 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Adaptation of Pre-trained Foundation Models for Music Structure Analysis
Jul 17, 2025



Audio-based music structure analysis (MSA) is an essential task in Music Information Retrieval that remains challenging due to the complexity and variability of musical form. Recent advances highlight the potential of fine-tuning pre-trained music foundation models for MSA tasks. However, these models are typically trained with high temporal feature resolution and short audio windows, which limits their efficiency and introduces bias when applied to long-form audio. This paper presents a temporal adaptation approach for fine-tuning music foundation models tailored to MSA. Our method enables efficient analysis of full-length songs in a single forward pass by incorporating two key strategies: (1) audio window extension and (2) low-resolution adaptation. Experiments on the Harmonix Set and RWC-Pop datasets show that our method significantly improves both boundary detection and structural function prediction, while maintaining comparable memory usage and inference speed.
Every Image Listens, Every Image Dances: Music-Driven Image Animation
Jan 30, 2025



Image animation has become a promising area in multimodal research, with a focus on generating videos from reference images. While prior work has largely emphasized generic video generation guided by text, music-driven dance video generation remains underexplored. In this paper, we introduce MuseDance, an innovative end-to-end model that animates reference images using both music and text inputs. This dual input enables MuseDance to generate personalized videos that follow text descriptions and synchronize character movements with the music. Unlike existing approaches, MuseDance eliminates the need for complex motion guidance inputs, such as pose or depth sequences, making flexible and creative video generation accessible to users of all expertise levels. To advance research in this field, we present a new multimodal dataset comprising 2,904 dance videos with corresponding background music and text descriptions. Our approach leverages diffusion-based methods to achieve robust generalization, precise control, and temporal consistency, setting a new baseline for the music-driven image animation task.
Seed-Music: A Unified Framework for High Quality and Controlled Music Generation
Sep 13, 2024



We introduce Seed-Music, a suite of music generation systems capable of producing high-quality music with fine-grained style control. Our unified framework leverages both auto-regressive language modeling and diffusion approaches to support two key music creation workflows: \textit{controlled music generation} and \textit{post-production editing}. For controlled music generation, our system enables vocal music generation with performance controls from multi-modal inputs, including style descriptions, audio references, musical scores, and voice prompts. For post-production editing, it offers interactive tools for editing lyrics and vocal melodies directly in the generated audio. We encourage readers to listen to demo audio examples at https://team.doubao.com/seed-music .
Mel-RoFormer for Vocal Separation and Vocal Melody Transcription
Sep 07, 2024



Developing a versatile deep neural network to model music audio is crucial in MIR. This task is challenging due to the intricate spectral variations inherent in music signals, which convey melody, harmonics, and timbres of diverse instruments. In this paper, we introduce Mel-RoFormer, a spectrogram-based model featuring two key designs: a novel Mel-band Projection module at the front-end to enhance the model's capability to capture informative features across multiple frequency bands, and interleaved RoPE Transformers to explicitly model the frequency and time dimensions as two separate sequences. We apply Mel-RoFormer to tackle two essential MIR tasks: vocal separation and vocal melody transcription, aimed at isolating singing voices from audio mixtures and transcribing their lead melodies, respectively. Despite their shared focus on singing signals, these tasks possess distinct optimization objectives. Instead of training a unified model, we adopt a two-step approach. Initially, we train a vocal separation model, which subsequently serves as a foundation model for fine-tuning for vocal melody transcription. Through extensive experiments conducted on benchmark datasets, we showcase that our models achieve state-of-the-art performance in both vocal separation and melody transcription tasks, underscoring the efficacy and versatility of Mel-RoFormer in modeling complex music audio signals.
SymPAC: Scalable Symbolic Music Generation With Prompts And Constraints
Sep 04, 2024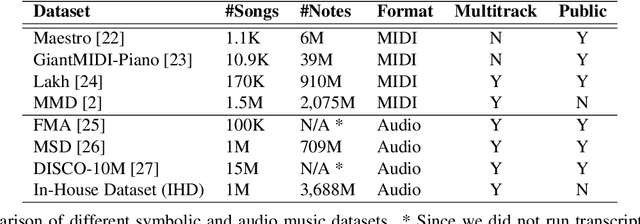


