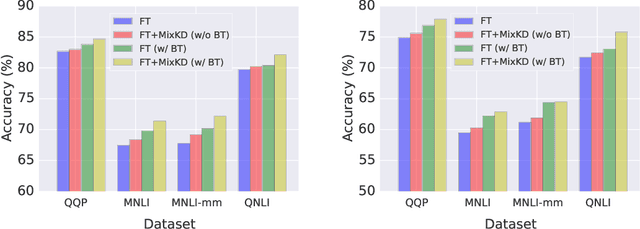
Large-scale language models have recently demonstrated impressive empirical performance. Nevertheless, the improved results are attained at the price of bigger models, more power consumption, and slower inference, which hinder their applicability to low-resource (memory and computation) platforms. Knowledge distillation (KD) has been demonstrated as an effective framework for compressing such big models. However, large-scale neural network systems are prone to memorize training instances, and thus tend to make inconsistent predictions when the data distribution is altered slightly. Moreover, the student model has few opportunities to request useful information from the teacher model when there is limited task-specific data available. To address these issues, we propose MixKD, a data-agnostic distillation framework that leverages mixup, a simple yet efficient data augmentation approach, to endow the resulting model with stronger generalization ability. Concretely, in addition to the original training examples, the student model is encouraged to mimic the teacher's behavior on the linear interpolation of example pairs as well. We prove, from a theoretical perspective, that under reasonable conditions MixKD gives rise to a smaller gap between the generalization error and the empirical error. To verify its effectiveness, we conduct experiments on the GLUE benchmark, where MixKD consistently leads to significant gains over the standard KD training, and outperforms several competitive baselines. Experiments under a limited-data setting and ablation studies further demonstrate the advantages of the proposed approach.