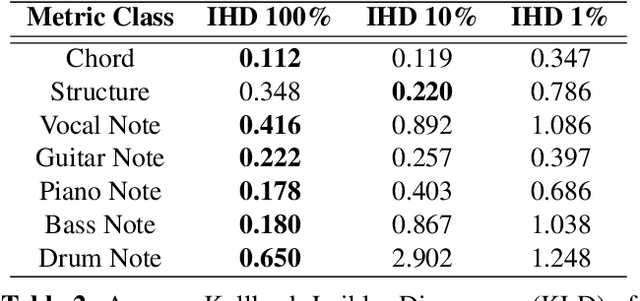
Progress in the task of symbolic music generation may be lagging behind other tasks like audio and text generation, in part because of the scarcity of symbolic training data. In this paper, we leverage the greater scale of audio music data by applying pre-trained MIR models (for transcription, beat tracking, structure analysis, etc.) to extract symbolic events and encode them into token sequences. To the best of our knowledge, this work is the first to demonstrate the feasibility of training symbolic generation models solely from auto-transcribed audio data. Furthermore, to enhance the controllability of the trained model, we introduce SymPAC (Symbolic Music Language Model with Prompting And Constrained Generation), which is distinguished by using (a) prompt bars in encoding and (b) a technique called Constrained Generation via Finite State Machines (FSMs) during inference time. We show the flexibility and controllability of this approach, which may be critical in making music AI useful to creators and users.
Music Era Recognition Using Supervised Contrastive Learning and Artist Information
Jul 07, 2024Does popular music from the 60s sound different than that of the 90s? Prior study has shown that there would exist some variations of patterns and regularities related to instrumentation changes and growing loudness across multi-decadal trends. This indicates that perceiving the era of a song from musical features such as audio and artist information is possible. Music era information can be an important feature for playlist generation and recommendation. However, the release year of a song can be inaccessible in many circumstances. This paper addresses a novel task of music era recognition. We formulate the task as a music classification problem and propose solutions based on supervised contrastive learning. An audio-based model is developed to predict the era from audio. For the case where the artist information is available, we extend the audio-based model to take multimodal inputs and develop a framework, called MultiModal Contrastive (MMC) learning, to enhance the training. Experimental result on Million Song Dataset demonstrates that the audio-based model achieves 54% in accuracy with a tolerance of 3-years range; incorporating the artist information with the MMC framework for training leads to 9% improvement further.
StemGen: A music generation model that listens
Dec 14, 2023

End-to-end generation of musical audio using deep learning techniques has seen an explosion of activity recently. However, most models concentrate on generating fully mixed music in response to abstract conditioning information. In this work, we present an alternative paradigm for producing music generation models that can listen and respond to musical context. We describe how such a model can be constructed using a non-autoregressive, transformer-based model architecture and present a number of novel architectural and sampling improvements. We train the described architecture on both an open-source and a proprietary dataset. We evaluate the produced models using standard quality metrics and a new approach based on music information retrieval descriptors. The resulting model reaches the audio quality of state-of-the-art text-conditioned models, as well as exhibiting strong musical coherence with its context.
Mel-Band RoFormer for Music Source Separation
Oct 03, 2023Recently, multi-band spectrogram-based approaches such as Band-Split RNN (BSRNN) have demonstrated promising results for music source separation. In our recent work, we introduce the BS-RoFormer model which inherits the idea of band-split scheme in BSRNN at the front-end, and then uses the hierarchical Transformer with Rotary Position Embedding (RoPE) to model the inner-band and inter-band sequences for multi-band mask estimation. This model has achieved state-of-the-art performance, but the band-split scheme is defined empirically, without analytic supports from the literature. In this paper, we propose Mel-RoFormer, which adopts the Mel-band scheme that maps the frequency bins into overlapped subbands according to the mel scale. In contract, the band-split mapping in BSRNN and BS-RoFormer is non-overlapping and designed based on heuristics. Using the MUSDB18HQ dataset for experiments, we demonstrate that Mel-RoFormer outperforms BS-RoFormer in the separation tasks of vocals, drums, and other stems.
Scaling Up Music Information Retrieval Training with Semi-Supervised Learning
Oct 02, 2023In the era of data-driven Music Information Retrieval (MIR), the scarcity of labeled data has been one of the major concerns to the success of an MIR task. In this work, we leverage the semi-supervised teacher-student training approach to improve MIR tasks. For training, we scale up the unlabeled music data to 240k hours, which is much larger than any public MIR datasets. We iteratively create and refine the pseudo-labels in the noisy teacher-student training process. Knowledge expansion is also explored to iteratively scale up the model sizes from as small as less than 3M to almost 100M parameters. We study the performance correlation between data size and model size in the experiments. By scaling up both model size and training data, our models achieve state-of-the-art results on several MIR tasks compared to models that are either trained in a supervised manner or based on a self-supervised pretrained model. To our knowledge, this is the first attempt to study the effects of scaling up both model and training data for a variety of MIR tasks.
Music Source Separation with Band-Split RoPE Transformer
Sep 10, 2023Music source separation (MSS) aims to separate a music recording into multiple musically distinct stems, such as vocals, bass, drums, and more. Recently, deep learning approaches such as convolutional neural networks (CNNs) and recurrent neural networks (RNNs) have been used, but the improvement is still limited. In this paper, we propose a novel frequency-domain approach based on a Band-Split RoPE Transformer (called BS-RoFormer). BS-RoFormer relies on a band-split module to project the input complex spectrogram into subband-level representations, and then arranges a stack of hierarchical Transformers to model the inner-band as well as inter-band sequences for multi-band mask estimation. To facilitate training the model for MSS, we propose to use the Rotary Position Embedding (RoPE). The BS-RoFormer system trained on MUSDB18HQ and 500 extra songs ranked the first place in the MSS track of Sound Demixing Challenge (SDX23). Benchmarking a smaller version of BS-RoFormer on MUSDB18HQ, we achieve state-of-the-art result without extra training data, with 9.80 dB of average SDR.